restructured slightly and addet skript to upload to PyPI
This commit is contained in:
@@ -0,0 +1,110 @@
|
||||
from .utils.shared import *
|
||||
|
||||
from .metadata.download import MetadataDownloader
|
||||
from .metadata import download
|
||||
from .metadata import search as s
|
||||
from . import download_links
|
||||
from . import url_to_path
|
||||
from . import download
|
||||
|
||||
# NEEDS REFACTORING
|
||||
from .lyrics.lyrics import fetch_lyrics
|
||||
|
||||
import logging
|
||||
import os
|
||||
|
||||
# configure logger default
|
||||
logging.basicConfig(
|
||||
level=logging.INFO,
|
||||
format="%(asctime)s [%(levelname)s] %(message)s",
|
||||
handlers=[
|
||||
logging.FileHandler(os.path.join(temp_dir, LOG_FILE)),
|
||||
logging.StreamHandler()
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def get_existing_genre():
|
||||
valid_directories = []
|
||||
for elem in os.listdir(MUSIC_DIR):
|
||||
if elem not in NOT_A_GENRE:
|
||||
valid_directories.append(elem)
|
||||
|
||||
return valid_directories
|
||||
|
||||
|
||||
def search_for_metadata():
|
||||
search = s.Search()
|
||||
|
||||
while True:
|
||||
input_ = input(
|
||||
"q to quit, .. for previous options, int for this element, str to search for query, ok to download\n")
|
||||
input_.strip()
|
||||
if input_.lower() == "ok":
|
||||
break
|
||||
if input_.lower() == "q":
|
||||
break
|
||||
if input_.lower() == "..":
|
||||
print()
|
||||
print(search.get_previous_options())
|
||||
continue
|
||||
if input_.isdigit():
|
||||
print()
|
||||
print(search.choose(int(input_)))
|
||||
continue
|
||||
print()
|
||||
print(search.search_from_query(input_))
|
||||
|
||||
print(search.current_option)
|
||||
return search.current_option
|
||||
|
||||
|
||||
def get_genre():
|
||||
existing_genres = get_existing_genre()
|
||||
print("printing available genres:")
|
||||
for i, genre_option in enumerate(existing_genres):
|
||||
print(f"{i}: {genre_option}")
|
||||
|
||||
genre = input("Input the ID for an existing genre or text for a new one: ")
|
||||
|
||||
if genre.isdigit():
|
||||
genre_id = int(genre)
|
||||
if genre_id >= len(existing_genres):
|
||||
logging.warning("An invalid genre id has been given")
|
||||
return get_genre()
|
||||
return existing_genres[genre_id]
|
||||
|
||||
return genre
|
||||
|
||||
|
||||
def cli(start_at: int = 0, only_lyrics: bool = False):
|
||||
if start_at <= 2 and not only_lyrics:
|
||||
genre = get_genre()
|
||||
logging.info(f"{genre} has been set as genre.")
|
||||
|
||||
if start_at <= 0:
|
||||
search = search_for_metadata()
|
||||
# search = metadata.search.Option("release", "f8d4b24d-2c46-4e9c-8078-0c0f337c84dd", "Beautyfall")
|
||||
logging.info("Starting Downloading of metadata")
|
||||
metadata_downloader = MetadataDownloader()
|
||||
metadata_downloader.download({'type': search.type, 'id': search.id})
|
||||
|
||||
if start_at <= 1 and not only_lyrics:
|
||||
logging.info("creating Paths")
|
||||
url_to_path.UrlPath(genre=genre)
|
||||
|
||||
if start_at <= 2 and not only_lyrics:
|
||||
logging.info("Fetching Download Links")
|
||||
download_links.Download()
|
||||
|
||||
if start_at <= 3 and not only_lyrics:
|
||||
logging.info("starting to download the mp3's")
|
||||
download.Download()
|
||||
|
||||
if start_at <= 4:
|
||||
logging.info("starting to fetch the lyrics")
|
||||
fetch_lyrics()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
cli(start_at=0, only_lyrics=False)
|
||||
@@ -0,0 +1,3 @@
|
||||
class Song:
|
||||
def __init__(self, path: str):
|
||||
pass
|
||||
@@ -0,0 +1,84 @@
|
||||
import mutagen.id3
|
||||
import requests
|
||||
import os.path
|
||||
from mutagen.easyid3 import EasyID3
|
||||
from pydub import AudioSegment
|
||||
|
||||
from .utils.shared import *
|
||||
from .scraping import musify, youtube_music
|
||||
|
||||
"""
|
||||
https://en.wikipedia.org/wiki/ID3
|
||||
https://mutagen.readthedocs.io/en/latest/user/id3.html
|
||||
|
||||
# to get all valid keys
|
||||
from mutagen.easyid3 import EasyID3
|
||||
print("\n".join(EasyID3.valid_keys.keys()))
|
||||
print(EasyID3.valid_keys.keys())
|
||||
"""
|
||||
|
||||
logger = DOWNLOAD_LOGGER
|
||||
|
||||
|
||||
class Download:
|
||||
def __init__(self):
|
||||
for row in database.get_tracks_to_download():
|
||||
row['artist'] = [i['name'] for i in row['artists']]
|
||||
row['file'] = os.path.join(MUSIC_DIR, row['file'])
|
||||
row['path'] = os.path.join(MUSIC_DIR, row['path'])
|
||||
|
||||
if self.path_stuff(row['path'], row['file']):
|
||||
self.write_metadata(row, row['file'])
|
||||
continue
|
||||
|
||||
download_success = None
|
||||
src = row['src']
|
||||
if src == 'musify':
|
||||
download_success = musify.download(row)
|
||||
elif src == 'youtube':
|
||||
download_success = youtube_music.download(row)
|
||||
|
||||
if download_success == -1:
|
||||
logger.warning(f"couldn't download {row['url']} from {row['src']}")
|
||||
continue
|
||||
|
||||
self.write_metadata(row, row['file'])
|
||||
|
||||
@staticmethod
|
||||
def write_metadata(row, file_path):
|
||||
if not os.path.exists(file_path):
|
||||
logger.warning("something went really wrong")
|
||||
return False
|
||||
|
||||
# only convert the file to the proper format if mutagen doesn't work with it due to time
|
||||
try:
|
||||
audiofile = EasyID3(file_path)
|
||||
except mutagen.id3.ID3NoHeaderError:
|
||||
AudioSegment.from_file(file_path).export(file_path, format="mp3")
|
||||
audiofile = EasyID3(file_path)
|
||||
|
||||
valid_keys = list(EasyID3.valid_keys.keys())
|
||||
|
||||
for key in list(row.keys()):
|
||||
if key in valid_keys and row[key] is not None:
|
||||
if type(row[key]) != list:
|
||||
row[key] = str(row[key])
|
||||
audiofile[key] = row[key]
|
||||
|
||||
logger.info("saving")
|
||||
audiofile.save(file_path, v1=2)
|
||||
|
||||
@staticmethod
|
||||
def path_stuff(path: str, file_: str):
|
||||
# returns true if it shouldn't be downloaded
|
||||
if os.path.exists(file_):
|
||||
logger.info(f"'{file_}' does already exist, thus not downloading.")
|
||||
return True
|
||||
os.makedirs(path, exist_ok=True)
|
||||
return False
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
s = requests.Session()
|
||||
Download()
|
||||
@@ -0,0 +1,55 @@
|
||||
import requests
|
||||
|
||||
from .utils.shared import *
|
||||
from .scraping import musify, youtube_music, file_system
|
||||
|
||||
logger = URL_DOWNLOAD_LOGGER
|
||||
|
||||
|
||||
class Download:
|
||||
def __init__(self) -> None:
|
||||
self.urls = []
|
||||
|
||||
for row in database.get_tracks_without_src():
|
||||
row['artists'] = [artist['name'] for artist in row['artists']]
|
||||
|
||||
id_ = row['id']
|
||||
if os.path.exists(os.path.join(MUSIC_DIR, row['file'])):
|
||||
logger.info(f"skipping the fetching of the download links, cuz {row['file']} already exists.")
