|
|
|
@@ -1,6 +1,6 @@
|
|
|
|
|
Metadata-Version: 2.1
|
|
|
|
|
Name: music-kraken
|
|
|
|
|
Version: 1.2.0
|
|
|
|
|
Version: 1.2.1
|
|
|
|
|
Summary: An extensive music downloader crawling the internet. It gets its metadata from a couple metadata provider, and it scrapes the audiofiles.
|
|
|
|
|
Home-page: https://github.com/HeIIow2/music-downloader
|
|
|
|
|
Author: Hellow2
|
|
|
|
@@ -14,6 +14,13 @@ License-File: LICENSE
|
|
|
|
|
|
|
|
|
|
# Music Kraken
|
|
|
|
|
|
|
|
|
|
1. [Installlation](#installation)
|
|
|
|
|
2. [Command Line Usage](#quick-guide)
|
|
|
|
|
3. [Library Usage / Python Interface](#programming-interface--use-as-library)
|
|
|
|
|
4. [About Metadata](#metadata)
|
|
|
|
|
5. [About the Audio](#download)
|
|
|
|
|
6. [About the Lyrics](#lyrics)
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
## Installation
|
|
|
|
@@ -65,26 +72,28 @@ make sure to be familiar with [Python Modules](https://docs.python.org/3/tutoria
|
|
|
|
|
Further and better documentation including code examples are yet to come, so here is the rough
|
|
|
|
|
module structure for now. (should be up-to-date but no guarantee)
|
|
|
|
|
|
|
|
|
|
Music Kraken can be imported like this:
|
|
|
|
|
If you simply want to run the builtin minimal cli just do this:
|
|
|
|
|
```python
|
|
|
|
|
import music_kraken as mk
|
|
|
|
|
```
|
|
|
|
|
from music_kraken import cli
|
|
|
|
|
|
|
|
|
|
if you simply want to run the builtin minimal cli just do this:
|
|
|
|
|
```python
|
|
|
|
|
mk.cli()
|
|
|
|
|
cli()
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
### Search for Metadata
|
|
|
|
|
|
|
|
|
|
The whole programm takes the data it processes further from the cache, a sqlite database.
|
|
|
|
|
So before you can do anything, you will need to fill it with the songs you want to download.
|
|
|
|
|
For now the base of everything is musicbrainz, so you need to get the
|
|
|
|
|
musicbrainz id and the type the id corresponds to (artist/release group/release/track).
|
|
|
|
|
To get this you first have to initialize a search object (`music_kraken.metadata.metadata_search.Search`).
|
|
|
|
|
So before you can do anything, you will need to fill it with the songs you want to download (*or create song objects manually, but more on that later*).
|
|
|
|
|
|
|
|
|
|
For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type` the id corresponds to either
|
|
|
|
|
- an artist
|
|
|
|
|
- a release group
|
|
|
|
|
- a release
|
|
|
|
|
- a recording/track).
|
|
|
|
|
|
|
|
|
|
To get this info, you first have to initialize a search object (`music_kraken.MetadataSearch`).
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
search_object = mk.metadata.metadata_search.Search()
|
|
|
|
|
search_object = music_kraken.MetadataSearch()
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
Then you need an initial "text search" to get some options you can choose from. For
|
|
|
|
@@ -105,7 +114,7 @@ print(multiple_options)
|
|
|
|
|
|
|
|
|
|
After the first "*text search*" you can either again search the same way as before,
|
|
|
|
|
or you can further explore one of the options from the previous search.
|
|
|
|
|
To explore and select one options from `MultipleOptions`, simply call `Search.choose(self, index: int)`.
|
|
|
|
|
To explore and select one options from `MultipleOptions`, simply call `MetadataSearch.choose(self, index: int)`.
|
|
|
|
|
The index represents the number in the previously returned instance of MultipleOptions.
|
|
|
|
|
The selected Option will be selected and can be downloaded in the next step.
|
|
|
|
|
|
|
|
|
@@ -125,78 +134,66 @@ A search history is kept in the Search instance. You could go back to
|
|
|
|
|
the previous search (without any loading time) like this:
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
multiple_options = search.get_previous_options()
|
|
|
|
|
multiple_options = search_object.get_previous_options()
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
### Downloading Metadata / Filling up the Cache
|
|
|
|
|
|
|
|
|
|
If you selected the Option you want with `Search.choose(i)`, you can
|
|
|
|
|
finally download the metadata of either:
|
|
|
|
|
You can download following metadata:
|
|
|
|
|
- an artist (the whole discography)
|
|
|
|
|
- a release group
|
|
|
|
|
- a release
|
|
|
|
|
- a track/recording
|
|
|
|
|
To download you need the selected Option Object (`music_kraken.metadata.metadata_search.Option`)
|
|
|
|
|
it is simply stored in `Search.current_option`.
|
|
|
|
|
|
|
|
|
|
If you already know what you want to download you can skip all the steps above and just create
|
|
|
|
|
a dictionary like this and use it later (*might change and break after I add multiple metadata sources which I will*):
|
|
|
|
|
If you got an instance of `MetadataSearch`, like I elaborated [previously](#search-for-metadata), downloading every piece of metadata from the currently selected Option is really quite easy.
