336 lines
14 KiB
Markdown
336 lines
14 KiB
Markdown
# Music Kraken
|
|
|
|
1. [Installlation](#installation)
|
|
2. [Command Line Usage](#quick-guide)
|
|
3. [Library Usage / Python Interface](#programming-interface--use-as-library)
|
|
4. [About Metadata](#metadata)
|
|
5. [About the Audio](#download)
|
|
6. [About the Lyrics](#lyrics)
|
|
|
|

|
|
|
|
## Installation
|
|
|
|
You can find and get this project from either [PyPI](https://pypi.org/project/music-kraken/) as Python-Package
|
|
or simply the source code from [GitHub](https://github.com/HeIIow2/music-downloader). Note that even though
|
|
everything **SHOULD** work cross Plattform, I only tested it on Ubuntu.
|
|
If you enjoy this project, feel free to give it a Star on GitHub.
|
|
|
|
```sh
|
|
# install it with
|
|
pip install music-kraken
|
|
|
|
# and simply run it like this:
|
|
music-kraken
|
|
```
|
|
|
|
### Notes for WSL
|
|
|
|
If you choose to run it in WSL, make sure ` ~/.local/bin` is added to your `$PATH` [#2][i2]
|
|
|
|
## Quick-Guide
|
|
|
|
**Genre:** First the cli asks you to input a gere you want to download to. The options it gives you (if it gives you any) are all the folders you got in the music directory. You also can just input a new one.
|
|
|
|
**What to download:** After that it prompts you for a search. Here are a couple examples how you can search:
|
|
|
|
```
|
|
> #a <any artist>
|
|
searches for the artist <any artist>
|
|
|
|
> #a <any artist> #r <any releas>
|
|
searches for the release (album) <any release> by the artist <any artist>
|
|
|
|
> #r <any release> Me #t <any track>
|
|
searches for the track <any track> from the release <any relaese>
|
|
```
|
|
|
|
After searching with this syntax it prompts you with multiple results. You can either choose one of those by inputing its id `int` or you can search for a new query.
|
|
|
|
After you chose either an artist, a release group, a release or a track by its id, download it by inputing the string `ok`. My downloader will download it automatically for you.
|
|
|
|
---
|
|
|
|
## Programming Interface / use as Library
|
|
|
|
If you want to use this project, or parts from it in your own projects from it,
|
|
make sure to be familiar with [Python Modules](https://docs.python.org/3/tutorial/modules.html).
|
|
Further and better documentation including code examples are yet to come, so here is the rough
|
|
module structure for now. (should be up-to-date but no guarantee)
|
|
|
|
If you simply want to run the builtin minimal cli just do this:
|
|
```python
|
|
from music_kraken import cli
|
|
|
|
cli()
|
|
```
|
|
|
|
### Search for Metadata
|
|
|
|
The whole programm takes the data it processes further from the cache, a sqlite database.
|
|
So before you can do anything, you will need to fill it with the songs you want to download (*or create song objects manually, but more on that later*).
|
|
|
|
For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type` the id corresponds to either
|
|
- an artist
|
|
- a release group
|
|
- a release
|
|
- a recording/track).
|
|
|
|
To get this info, you first have to initialize a search object (`music_kraken.MetadataSearch`).
|
|
|
|
```python
|
|
search_object = music_kraken.MetadataSearch()
|
|
```
|
|
|
|
Then you need an initial "text search" to get some options you can choose from. For
|
|
this you can either specify artists releases and whatever directly with one of the following functions:
|
|
|
|
```python
|
|
# you can directly specify artist, release group, release or recording/track
|
|
multiple_options = search_object.search_from_text(artist=input("input the name of the artist: "))
|
|
# you can specify a query see the simple integrated cli on how to use the query
|
|
multiple_options = search_object.search_from_query(query=input("input the query: "))
|
|
```
|
|
|
|
both possible methods return an instance of `MultipleOptions`, which can be directly converted to a string.
|
|
|
|
```python
|
|
print(multiple_options)
|
|
```
|
|
|
|
After the first "*text search*" you can either again search the same way as before,
|
|
or you can further explore one of the options from the previous search.
|
|
To explore and select one options from `MultipleOptions`, simply call `MetadataSearch.choose(self, index: int)`.
|
|
The index represents the number in the previously returned instance of MultipleOptions.
|
|
The selected Option will be selected and can be downloaded in the next step.
|
|
|
|
*Thus, this has to be done **after either search_from_text or search_from_query***
|
|
|
|
```python
|
|
# choosing the best matching band
|
|
multiple_options = search_object.choose(0)
|
|
# choosing the first ever release group of this band
|
|
multiple_options = search_object.choose(1)
|
|
# printing out the current options
|
|
print(multiple_options)
|
|
```
|
|
|
|
This process can be repeated indefinitely (until you run out of memory).