|
||||
continue
|
||||
|
||||
"""
|
||||
not implemented yet, will in one point crashe everything
|
||||
# check File System
|
||||
file_path = file_system.get_path(row)
|
||||
if file_path is not None:
|
||||
self.add_url(file_path, 'file', id_)
|
||||
continue
|
||||
"""
|
||||
|
||||
# check YouTube
|
||||
youtube_url = youtube_music.get_youtube_url(row)
|
||||
if youtube_url is not None:
|
||||
self.add_url(youtube_url, 'youtube', id_)
|
||||
continue
|
||||
|
||||
# check musify
|
||||
musify_url = musify.get_musify_url(row)
|
||||
if musify_url is not None:
|
||||
self.add_url(musify_url, 'musify', id_)
|
||||
continue
|
||||
|
||||
# check musify again, but with a different methode that takes longer
|
||||
musify_url = musify.get_musify_url_slow(row)
|
||||
if musify_url is not None:
|
||||
self.add_url(musify_url, 'musify', id_)
|
||||
continue
|
||||
|
||||
logger.warning(f"Didn't find any sources for {row['title']}")
|
||||
|
||||
def add_url(self, url: str, src: str, id_: str):
|
||||
database.set_download_data(id_, url, src)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
download = Download()
|
||||
@@ -0,0 +1,171 @@
|
||||
import requests
|
||||
from typing import List
|
||||
from bs4 import BeautifulSoup
|
||||
import pycountry
|
||||
|
||||
from ..utils.shared import *
|
||||
from ..utils import phonetic_compares
|
||||
from ..utils.object_handeling import get_elem_from_obj
|
||||
|
||||
# search doesn't support isrc
|
||||
# https://genius.com/api/search/multi?q=I Prevail - Breaking Down
|
||||
# https://genius.com/api/songs/6192944
|
||||
# https://docs.genius.com/
|
||||
|
||||
session = requests.Session()
|
||||
session.headers = {
|
||||
"Connection": "keep-alive",
|
||||
"Referer": "https://genius.com/search/embed"
|
||||
}
|
||||
session.proxies = proxies
|
||||
|
||||
logger = GENIUS_LOGGER
|
||||
|
||||
|
||||
class Song:
|
||||
def __init__(self, raw_data: dict, desirered_data: dict):
|
||||
self.raw_data = raw_data
|
||||
self.desired_data = desirered_data
|
||||
|
||||
song_data = get_elem_from_obj(self.raw_data, ['result'], return_if_none={})
|
||||
self.id = get_elem_from_obj(song_data, ['id'])
|
||||
self.artist = get_elem_from_obj(song_data, ['primary_artist', 'name'])
|
||||
self.title = get_elem_from_obj(song_data, ['title'])
|
||||
|
||||
lang_code = get_elem_from_obj(song_data, ['language']) or "en"
|
||||
self.language = pycountry.languages.get(alpha_2=lang_code)
|
||||
self.lang = self.language.alpha_3
|
||||
self.url = get_elem_from_obj(song_data, ['url'])
|
||||
|
||||
# maybe could be implemented
|
||||
self.lyricist: str
|
||||
|
||||
if get_elem_from_obj(song_data, ['lyrics_state']) != "complete":
|
||||
logger.warning(
|
||||
f"lyrics state of {self.title} by {self.artist} is not complete but {get_elem_from_obj(song_data, ['lyrics_state'])}")
|
||||
|
||||
self.valid = self.is_valid()
|
||||
if self.valid:
|
||||
logger.info(f"found lyrics for \"{self.__repr__()}\"")
|
||||
else:
|
||||
return
|
||||
|
||||
self.lyrics = self.fetch_lyrics()
|
||||
if self.lyrics is None:
|
||||
self.valid = False
|
||||
|
||||
def is_valid(self) -> bool:
|
||||
title_match, title_distance = phonetic_compares.match_titles(self.title, self.desired_data['track'])
|
||||
artist_match, artist_distance = phonetic_compares.match_artists(self.desired_data['artist'], self.artist)
|
||||
|
||||
return not title_match and not artist_match
|
||||
|
||||
def __repr__(self) -> str:
|
||||
return f"{self.title} by {self.artist} ({self.url})"
|
||||
|
||||
def fetch_lyrics(self) -> str | None:
|
||||
if not self.valid:
|
||||
logger.warning(f"{self.__repr__()} is invalid but the lyrics still get fetched. Something could be wrong.")
|
||||
|
||||
r = session.get(self.url)
|
||||
if r.status_code != 200:
|
||||
logging.warning(f"{r.url} returned {r.status_code}:\n{r.content}")
|
||||
return None
|
||||
|
||||
soup = BeautifulSoup(r.content, "html.parser")
|
||||
lyrics_soups = soup.find_all('div', {'data-lyrics-container': "true"})
|
||||
if len(lyrics_soups) == 0:
|
||||
logger.warning(f"didn't found lyrics on {self.url}")
|
||||
return None
|
||||
if len(lyrics_soups) != 1:
|
||||
logger.warning(f"number of lyrics_soups doesn't equals 1, but {len(lyrics_soups)} on {self.url}")
|
||||
|
||||
lyrics = "\n".join([lyrics_soup.getText(separator="\n", strip=True) for lyrics_soup in lyrics_soups])
|
||||
print(lyrics)
|
||||
|
||||
# <div data-lyrics-container="true" class="Lyrics__Container-sc-1ynbvzw-6 YYrds">With the soundle
|
||||
self.lyrics = lyrics
|
||||
return lyrics
|
||||
|
||||
|
||||
def process_multiple_songs(song_datas: list, desired_data: dict) -> List[Song]:
|
||||
all_songs = [Song(song_data, desired_data) for song_data in song_datas]
|
||||
return all_songs
|
||||
|
||||
|
||||
def search_song_list(artist: str, track: str) -> List[Song]:
|
||||
endpoint = "https://genius.com/api/search/multi?q="
|
||||
url = f"{endpoint}{artist} - {track}"
|
||||
logging.info(f"requesting {url}")
|
||||
|
||||
desired_data = {
|
||||
'artist': artist,
|
||||
'track': track
|
||||
}
|
||||
|
||||
r = session.get(url)
|
||||
if r.status_code != 200:
|
||||
logging.warning(f"{r.url} returned {r.status_code}:\n{r.content}")
|
||||
return []
|
||||
content = r.json()
|
||||
if get_elem_from_obj(content, ['meta', 'status']) != 200:
|
||||
logging.warning(f"{r.url} returned {get_elem_from_obj(content, ['meta', 'status'])}:\n{content}")
|
||||
return []
|
||||
|
||||
sections = get_elem_from_obj(content, ['response', 'sections'])
|
||||
for section in sections:
|
||||
section_type = get_elem_from_obj(section, ['type'])
|
||||
if section_type == "song":
|
||||
return process_multiple_songs(get_elem_from_obj(section, ['hits'], return_if_none=[]), desired_data)
|
||||
|
||||
return []
|
||||
|
||||
|
||||
def search(artist: str, track: str) -> list:
|
||||
results = []
|
||||
r = search_song_list(artist, track)
|
||||
for r_ in r:
|
||||
if r_.valid:
|
||||
results.append(r_)
|
||||
return results
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
|
||||
"""
|
||||
song = Song(
|
||||
{'highlights': [], 'index': 'song', 'type': 'song',
|
||||
'result': {'_type': 'song', 'annotation_count': 0, 'api_path': '/songs/6142483',
|
||||
'artist_names': 'Psychonaut 4',
|
||||
'full_title': 'Sana Sana Sana, Cura Cura Cura by\xa0Psychonaut\xa04',
|
||||
'header_image_thumbnail_url': 'https://images.genius.com/f9f67a3f9c801f697fbaf68c7efd3599.300x300x1.jpg',
|