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
download_dict = {
|
|
|
|
|
'type': option_type,
|
|
|
|
|
'id': musicbrainz_id
|
|
|
|
|
}
|
|
|
|
|
from music_kraken import fetch_metadata_from_search
|
|
|
|
|
|
|
|
|
|
# this is it :)
|
|
|
|
|
music_kraken.fetch_metadata_from_search(search_object)
|
|
|
|
|
```
|
|
|
|
|
The option type is a string (I'm sorry for not making it an enum I know its a bad pratice), which can
|
|
|
|
|
|
|
|
|
|
If you already know what you want to download you can skip the search instance and simply do the following.
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
from music_kraken import fetch_metadata
|
|
|
|
|
|
|
|
|
|
# might change and break after I add multiple metadata sources which I will
|
|
|
|
|
|
|
|
|
|
fetch_metadata(id_=musicbrainz_id, type=metadata_type)
|
|
|
|
|
```
|
|
|
|
|
The option type is a string (*I'm sorry for not making it an enum I know its a bad pratice*), which can
|
|
|
|
|
have following values:
|
|
|
|
|
- 'artist'
|
|
|
|
|
- 'release_group'
|
|
|
|
|
- 'release'
|
|
|
|
|
- 'recording'
|
|
|
|
|
-
|
|
|
|
|
|
|
|
|
|
**PAY ATTENTION TO TYPOS, ITS CASE SENSITIVE**
|
|
|
|
|
|
|
|
|
|
The musicbrainz id is just the id of the object from musicbrainz.
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
# in this example I will choose the previous selected option.
|
|
|
|
|
option_to_download = search_object.current_option
|
|
|
|
|
print(option_to_download)
|
|
|
|
|
|
|
|
|
|
download_dict = {
|
|
|
|
|
'type': option_to_download.type,
|
|
|
|
|
'id': option_to_download.id
|
|
|
|
|
}
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
If you got the Option instance you want to download and created the dictionary, then downloading the metadata is really straight
|
|
|
|
|
forward, so I just show the code.
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
# I am aware of abstrackt classes
|
|
|
|
|
metadata_downloader = mk.metadata.metadata_fetch.MetadataDownloader()
|
|
|
|
|
metadata_downloader.download(download_dict)
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
After following those steps, it might take a couple seconds/minutes to execute, but then the Cache will be filled.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### Cache / Temporary Database
|
|
|
|
|
|
|
|
|
|
All the data, the functions that download stuff use, can be gotten from the temporary database / cache.
|
|
|
|
|
You can get the database object like this:
|
|
|
|
|
The cache can be simply used like this:
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
cache = mk.database.temp_database.temp_database
|
|
|
|
|
print(cache)
|
|
|
|
|
music_kraken.cache
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
When fetching any song data from the cache, you will get it as Song
|
|
|
|
|
object (music_kraken.database.song.Song). There are multiple methods
|
|
|
|
|
object (music_kraken.Song). There are multiple methods
|
|
|
|
|
to get different sets of Songs. The names explain the methods pretty
|
|
|
|
|
well:
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
from music_kraken import cache
|
|
|
|
|
|
|
|
|
|
# gets a single track specified by the id
|
|
|
|
|
cache.get_track_metadata(id: str)
|
|
|
|
|
|
|
|
|
@@ -214,47 +211,54 @@ the id always is a musicbrainz id and distinct for every track.
|
|
|
|
|
By default the music downloader doesn't know where to save the music file, if downloaded. To set those variables (the directory to save the file in and the filepath), it is enough to run one single command:
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
from music_kraken import set_target
|
|
|
|
|
|
|
|
|
|
# adds file path, file directory and the genre to the database
|
|
|
|
|
mk.target.set_target.UrlPath(genre="some test genre")
|
|
|
|
|
set_target(genre="some test genre")
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
The concept of genres is too loose, to definitly say, this band exclusively plays this genre, or this song is this genre. This doesn't work manually, this will never work automatically. Thus I've decided to just use the genre as category, to sort the artists and songs by. Most Music players support that.
|
|
|
|
|
|
|
|
|
|
As a result of this decision you will have to pass the genre in this function (*actually its a class but it doesn't make any difference*).
|
|
|
|
|
As a result of this decision you will have to pass the genre in this function.
|
|
|
|
|
|
|
|
|
|
### Get the Download Links / Audio Sources
|
|
|
|
|
### Get Audio
|
|
|
|
|
|
|
|
|
|
This is most likely the most usefull and unique feature of this Project. If the cache is filled you can get audio sources for the songs you only have the metadata. This works for most songs. I'd guess for about 97% (?)
|
|
|
|
|
This is most likely the most usefull and unique feature of this Project. If the cache is filled you can get audio sources for the songs you only have the metadata, and download them. This works for most songs. I'd guess for about 97% (?)
|
|
|
|
|
|
|
|
|
|
First of you will need a List of song objects `music_kraken.Song`. As [mentioned above](#cache--temporary-database), you could get a list like that from the cache.