|
|
A search history is kept in the Search instance. You could go back to
|
|
the previous search (without any loading time) like this:
|
|
|
|
```python
|
|
multiple_options = search_object.get_previous_options()
|
|
```
|
|
|
|
### Downloading Metadata / Filling up the Cache
|
|
|
|
You can download following metadata:
|
|
- an artist (the whole discography)
|
|
- a release group
|
|
- a release
|
|
- a track/recording
|
|
|
|
If you got an instance of `MetadataSearch`, like I elaborated [previously](#search-for-metadata), downloading every piece of metadata from the currently selected Option is really quite easy.
|
|
|
|
```python
|
|
from music_kraken import fetch_metadata_from_search
|
|
|
|
# this is it :)
|
|
music_kraken.fetch_metadata_from_search(search_object)
|
|
```
|
|
|
|
If you already know what you want to download you can skip the search instance and simply do the following.
|
|
|
|
```python
|
|
from music_kraken import fetch_metadata
|
|
|
|
# might change and break after I add multiple metadata sources which I will
|
|
|
|
fetch_metadata(id_=musicbrainz_id, type=metadata_type)
|
|
```
|
|
The option type is a string (*I'm sorry for not making it an enum I know its a bad pratice*), which can
|
|
have following values:
|
|
- 'artist'
|
|
- 'release_group'
|
|
- 'release'
|
|
- 'recording'
|
|
|
|
**PAY ATTENTION TO TYPOS, ITS CASE SENSITIVE**
|
|
|
|
The musicbrainz id is just the id of the object from musicbrainz.
|
|
|
|
After following those steps, it might take a couple seconds/minutes to execute, but then the Cache will be filled.
|
|
|
|
|
|
### Cache / Temporary Database
|
|
|
|
All the data, the functions that download stuff use, can be gotten from the temporary database / cache.
|
|
The cache can be simply used like this:
|
|
|
|
```python
|
|
music_kraken.cache
|
|
```
|
|
|
|
When fetching any song data from the cache, you will get it as Song
|
|
object (music_kraken.Song). There are multiple methods
|
|
to get different sets of Songs. The names explain the methods pretty
|
|
well:
|
|
|
|
```python
|
|
from music_kraken import cache
|
|
|
|
# gets a single track specified by the id
|
|
cache.get_track_metadata(id: str)
|
|
|
|
# gets a list of tracks.
|
|
cache.get_tracks_to_download()
|
|
cache.get_tracks_without_src()
|
|
cache.get_tracks_without_isrc()
|
|
cache.get_tracks_without_filepath()
|
|
```
|
|
|
|
the id always is a musicbrainz id and distinct for every track.
|
|
|
|
### Setting the Target
|
|
|
|
By default the music downloader doesn't know where to save the music file, if downloaded. To set those variables (the directory to save the file in and the filepath), it is enough to run one single command:
|
|
|
|
```python
|
|
from music_kraken import set_target
|
|
|
|
# adds file path, file directory and the genre to the database
|
|
set_target(genre="some test genre")
|
|
```
|
|
|
|
The concept of genres is too loose, to definitly say, this band exclusively plays this genre, or this song is this genre. This doesn't work manually, this will never work automatically. Thus I've decided to just use the genre as category, to sort the artists and songs by. Most Music players support that.
|
|
|
|
As a result of this decision you will have to pass the genre in this function.
|
|
|
|
### Get Audio
|
|
|
|
This is most likely the most usefull and unique feature of this Project. If the cache is filled you can get audio sources for the songs you only have the metadata, and download them. This works for most songs. I'd guess for about 97% (?)
|
|
|
|
First of you will need a List of song objects `music_kraken.Song`. As [mentioned above](#cache--temporary-database), you could get a list like that from the cache.
|
|
|
|
```python
|
|
# Here is an Example
|
|
from music_kraken import (
|
|
cache,
|
|
fetch_sources,
|
|
fetch_audios
|
|
)
|
|
|
|
# scanning pages, searching for a download and storing results
|
|
fetch_sources(cache.get_tracks_without_src())
|
|
|
|
# downloading all previously fetched sources to previously defined targets
|
|
fetch_audios(cache.get_tracks_to_download())
|
|
|
|
```
|
|
|
|
*Note:*
|
|
To download audio two cases have to be met:
|
|
1. [The target](#setting-the-target) has to be set beforehand
|
|
2. The sources have to be fetched beforehand
|
|
|
|
---
|
|
|
|
## Metadata
|
|
|
|
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz][mb]. This is a result of them being a website with a large Database spanning over all Genres.