||||
'header_image_url': 'https://images.genius.com/f9f67a3f9c801f697fbaf68c7efd3599.651x651x1.jpg',
|
||||
'id': 6142483, 'instrumental': False, 'language': 'en', 'lyrics_owner_id': 4443216,
|
||||
'lyrics_state': 'complete', 'lyrics_updated_at': 1604698709,
|
||||
'path': '/Psychonaut-4-sana-sana-sana-cura-cura-cura-lyrics', 'pyongs_count': None,
|
||||
'relationships_index_url': 'https://genius.com/Psychonaut-4-sana-sana-sana-cura-cura-cura-sample',
|
||||
'release_date_components': {'year': 2020, 'month': 7, 'day': 1},
|
||||
'release_date_for_display': 'July 1, 2020',
|
||||
'release_date_with_abbreviated_month_for_display': 'Jul. 1, 2020',
|
||||
'song_art_image_thumbnail_url': 'https://images.genius.com/f9f67a3f9c801f697fbaf68c7efd3599.300x300x1.jpg',
|
||||
'song_art_image_url': 'https://images.genius.com/f9f67a3f9c801f697fbaf68c7efd3599.651x651x1.jpg',
|
||||
'stats': {'unreviewed_annotations': 0, 'hot': False}, 'title': 'Sana Sana Sana, Cura Cura Cura',
|
||||
'title_with_featured': 'Sana Sana Sana, Cura Cura Cura', 'updated_by_human_at': 1647353214,
|
||||
'url': 'https://genius.com/Psychonaut-4-sana-sana-sana-cura-cura-cura-lyrics',
|
||||
'featured_artists': [], 'primary_artist': {'_type': 'artist', 'api_path': '/artists/1108956',
|
||||
'header_image_url': 'https://images.genius.com/ff13efc74a043237cfca3fc0a6cb12dd.1000x563x1.jpg',
|
||||
'id': 1108956,
|
||||
'image_url': 'https://images.genius.com/25ff7cfdcb6d92a9f19ebe394a895736.640x640x1.jpg',
|
||||
'index_character': 'p', 'is_meme_verified': False,
|
||||
'is_verified': False, 'name': 'Psychonaut 4',
|
||||
'slug': 'Psychonaut-4',
|
||||
'url': 'https://genius.com/artists/Psychonaut-4'}}},
|
||||
{'artist': 'Psychonaut 4', 'track': 'Sana Sana Sana, Cura Cura Cura'}
|
||||
)
|
||||
print(song.fetch_lyrics())
|
||||
"""
|
||||
|
||||
songs = search("Zombiez", "WALL OF Z")
|
||||
for song in songs:
|
||||
print(song)
|
||||
@@ -0,0 +1,94 @@
|
||||
import mutagen
|
||||
from mutagen.id3 import ID3, USLT
|
||||
|
||||
|
||||
from ..metadata import database as db
|
||||
from ..utils.shared import *
|
||||
from . import genius
|
||||
|
||||
logger = LYRICS_LOGGER
|
||||
|
||||
"""
|
||||
This whole Part is bodgy as hell and I need to rewrite this little file urgently. genius.py is really clean though :3
|
||||
Just wanted to get it to work.
|
||||
- lyrics need to be put in the database and everything should continue from there then
|
||||
"""
|
||||
|
||||
"""
|
||||
https://cweiske.de/tagebuch/rhythmbox-lyrics.htm
|
||||
Rythmbox, my music player doesn't support ID3 lyrics (USLT) yet, so I have to find something else
|
||||
Lyrics in MP3 ID3 tags (SYLT/USLT) is still missing, because GStreamer does not support that yet.
|
||||
|
||||
One possible sollution would be to use ogg/vorbis files. Those lyrics are supported in rythmbox
|
||||
'So, the next Rhythmbox release (3.5.0 or 3.4.2) will read lyrics directly from ogg/vorbis files, using the LYRICS and SYNCLYRICS tags.'
|
||||
Another possible sollution (probaply the better one cuz I dont need to refactor whole metadata AGAIN)
|
||||
would be to write a Rhythmbox plugin that fetches lyrics from ID3 USLT
|
||||
|
||||
I have written that Rhythmbox plugin: https://github.com/HeIIow2/rythmbox-id3-lyrics-support
|
||||
"""
|
||||
|
||||
|
||||
# https://www.programcreek.com/python/example/63462/mutagen.mp3.EasyMP3
|
||||
# https://code.activestate.com/recipes/577138-embed-lyrics-into-mp3-files-using-mutagen-uslt-tag/
|
||||
|
||||
|
||||
def add_lyrics(file_name, lyrics):
|
||||
file_path = os.path.join(MUSIC_DIR, file_name)
|
||||
if not os.path.exists(file_path):
|
||||
return
|
||||
|
||||
try:
|
||||
tags = ID3(file_path)
|
||||
except mutagen.id3.ID3NoHeaderError:
|
||||
return
|
||||
|
||||
logger.info(f"adding lyrics to the file {file_path}")
|
||||
|
||||
uslt_output = USLT(encoding=3, lang=lyrics.lang, desc=u'desc', text=lyrics.lyrics)
|
||||
tags["USLT::'eng'"] = uslt_output
|
||||
tags.save(file_path)
|
||||
|
||||
|
||||
def fetch_single_lyrics(row: dict):
|
||||
artists = [artist['name'] for artist in row['artists']]
|
||||
track = row['title']
|
||||
id_ = row['id']
|
||||
|
||||
logger.info(f"try fetching lyrics for \"{track}\" by \"{', '.join(artists)}")
|
||||
|
||||
lyrics = []
|
||||
for artist in artists:
|
||||
lyrics.extend(genius.search(artist, track))
|
||||
if len(lyrics) == 0:
|
||||
return
|
||||
|
||||
logger.info("found lyrics")
|
||||
database.add_lyrics(id_, lyrics=lyrics[0])
|
||||
add_lyrics(row['file'], lyrics[0])
|
||||
|
||||
|
||||
def fetch_lyrics():
|
||||
for row in database.get_tracks_for_lyrics():
|
||||
fetch_single_lyrics(row)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import tempfile
|
||||
import os
|
||||
|
||||
temp_folder = "music-downloader"
|
||||
temp_dir = os.path.join(tempfile.gettempdir(), temp_folder)
|
||||
if not os.path.exists(temp_dir):
|
||||
os.mkdir(temp_dir)
|
||||
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
db_logger = logging.getLogger("database")
|
||||
db_logger.setLevel(logging.DEBUG)
|
||||
|
||||
database = db.Database(os.path.join(temp_dir, "metadata.db"),
|
||||
os.path.join(temp_dir, "database_structure.sql"),
|
||||
"https://raw.githubusercontent.com/HeIIow2/music-downloader/new_metadata/assets/database_structure.sql",
|
||||
db_logger,
|
||||
reset_anyways=False)
|
||||
|
||||
fetch_lyrics()
|
||||
@@ -0,0 +1,266 @@
|
||||
import sqlite3
|
||||
import os
|
||||
import logging
|
||||
import json
|
||||
import requests
|
||||
|
||||
|
||||
class Database:
|
||||
def __init__(self, path_to_db: str, db_structure: str, db_structure_fallback: str, logger: logging.Logger, reset_anyways: bool = False):
|
||||
self.logger = logger
|
||||
self.path_to_db = path_to_db
|
||||
|
||||
self.connection = sqlite3.connect(self.path_to_db)
|
||||
self.cursor = self.connection.cursor()
|
||||
|
||||
# init database
|
||||
self.init_db(database_structure=db_structure, database_structure_fallback=db_structure_fallback, reset_anyways=reset_anyways)
|
||||
|
||||
def init_db(self, database_structure: str, database_structure_fallback: str, reset_anyways: bool = False):
|
||||
# check if db exists
|
||||
exists = True
|
||||
try:
|
||||
query = 'SELECT * FROM track;'
|
||||
self.cursor.execute(query)
|
||||
_ = self.cursor.fetchall()
|
||||
except sqlite3.OperationalError:
|
||||
exists = False
|
||||
|
||||
if not exists:
|
||||
self.logger.info("Database does not exist yet.")