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
# this is how you do it.
|
|
|
|
|
mk.audio_source.fetch_source.Download()
|
|
|
|
|
# Here is an Example
|
|
|
|
|
from music_kraken import (
|
|
|
|
|
cache,
|
|
|
|
|
fetch_sources,
|
|
|
|
|
fetch_audios
|
|
|
|
|
)
|
|
|
|
|
|
|
|
|
|
# scanning pages, searching for a download and storing results
|
|
|
|
|
fetch_sources(cache.get_tracks_without_src())
|
|
|
|
|
|
|
|
|
|
# downloading all previously fetched sources to previously defined targets
|
|
|
|
|
fetch_audios(cache.get_tracks_to_download())
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
Now the audio sources are int the cache, and you can get them as mentioned above (`Song.sources: List[Source]`).
|
|
|
|
|
|
|
|
|
|
### Downloading the Audio
|
|
|
|
|
|
|
|
|
|
If the target paths fields and audio sources are set in the database field, then the audio files can just be downloaded and automatically tagged like this:
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
mk.audio_source.fetch_audio.Download()
|
|
|
|
|
|
|
|
|
|
# after that the lyrics can be added
|
|
|
|
|
mk.lyrics.lyrics.fetch_lyrics()
|
|
|
|
|
```
|
|
|
|
|
*Note:*
|
|
|
|
|
To download audio two cases have to be met:
|
|
|
|
|
1. [The target](#setting-the-target) has to be set beforehand
|
|
|
|
|
2. The sources have to be fetched beforehand
|
|
|
|
|
|
|
|
|
|
---
|
|
|
|
|
|
|
|
|
|
## Metadata
|
|
|
|
|
|
|
|
|
|
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz](musicbrainz.org/). This is a result of them being a website with a large Database spanning over all Genres.
|
|
|
|
|
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz][mb]. This is a result of them being a website with a large Database spanning over all Genres.
|
|
|
|
|
|
|
|
|
|
### Musicbrainz
|
|
|
|
|
|
|
|
|
|
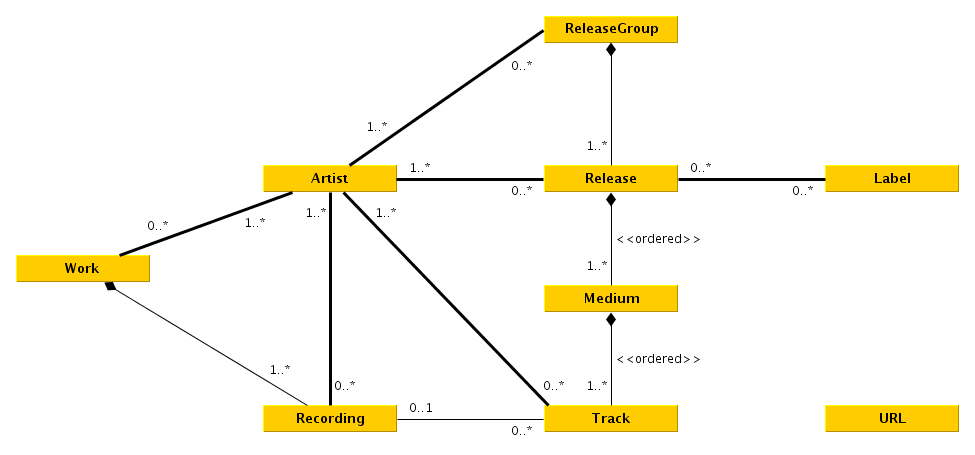
|
|
|
|
|
|
|
|
|
|
To fetch from [Musicbrainz](musicbrainz.org/) we first have to know what to fetch. A good start is to get an input querry, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
|
|
|
|
To fetch from [Musicbrainz][mb] we first have to know what to fetch. A good start is to get an input querry, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
|
|
|
|
|
|
|
|
|
If the following chosen element is an artist, its discography + a couple tracks are printed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
|
|
|
|
|
|
|
|
@@ -342,3 +346,4 @@ For the lyrics source the page [https://genius.com/](https://genius.com/) is eas
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[i2]: https://github.com/HeIIow2/music-downloader/issues/2
|
|
|
|
|
[mb]: musicbrainz.org/
|
|
|
|
|