|
|
|
|
### Musicbrainz
|
|
|
|
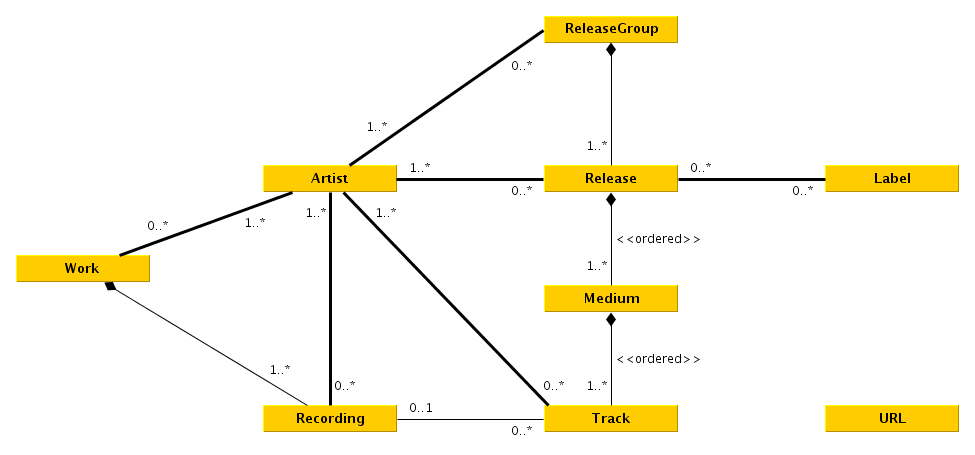
|
|
|
|
To fetch from [Musicbrainz][mb] we first have to know what to fetch. A good start is to get an input querry, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
|
|
|
If the following chosen element is an artist, its discography + a couple tracks are printed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
|
|
|
Up to now it doesn't if the discography or tracklist is chosen.
|
|
|
|
### Metadata to fetch
|
|
|
|
I orient on which metadata to download on the keys in `mutagen.EasyID3` . Following I fetch and thus tag the MP3 with:
|
|
- title
|
|
- artist
|
|
- albumartist
|
|
- tracknumber
|
|
- albumsort can sort albums cronological
|
|
- titlesort is just set to the tracknumber to sort by track order to sort correctly
|
|
- isrc
|
|
- musicbrainz_artistid
|
|
- musicbrainz_albumid
|
|
- musicbrainz_albumartistid
|
|
- musicbrainz_albumstatus
|
|
- language
|
|
- musicbrainz_albumtype
|
|
- releasecountry
|
|
- barcode
|
|
|
|
#### albumsort/titlesort
|
|
|
|
Those Tags are for the musicplayer to not sort for Example the albums of a band alphabetically, but in another way. I set it just to chronological order
|
|
|
|
#### isrc
|
|
|
|
This is the **international standart release code**. With this a track can be identified 99% of the time, if it is known and the website has a search api for that. Obviously this will get important later.
|
|
|
|
## Download
|
|
|
|
Now that the metadata is downloaded and cached, download sources need to be sound, because one can't listen to metadata. Granted it would be amazing if that would be possible.
|
|
|
|
### Musify
|
|
|
|
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). Its a russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search suff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottleneck defently is not at the speed of those requests.
|
|
|
|
For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
|
|
|
|
```json
|
|
[
|
|
{
|
|
"id":"Lorna Shore",
|
|
"label":"Lorna Shore",
|
|
"value":"Lorna Shore",
|
|
"category":"Исполнители",
|
|
"image":"https://39s.musify.club/img/68/9561484/25159224.jpg",
|
|
"url":"/artist/lorna-shore-59611"
|
|
},
|
|
{"id":"Immortal","label":"Lorna Shore - Immortal (2020)","value":"Immortal","category":"Релизы","image":"https://39s-a.musify.club/img/70/20335517/52174338.jpg","url":"/release/lorna-shore-immortal-2020-1241300"},
|
|
{"id":"Immortal","label":"Lorna Shore - Immortal","value":"Immortal","category":"Треки","image":"","url":"/track/lorna-shore-immortal-12475071"}
|
|
]
|
|
```
|
|
|
|
This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
|
|
|
|
- call the api with the query being the track name
|
|
- parse the json response to an object
|
|
- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
|
|
- If they match get the download links and cache them.
|
|
|
|
### Youtube
|
|
|
|
Herte the **isrc** plays a huge role. You probably know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
|
|
|
|
Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
|
|
|
|
For searching, as well as for downloading I use the programm `youtube-dl`, which also has a programming interface for python.
|
|
|
|
There are two bottlenecks with this approach though:
|
|
1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
|
|
2. Ofthen musicbrainz just doesn't give the isrc for some songs.
|
|
|
|
|
|
## Lyrics
|
|
|
|
To get the Lyrics, I scrape them, and put those in the USLT ID3 Tags of for example mp3 files. Unfortunately some players, like the one I use, Rhythmbox don't support USLT Lyrics. So I created an Plugin for Rhythmbox. You can find it here: [https://github.com/HeIIow2/rythmbox-id3-lyrics-support](https://github.com/HeIIow2/rythmbox-id3-lyrics-support).
|
|
|
|
### Genius
|
|
|
|
For the lyrics source the page [https://genius.com/](https://genius.com/) is easily sufficient. It has most songs. Some songs are not present though, but that is fine, because the lyrics are optional anyways.
|
|
|
|
|
|
[i2]: https://github.com/HeIIow2/music-downloader/issues/2
|
|
[mb]: https://musicbrainz.org/
|