|
||||
|
||||
if reset_anyways or not exists:
|
||||
# reset the database if reset_anyways is true or if an error has been thrown previously.
|
||||
self.logger.info("Creating/Reseting Database.")
|
||||
|
||||
if not os.path.exists(database_structure):
|
||||
self.logger.info("database structure file doesn't exist yet, fetching from github")
|
||||
r = requests.get(database_structure_fallback)
|
||||
|
||||
with open(database_structure, "w") as f:
|
||||
f.write(r.text)
|
||||
|
||||
# read the file
|
||||
with open(database_structure, "r") as database_structure_file:
|
||||
query = database_structure_file.read()
|
||||
self.cursor.executescript(query)
|
||||
self.connection.commit()
|
||||
|
||||
def add_artist(
|
||||
self,
|
||||
musicbrainz_artistid: str,
|
||||
artist: str = None
|
||||
):
|
||||
query = "INSERT OR REPLACE INTO artist (id, name) VALUES (?, ?);"
|
||||
values = musicbrainz_artistid, artist
|
||||
|
||||
self.cursor.execute(query, values)
|
||||
self.connection.commit()
|
||||
|
||||
def add_release_group(
|
||||
self,
|
||||
musicbrainz_releasegroupid: str,
|
||||
artist_ids: list,
|
||||
albumartist: str = None,
|
||||
albumsort: int = None,
|
||||
musicbrainz_albumtype: str = None,
|
||||
compilation: str = None,
|
||||
album_artist_id: str = None
|
||||
):
|
||||
# add adjacency
|
||||
adjacency_list = []
|
||||
for artist_id in artist_ids:
|
||||
adjacency_list.append((artist_id, musicbrainz_releasegroupid))
|
||||
adjacency_values = tuple(adjacency_list)
|
||||
adjacency_query = "INSERT OR REPLACE INTO artist_release_group (artist_id, release_group_id) VALUES (?, ?);"
|
||||
self.cursor.executemany(adjacency_query, adjacency_values)
|
||||
self.connection.commit()
|
||||
|
||||
# add release group
|
||||
query = "INSERT OR REPLACE INTO release_group (id, albumartist, albumsort, musicbrainz_albumtype, compilation, album_artist_id) VALUES (?, ?, ?, ?, ?, ?);"
|
||||
values = musicbrainz_releasegroupid, albumartist, albumsort, musicbrainz_albumtype, compilation, album_artist_id
|
||||
self.cursor.execute(query, values)
|
||||
self.connection.commit()
|
||||
|
||||
def add_release(
|
||||
self,
|
||||
musicbrainz_albumid: str,
|
||||
release_group_id: str,
|
||||
title: str = None,
|
||||
copyright_: str = None,
|
||||
album_status: str = None,
|
||||
language: str = None,
|
||||
year: str = None,
|
||||
date: str = None,
|
||||
country: str = None,
|
||||
barcode: str = None
|
||||
):
|
||||
query = "INSERT OR REPLACE INTO release_ (id, release_group_id, title, copyright, album_status, language, year, date, country, barcode) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?);"
|
||||
values = musicbrainz_albumid, release_group_id, title, copyright_, album_status, language, year, date, country, barcode
|
||||
|
||||
self.cursor.execute(query, values)
|
||||
self.connection.commit()
|
||||
|
||||
def add_track(
|
||||
self,
|
||||
musicbrainz_releasetrackid: str,
|
||||
musicbrainz_albumid: str,
|
||||
feature_aritsts: list,
|
||||
tracknumber: str = None,
|
||||
track: str = None,
|
||||
isrc: str = None
|
||||
):
|
||||
# add adjacency
|
||||
adjacency_list = []
|
||||
for artist_id in feature_aritsts:
|
||||
adjacency_list.append((artist_id, musicbrainz_releasetrackid))
|
||||
adjacency_values = tuple(adjacency_list)
|
||||
adjacency_query = "INSERT OR REPLACE INTO artist_track (artist_id, track_id) VALUES (?, ?);"
|
||||
self.cursor.executemany(adjacency_query, adjacency_values)
|
||||
self.connection.commit()
|
||||
|
||||
# add track
|
||||
query = "INSERT OR REPLACE INTO track (id, release_id, track, isrc, tracknumber) VALUES (?, ?, ?, ?, ?);"
|
||||
values = musicbrainz_releasetrackid, musicbrainz_albumid, track, isrc, tracknumber
|
||||
self.cursor.execute(query, values)
|
||||
self.connection.commit()
|
||||
|
||||
@staticmethod
|
||||
def get_custom_track_query(custom_where: list) -> str:
|
||||
where_args = [
|
||||
"track.release_id == release_.id",
|
||||
"release_group.id == release_.release_group_id",
|
||||
"artist_track.artist_id == artist.id",
|
||||
"artist_track.track_id == track.id"
|
||||
]
|
||||
where_args.extend(custom_where)
|
||||
|
||||
where_arg = " AND ".join(where_args)
|
||||
query = f"""
|
||||
SELECT DISTINCT
|
||||
json_object(
|
||||
'artists', json_group_array(
|
||||
(
|
||||
SELECT DISTINCT json_object(
|
||||
'id', artist.id,
|
||||
'name', artist.name
|
||||
)
|
||||
)
|
||||
),
|
||||
'id', track.id,
|
||||
'tracknumber', track.tracknumber,
|
||||
'titlesort ', track.tracknumber,
|
||||
'musicbrainz_releasetrackid', track.id,
|
||||
'musicbrainz_albumid', release_.id,
|
||||
'title', track.track,
|
||||
'isrc', track.isrc,
|
||||
'album', release_.title,
|
||||
'copyright', release_.copyright,
|
||||
'album_status', release_.album_status,
|
||||
'language', release_.language,
|
||||
'year', release_.year,
|
||||
'date', release_.date,
|
||||
'country', release_.country,
|
||||
'barcode', release_.barcode,
|
||||
'albumartist', release_group.albumartist,
|
||||
'albumsort', release_group.albumsort,
|
||||
'musicbrainz_albumtype', release_group.musicbrainz_albumtype,
|
||||
'compilation', release_group.compilation,
|
||||
'album_artist_id', release_group.album_artist_id,
|
||||
'path', track.path,
|
||||
'file', track.file,
|
||||
'genre', track.genre,
|
||||
'url', track.url,
|
||||
'src', track.src,
|
||||
'lyrics', track.lyrics
|
||||
)
|
||||
FROM track, release_, release_group,artist, artist_track
|
||||
WHERE
|
||||
{where_arg}
|
||||
GROUP BY track.id;
|
||||
"""
|
||||
return query
|
||||
|
||||
def get_custom_track(self, custom_where: list):
|
||||
query = Database.get_custom_track_query(custom_where=custom_where)
|
||||
return [json.loads(i[0]) for i in self.cursor.execute(query)]
|
||||
|
||||
def get_track_metadata(self, musicbrainz_releasetrackid: str):
|
||||
# this would be vulnerable if musicbrainz_releasetrackid would be user input
|
||||
resulting_tracks = self.get_custom_track([f'track.id == "{musicbrainz_releasetrackid}"'])
|
||||
if len(resulting_tracks) != 1:
|
||||
return -1
|
||||
|
||||
return resulting_tracks[0]
|
||||
|
||||
def get_tracks_to_download(self):
|
||||
return self.get_custom_track(['track.downloaded == 0'])
|
||||
|
||||
def get_tracks_without_src(self):
|
||||
return self.get_custom_track(["(track.url IS NULL OR track.src IS NULL)"])
|
||||
|
||||
def get_tracks_without_isrc(self):
|
||||
return self.get_custom_track(["track.isrc IS NULL"])
|
||||
|
||||
def get_tracks_without_filepath(self):
|
||||
return self.get_custom_track(["(track.file IS NULL OR track.path IS NULL OR track.genre IS NULL)"])
|
||||
|
||||
def get_tracks_for_lyrics(self):
|
||||
return self.get_custom_track(["track.lyrics IS NULL"])
|
||||
|
||||
def add_lyrics(self, track_id: str, lyrics: str):
|
||||
query = f"""
|
||||
UPDATE track
|
||||
SET lyrics = ?
|
||||
WHERE '{track_id}' == id;
|
||||
"""
|
||||
self.cursor.execute(query, (str(lyrics), ))
|
||||
self.connection.commit()
|
||||
|
||||
def update_download_status(self, track_id: str):
|
||||
query = f"UPDATE track SET downloaded = 1, WHERE '{track_id}' == id;"
|
||||
self.cursor.execute(query)
|
||||
self.connection.commit()
|
||||
|
||||
def set_download_data(self, track_id: str, url: str, src: str):
|
||||
query = f"""
|
||||
UPDATE track
|
||||
SET url = ?,
|
||||
src = ?
|
||||
WHERE '{track_id}' == id;
|
||||
"""
|
||||
self.cursor.execute(query, (url, src))
|
||||
self.connection.commit()
|
||||
|
||||
def set_filepath(self, track_id: str, file: str, path: str, genre: str):
|
||||
query = f"""
|
||||
UPDATE track
|
||||
SET file = ?,
|
||||
path = ?,
|
||||
genre = ?
|
||||
WHERE '{track_id}' == id;
|
||||
"""
|
||||
self.cursor.execute(query, (file, path, genre))
|
||||
self.connection.commit()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import tempfile
|
||||
|
||||
temp_folder = "music-downloader"
|
||||
temp_dir = os.path.join(tempfile.gettempdir(), temp_folder)
|
||||
if not os.path.exists(temp_dir):
|
||||
os.mkdir(temp_dir)
|
||||
|
||||
temp_dir = get_temp_dir()
|
||||
DATABASE_FILE = "metadata.db"
|
||||
DATABASE_STRUCTURE_FILE = "database_structure.sql"
|
||||
db_path = os.path.join(TEMP_DIR, DATABASE_FILE)
|
||||
|
||||
logging.basicConfig()
|
||||
|
||||
logger = logging.getLogger("database")
|
||||
logger.setLevel(logging.DEBUG)
|
||||
|
||||
database = Database(os.path.join(temp_dir, "metadata.db"), os.path.join(temp_dir, "database_structure.sql"), logger,
|
||||
reset_anyways=True)
|
||||
@@ -0,0 +1,340 @@
|
||||
from ..utils.shared import *
|
||||
from ..utils.object_handeling import get_elem_from_obj, parse_music_brainz_date
|
||||
|
||||
from typing import List
|
||||
import musicbrainzngs
|
||||
import logging
|
||||
|
||||
# I don't know if it would be feesable to set up my own mb instance
|
||||
# https://github.com/metabrainz/musicbrainz-docker
|
||||
|
||||
|
||||
# IMPORTANT DOCUMENTATION WHICH CONTAINS FOR EXAMPLE THE INCLUDES
|
||||
# https://python-musicbrainzngs.readthedocs.io/en/v0.7.1/api/#getting-data
|
||||
|
||||
logger = METADATA_DOWNLOAD_LOGGER
|
||||
|
||||
|
||||
class MetadataDownloader:
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
class Artist:
|
||||
def __init__(
|
||||
self,
|
||||
musicbrainz_artistid: str,
|
||||
release_groups: List = [],
|
||||
new_release_groups: bool = True
|
||||
):
|
||||
"""
|
||||
release_groups: list
|
||||
"""
|
||||
self.release_groups = release_groups
|
||||
|
||||
self.musicbrainz_artistid = musicbrainz_artistid
|
||||
|
||||
try:
|
||||
result = musicbrainzngs.get_artist_by_id(self.musicbrainz_artistid, includes=["release-groups", "releases"])
|
||||
except musicbrainzngs.musicbrainz.NetworkError:
|
||||
return
|
||||
artist_data = get_elem_from_obj(result, ['artist'], return_if_none={})
|
||||
|
||||
self.artist = get_elem_from_obj(artist_data, ['name'])
|
||||
|
||||
self.save()
|
||||
|
||||
# STARTING TO FETCH' RELEASE GROUPS. IMPORTANT: DON'T WRITE ANYTHING BESIDES THAT HERE
|
||||
if not new_release_groups:
|
||||
return
|
||||
# sort all release groups by date and add album sort to have them in chronological order.
|
||||
release_groups = artist_data['release-group-list']
|
||||
for i, release_group in enumerate(release_groups):
|
||||
release_groups[i]['first-release-date'] = parse_music_brainz_date(release_group['first-release-date'])
|
||||
release_groups.sort(key=lambda x: x['first-release-date'])
|
||||
|
||||
for i, release_group in enumerate(release_groups):
|
||||
self.release_groups.append(MetadataDownloader.ReleaseGroup(
|
||||
musicbrainz_releasegroupid=release_group['id'],
|
||||
artists=[self],
|
||||
albumsort=i + 1
|
||||
))
|
||||
|
||||
def __str__(self):
|
||||
newline = "\n"
|
||||
return f"artist: \"{self.artist}\""
|
||||
|
||||
def save(self):
|
||||
logger.info(f"caching {self}")
|
||||
database.add_artist(
|
||||
musicbrainz_artistid=self.musicbrainz_artistid,
|
||||
artist=self.artist
|
||||
)
|
||||
|
||||
class ReleaseGroup:
|
||||
def __init__(
|
||||
self,
|
||||
musicbrainz_releasegroupid: str,
|
||||
artists=[],
|
||||
albumsort: int = None,
|
||||
only_download_distinct_releases: bool = True,
|
||||
fetch_further: bool = True
|
||||
):
|
||||
"""
|
||||
split_artists: list -> if len > 1: album_artist=VariousArtists
|
||||
releases: list
|
||||
"""
|
||||
|
||||
self.musicbrainz_releasegroupid = musicbrainz_releasegroupid
|
||||
self.artists = artists
|
||||
self.releases = []
|
||||
|
||||
try:
|
||||
result = musicbrainzngs.get_release_group_by_id(musicbrainz_releasegroupid,
|
||||
includes=["artist-credits", "releases"])
|
||||
except musicbrainzngs.musicbrainz.NetworkError:
|
||||
return
|
||||
release_group_data = get_elem_from_obj(result, ['release-group'], return_if_none={})
|
||||
artist_datas = get_elem_from_obj(release_group_data, ['artist-credit'], return_if_none={})
|
||||
release_datas = get_elem_from_obj(release_group_data, ['release-list'], return_if_none={})
|
||||
|
||||
# only for printing the release
|
||||
self.name = get_elem_from_obj(release_group_data, ['title'])
|
||||
|
||||
for artist_data in artist_datas:
|
||||
artist_id = get_elem_from_obj(artist_data, ['artist', 'id'])
|
||||
if artist_id is None:
|
||||
continue
|
||||
self.append_artist(artist_id)
|
||||
self.albumartist = "Various Artists" if len(self.artists) > 1 else self.artists[0].artist
|
||||
self.album_artist_id = None if self.albumartist == "Various Artists" else self.artists[
|
||||
0].musicbrainz_artistid
|
||||
|
||||
self.albumsort = albumsort
|
||||
self.musicbrainz_albumtype = get_elem_from_obj(release_group_data, ['primary-type'])
|
||||
self.compilation = "1" if self.musicbrainz_albumtype == "Compilation" else None
|
||||
|
||||
self.save()
|
||||
|
||||
if not fetch_further:
|
||||
return
|
||||
|
||||
if only_download_distinct_releases:
|
||||
self.append_distinct_releases(release_datas)
|
||||
else:
|
||||
self.append_all_releases(release_datas)
|
||||
|
||||
def __str__(self):
|
||||
return f"release group: \"{self.name}\""
|
||||
|
||||
def save(self):
|
||||
logger.info(f"caching {self}")
|
||||
database.add_release_group(
|
||||
musicbrainz_releasegroupid=self.musicbrainz_releasegroupid,
|
||||
artist_ids=[artist.musicbrainz_artistid for artist in self.artists],
|
||||
albumartist=self.albumartist,
|
||||
albumsort=self.albumsort,
|
||||
musicbrainz_albumtype=self.musicbrainz_albumtype,
|
||||
compilation=self.compilation,
|
||||
album_artist_id=self.album_artist_id
|
||||
)
|
||||
|
||||
def append_artist(self, artist_id: str):
|
||||
for existing_artist in self.artists:
|
||||
if artist_id == existing_artist.musicbrainz_artistid:
|
||||
return existing_artist
|
||||
new_artist = MetadataDownloader.Artist(artist_id, release_groups=[self],
|
||||
new_release_groups=False)
|
||||
self.artists.append(new_artist)
|
||||
return new_artist
|
||||
|
||||
def append_release(self, release_data: dict):
|
||||
musicbrainz_albumid = get_elem_from_obj(release_data, ['id'])
|
||||
if musicbrainz_albumid is None:
|
||||
return
|
||||
self.releases.append(
|
||||
MetadataDownloader.Release(musicbrainz_albumid, release_group=self))
|
||||
|
||||
def append_distinct_releases(self, release_datas: List[dict]):
|
||||
titles = {}
|
||||
|
||||
for release_data in release_datas:
|
||||
title = get_elem_from_obj(release_data, ['title'])
|
||||
if title is None:
|
||||
continue
|
||||
titles[title] = release_data
|
||||
|
||||
for key in titles:
|
||||
self.append_release(titles[key])
|
||||
|
||||
def append_all_releases(self, release_datas: List[dict]):
|
||||
for release_data in release_datas:
|
||||
self.append_release(release_data)
|
||||
|
||||
class Release:
|
||||
def __init__(
|
||||
self,
|
||||
musicbrainz_albumid: str,
|
||||
release_group=None,
|
||||
fetch_furter: bool = True
|
||||
):
|
||||
"""
|
||||
release_group: ReleaseGroup
|
||||
tracks: list
|
||||
"""
|
||||
self.musicbrainz_albumid = musicbrainz_albumid
|
||||
self.release_group = release_group
|
||||
self.tracklist = []
|
||||
|
||||
try:
|
||||
result = musicbrainzngs.get_release_by_id(self.musicbrainz_albumid,
|
||||
includes=["recordings", "labels", "release-groups"])
|
||||
except musicbrainzngs.musicbrainz.NetworkError:
|
||||
return
|
||||
release_data = get_elem_from_obj(result, ['release'], return_if_none={})
|
||||
label_data = get_elem_from_obj(release_data, ['label-info-list'], return_if_none={})
|
||||
recording_datas = get_elem_from_obj(release_data, ['medium-list', 0, 'track-list'], return_if_none=[])
|
||||
release_group_data = get_elem_from_obj(release_data, ['release-group'], return_if_none={})
|
||||
if self.release_group is None:
|
||||
self.release_group = MetadataDownloader.ReleaseGroup(
|
||||
musicbrainz_releasegroupid=get_elem_from_obj(
|
||||
release_group_data, ['id']),
|
||||
fetch_further=False)
|
||||
|
||||
self.title = get_elem_from_obj(release_data, ['title'])
|
||||
self.copyright = get_elem_from_obj(label_data, [0, 'label', 'name'])
|
||||
|
||||
self.album_status = get_elem_from_obj(release_data, ['status'])
|
||||
self.language = get_elem_from_obj(release_data, ['text-representation', 'language'])
|
||||
self.year = get_elem_from_obj(release_data, ['date'], lambda x: x.split("-")[0])
|
||||
self.date = get_elem_from_obj(release_data, ['date'])
|
||||
self.country = get_elem_from_obj(release_data, ['country'])
|
||||
self.barcode = get_elem_from_obj(release_data, ['barcode'])
|
||||
|
||||
self.save()
|
||||
if fetch_furter:
|
||||
self.append_recordings(recording_datas)
|
||||
|
||||
def __str__(self):
|
||||
return f"release: {self.title} ©{self.copyright} {self.album_status}"
|
||||
|
||||
def save(self):
|
||||
logger.info(f"caching {self}")
|
||||
database.add_release(
|
||||
musicbrainz_albumid=self.musicbrainz_albumid,
|
||||
release_group_id=self.release_group.musicbrainz_releasegroupid,
|
||||
title=self.title,
|
||||
copyright_=self.copyright,
|
||||
album_status=self.album_status,
|
||||
language=self.language,
|
||||
year=self.year,
|
||||
date=self.date,
|
||||
country=self.country,
|
||||
barcode=self.barcode
|
||||
)
|
||||
|
||||
def append_recordings(self, recording_datas: dict):
|
||||
for i, recording_data in enumerate(recording_datas):
|
||||
musicbrainz_releasetrackid = get_elem_from_obj(recording_data, ['recording', 'id'])
|
||||
if musicbrainz_releasetrackid is None:
|
||||
continue
|
||||
|
||||
self.tracklist.append(
|
||||
MetadataDownloader.Track(musicbrainz_releasetrackid, self,
|
||||
track_number=str(i + 1)))
|
||||
|
||||
class Track:
|
||||
def __init__(
|
||||
self,
|
||||
musicbrainz_releasetrackid: str,
|
||||
release=None,
|
||||
track_number: str = None
|
||||
):
|
||||
"""
|
||||
release: Release
|
||||
feature_artists: list
|
||||
"""
|
||||
|
||||
self.musicbrainz_releasetrackid = musicbrainz_releasetrackid
|
||||
self.release = release
|
||||
self.artists = []
|
||||
|
||||
self.track_number = track_number
|
||||
|
||||
try:
|
||||
result = musicbrainzngs.get_recording_by_id(self.musicbrainz_releasetrackid,
|
||||
includes=["artists", "releases", "recording-rels", "isrcs",
|
||||
"work-level-rels"])
|
||||
except musicbrainzngs.musicbrainz.NetworkError:
|
||||
return
|
||||
recording_data = result['recording']
|
||||
release_data = get_elem_from_obj(recording_data, ['release-list', -1])
|
||||
if self.release is None:
|
||||
self.release = MetadataDownloader.Release(get_elem_from_obj(release_data, ['id']), fetch_furter=False)
|
||||
|
||||
for artist_data in get_elem_from_obj(recording_data, ['artist-credit'], return_if_none=[]):
|
||||
self.append_artist(get_elem_from_obj(artist_data, ['artist', 'id']))
|
||||
|
||||
self.isrc = get_elem_from_obj(recording_data, ['isrc-list', 0])
|
||||
self.title = recording_data['title']
|
||||
|
||||
self.save()
|
||||
|
||||
def __str__(self):
|
||||
return f"track: \"{self.title}\" {self.isrc or ''}"
|
||||
|
||||
def save(self):
|
||||
logger.info(f"caching {self}")
|
||||
|
||||
database.add_track(
|
||||
musicbrainz_releasetrackid=self.musicbrainz_releasetrackid,
|
||||
musicbrainz_albumid=self.release.musicbrainz_albumid,
|
||||
feature_aritsts=[artist.musicbrainz_artistid for artist in self.artists],
|
||||
tracknumber=self.track_number,
|
||||
track=self.title,
|
||||
isrc=self.isrc
|
||||
)
|
||||
|
||||
def append_artist(self, artist_id: str):
|
||||
if artist_id is None:
|
||||
return
|
||||
|
||||
for existing_artist in self.artists:
|
||||
if artist_id == existing_artist.musicbrainz_artistid:
|
||||
return existing_artist
|
||||
new_artist = MetadataDownloader.Artist(artist_id, new_release_groups=False)
|
||||
self.artists.append(new_artist)
|
||||
return new_artist
|
||||
|
||||
def download(self, option: dict):
|
||||
type_ = option['type']
|
||||
mb_id = option['id']
|
||||
|
||||
if type_ == "artist":
|
||||
return self.Artist(mb_id)
|
||||
if type_ == "release_group":
|
||||
return self.ReleaseGroup(mb_id)
|
||||
if type_ == "release":
|
||||
return self.Release(mb_id)
|
||||
if type_ == "recording":
|
||||
return self.Track(mb_id)
|
||||
|
||||
logger.error(f"download type {type_} doesn't exists :(")
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
logging.basicConfig(
|
||||
level=logging.INFO,
|
||||
format="%(asctime)s [%(levelname)s] %(message)s",
|
||||
handlers=[
|
||||
logging.FileHandler(os.path.join(temp_dir, LOG_FILE)),
|
||||
logging.StreamHandler()
|
||||
]
|
||||
)
|
||||
|
||||
downloader = MetadataDownloader()
|
||||
|
||||
downloader.download({'id': 'd2006339-9e98-4624-a386-d503328eb854', 'type': 'recording'})
|
||||
downloader.download({'id': 'cdd16860-35fd-46af-bd8c-5de7b15ebc31', 'type': 'release'})
|
||||
# download({'id': '4b9af532-ef7e-42ab-8b26-c466327cb5e0', 'type': 'release'})
|
||||
#download({'id': 'c24ed9e7-6df9-44de-8570-975f1a5a75d1', 'type': 'track'})
|
||||
@@ -0,0 +1,24 @@
|
||||
from datetime import date
|
||||
|
||||
|
||||
def get_elem_from_obj(current_object, keys: list, after_process=lambda x: x, return_if_none=None):
|
||||
current_object = current_object
|
||||
for key in keys:
|
||||
if key in current_object or (type(key) == int and key < len(current_object)):
|
||||
current_object = current_object[key]
|
||||
else:
|
||||
return return_if_none
|
||||
return after_process(current_object)
|
||||
|
||||
|
||||
def parse_music_brainz_date(mb_date: str) -> date:
|
||||
year = 1
|
||||
month = 1
|
||||
day = 1
|
||||
|
||||
first_release_date = mb_date
|
||||
if first_release_date.count("-") == 2:
|
||||
year, month, day = [int(i) for i in first_release_date.split("-")]
|
||||
elif first_release_date.count("-") == 0 and first_release_date.isdigit():
|
||||
year = int(first_release_date)
|
||||
return date(year, month, day)
|
||||
@@ -0,0 +1,364 @@
|
||||
from typing import List
|
||||
import musicbrainzngs
|
||||
|
||||
from ..utils.shared import *
|
||||
from ..utils.object_handeling import get_elem_from_obj, parse_music_brainz_date
|
||||
|
||||
logger = SEARCH_LOGGER
|
||||
|
||||
MAX_PARAMETERS = 3
|
||||
OPTION_TYPES = ['artist', 'release_group', 'release', 'recording']
|
||||
|
||||
|
||||
class Option:
|
||||
def __init__(self, type_: str, id_: str, name: str, additional_info: str = "") -> None:
|
||||
# print(type_, id_, name)
|
||||
if type_ not in OPTION_TYPES:
|
||||
raise ValueError(f"type: {type_} doesn't exist. Leagal Values: {OPTION_TYPES}")
|
||||
self.type = type_
|
||||
self.name = name
|
||||
self.id = id_
|
||||
|
||||
self.additional_info = additional_info
|
||||
|
||||
def __getitem__(self, item):
|
||||
map_ = {
|
||||
"id": self.id,
|
||||
"type": self.type,
|
||||
"kind": self.type,
|
||||
"name": self.name
|
||||
}
|
||||
return map_[item]
|
||||
|
||||
def __repr__(self) -> str:
|
||||
type_repr = {
|
||||
'artist': 'artist\t\t',
|
||||
'release_group': 'release group\t',
|
||||
'release': 'release\t\t',
|
||||
'recording': 'recording\t'
|
||||
}
|
||||
return f"{type_repr[self.type]}: \"{self.name}\"{self.additional_info}"
|
||||
|
||||
|
||||
class MultipleOptions:
|
||||
def __init__(self, option_list: List[Option]) -> None:
|
||||
self.option_list = option_list
|
||||
|
||||
def __repr__(self) -> str:
|
||||
return "\n".join([f"{str(i).zfill(2)}) {choice.__repr__()}" for i, choice in enumerate(self.option_list)])
|
||||
|
||||
|
||||
class Search:
|
||||
def __init__(self) -> None:
|
||||
self.options_history = []
|
||||
self.current_option: Option
|
||||
|
||||
def append_new_choices(self, new_choices: List[Option]) -> MultipleOptions:
|
||||
self.options_history.append(new_choices)
|
||||
return MultipleOptions(new_choices)
|
||||
|
||||
def get_previous_options(self):
|
||||
self.options_history.pop(-1)
|
||||
return MultipleOptions(self.options_history[-1])
|
||||
|
||||
@staticmethod
|
||||
def fetch_new_options_from_artist(artist: Option):
|
||||
"""
|
||||
returning list of artist and every release group
|
||||
"""
|
||||
result = musicbrainzngs.get_artist_by_id(artist.id, includes=["release-groups", "releases"])
|
||||
artist_data = get_elem_from_obj(result, ['artist'], return_if_none={})
|
||||
|
||||
result = [artist]
|
||||
|
||||
# sort all release groups by date and add album sort to have them in chronological order.
|
||||
release_group_list = artist_data['release-group-list']
|
||||
for i, release_group in enumerate(release_group_list):
|
||||
release_group_list[i]['first-release-date'] = parse_music_brainz_date(release_group['first-release-date'])
|
||||
release_group_list.sort(key=lambda x: x['first-release-date'])
|
||||
release_group_list = [Option("release_group", get_elem_from_obj(release_group_, ['id']),
|
||||
get_elem_from_obj(release_group_, ['title']),
|
||||
additional_info=f" ({get_elem_from_obj(release_group_, ['type'])}) from {get_elem_from_obj(release_group_, ['first-release-date'])}")
|
||||
for release_group_ in release_group_list]
|
||||
|
||||
result.extend(release_group_list)
|
||||
return result
|
||||
|
||||
@staticmethod
|
||||
def fetch_new_options_from_release_group(release_group: Option):
|
||||
"""
|
||||
returning list including the artists, the releases and the tracklist of the first release
|
||||
"""
|
||||
results = []
|
||||
|
||||
result = musicbrainzngs.get_release_group_by_id(release_group.id,
|
||||
includes=["artist-credits", "releases"])
|
||||
release_group_data = get_elem_from_obj(result, ['release-group'], return_if_none={})
|
||||
artist_datas = get_elem_from_obj(release_group_data, ['artist-credit'], return_if_none={})
|
||||
release_datas = get_elem_from_obj(release_group_data, ['release-list'], return_if_none={})
|
||||
|
||||
# appending all the artists to results
|
||||
for artist_data in artist_datas:
|
||||
results.append(Option('artist', get_elem_from_obj(artist_data, ['artist', 'id']),
|
||||
get_elem_from_obj(artist_data, ['artist', 'name'])))
|
||||
|
||||
# appending initial release group
|
||||
results.append(release_group)
|
||||
|
||||
# appending all releases
|
||||
first_release = None
|
||||
for i, release_data in enumerate(release_datas):
|
||||
results.append(
|
||||
Option('release', get_elem_from_obj(release_data, ['id']), get_elem_from_obj(release_data, ['title']),
|
||||
additional_info=f" ({get_elem_from_obj(release_data, ['status'])})"))
|
||||
if i == 0:
|
||||
first_release = results[-1]
|
||||
|
||||
# append tracklist of first release
|
||||
if first_release is not None:
|
||||
results.extend(Search.fetch_new_options_from_release(first_release, only_tracklist=True))
|
||||
|
||||
return results
|
||||
|
||||
@staticmethod
|
||||
def fetch_new_options_from_release(release: Option, only_tracklist: bool = False):
|
||||
"""
|
||||
artists
|
||||
release group
|
||||
release
|
||||
tracklist
|
||||
"""
|
||||
results = []
|
||||
result = musicbrainzngs.get_release_by_id(release.id,
|
||||
includes=["recordings", "labels", "release-groups", "artist-credits"])
|
||||
release_data = get_elem_from_obj(result, ['release'], return_if_none={})
|
||||
label_data = get_elem_from_obj(release_data, ['label-info-list'], return_if_none={})
|
||||
recording_datas = get_elem_from_obj(release_data, ['medium-list', 0, 'track-list'], return_if_none=[])
|
||||
release_group_data = get_elem_from_obj(release_data, ['release-group'], return_if_none={})
|
||||
artist_datas = get_elem_from_obj(release_data, ['artist-credit'], return_if_none={})
|
||||
|
||||
# appending all the artists to results
|
||||
for artist_data in artist_datas:
|
||||
results.append(Option('artist', get_elem_from_obj(artist_data, ['artist', 'id']),
|
||||
get_elem_from_obj(artist_data, ['artist', 'name'])))
|
||||
|
||||
# appending the according release group
|
||||
results.append(Option("release_group", get_elem_from_obj(release_group_data, ['id']),
|
||||
get_elem_from_obj(release_group_data, ['title']),
|
||||
additional_info=f" ({get_elem_from_obj(release_group_data, ['type'])}) from {get_elem_from_obj(release_group_data, ['first-release-date'])}"))
|
||||
|
||||
# appending the release
|
||||
results.append(release)
|
||||
|
||||
# appending the tracklist, but first putting it in a list, in case of only_tracklist being True to
|
||||
# return this instead
|
||||
tracklist = []
|
||||
for i, recording_data in enumerate(recording_datas):
|
||||
recording_data = recording_data['recording']
|
||||
tracklist.append(Option('recording', get_elem_from_obj(recording_data, ['id']),
|
||||
get_elem_from_obj(recording_data, ['title']),
|
||||
f" ({get_elem_from_obj(recording_data, ['length'])}) from {get_elem_from_obj(recording_data, ['artist-credit-phrase'])}"))
|
||||
|
||||
if only_tracklist:
|
||||
return tracklist
|
||||
results.extend(tracklist)
|
||||
return results
|
||||
|
||||
@staticmethod
|
||||
def fetch_new_options_from_record(recording: Option):
|
||||
"""
|
||||
artists, release, record
|
||||
"""
|
||||
results = []
|
||||
|
||||
result = musicbrainzngs.get_recording_by_id(recording.id, includes=["artists", "releases"])
|
||||
recording_data = result['recording']
|
||||
release_datas = get_elem_from_obj(recording_data, ['release-list'])
|
||||
artist_datas = get_elem_from_obj(recording_data, ['artist-credit'], return_if_none={})
|
||||
|
||||
# appending all the artists to results
|
||||
for artist_data in artist_datas:
|
||||
results.append(Option('artist', get_elem_from_obj(artist_data, ['artist', 'id']),
|
||||
get_elem_from_obj(artist_data, ['artist', 'name'])))
|
||||
|
||||
# appending all releases
|
||||
for i, release_data in enumerate(release_datas):
|
||||
results.append(
|
||||
Option('release', get_elem_from_obj(release_data, ['id']), get_elem_from_obj(release_data, ['title']),
|
||||
additional_info=f" ({get_elem_from_obj(release_data, ['status'])})"))
|
||||
|
||||
results.append(recording)
|
||||
|
||||
return results
|
||||
|
||||
def fetch_new_options(self) -> MultipleOptions:
|
||||
if self.current_option is None:
|
||||
return -1
|
||||
|
||||
result = []
|
||||
if self.current_option.type == 'artist':
|
||||
result = self.fetch_new_options_from_artist(self.current_option)
|
||||
elif self.current_option.type == 'release_group':
|
||||
result = self.fetch_new_options_from_release_group(self.current_option)
|
||||
elif self.current_option.type == 'release':
|
||||
result = self.fetch_new_options_from_release(self.current_option)
|
||||
elif self.current_option.type == 'recording':
|
||||
result = self.fetch_new_options_from_record(self.current_option)
|
||||
|
||||
return self.append_new_choices(result)
|
||||
|
||||
def choose(self, index: int) -> MultipleOptions:
|
||||
if len(self.options_history) == 0:
|
||||
logging.error("initial query neaded before choosing")
|
||||
return MultipleOptions([])
|
||||
|
||||
latest_options = self.options_history[-1]
|
||||
if index >= len(latest_options):
|
||||
logging.error("index outside of options")
|
||||
return MultipleOptions([])
|
||||
|
||||
self.current_option = latest_options[index]
|
||||
return self.fetch_new_options()
|
||||
|
||||
@staticmethod
|
||||
def search_recording_from_text(artist: str = None, release_group: str = None, recording: str = None,
|
||||
query: str = None):
|
||||
result = musicbrainzngs.search_recordings(artist=artist, release=release_group, recording=recording,
|
||||
query=query)
|
||||
recording_list = get_elem_from_obj(result, ['recording-list'], return_if_none=[])
|
||||
|
||||
resulting_options = [
|
||||
Option("recording", get_elem_from_obj(recording_, ['id']), get_elem_from_obj(recording_, ['title']),
|
||||
additional_info=f" of {get_elem_from_obj(recording_, ['release-list', 0, 'title'])} by {get_elem_from_obj(recording_, ['artist-credit', 0, 'name'])}")
|
||||
for recording_ in recording_list]
|
||||
return resulting_options
|
||||
|
||||
@staticmethod
|
||||
def search_release_group_from_text(artist: str = None, release_group: str = None, query: str = None):
|
||||
result = musicbrainzngs.search_release_groups(artist=artist, releasegroup=release_group, query=query)
|
||||
release_group_list = get_elem_from_obj(result, ['release-group-list'], return_if_none=[])
|
||||
|
||||
resulting_options = [Option("release_group", get_elem_from_obj(release_group_, ['id']),
|
||||
get_elem_from_obj(release_group_, ['title']),
|
||||
additional_info=f" by {get_elem_from_obj(release_group_, ['artist-credit', 0, 'name'])}")
|
||||
for release_group_ in release_group_list]
|
||||
return resulting_options
|
||||
|
||||
@staticmethod
|
||||
def search_artist_from_text(artist: str = None, query: str = None):
|
||||
result = musicbrainzngs.search_artists(artist=artist, query=query)
|
||||
artist_list = get_elem_from_obj(result, ['artist-list'], return_if_none=[])
|
||||
|
||||
resulting_options = [Option("artist", get_elem_from_obj(artist_, ['id']), get_elem_from_obj(artist_, ['name']),
|
||||
additional_info=f": {', '.join([i['name'] for i in get_elem_from_obj(artist_, ['tag-list'], return_if_none=[])])}")
|
||||
for artist_ in artist_list]
|
||||
return resulting_options
|
||||
|
||||
def search_from_text(self, artist: str = None, release_group: str = None, recording: str = None) -> MultipleOptions:
|
||||
logger.info(
|
||||
f"searching specified artist: \"{artist}\", release group: \"{release_group}\", recording: \"{recording}\"")
|
||||
if artist is None and release_group is None and recording is None:
|
||||
logger.error("either artist, release group or recording has to be set")
|
||||
return MultipleOptions([])
|
||||
|
||||
if recording is not None:
|
||||
logger.info("search for recording")
|
||||
results = self.search_recording_from_text(artist=artist, release_group=release_group, recording=recording)
|
||||
elif release_group is not None:
|
||||
logger.info("search for release group")
|
||||
results = self.search_release_group_from_text(artist=artist, release_group=release_group)
|
||||
else:
|
||||
logger.info("search for artist")
|
||||
results = self.search_artist_from_text(artist=artist)
|
||||
|
||||
return self.append_new_choices(results)
|
||||
|
||||
def search_from_text_unspecified(self, query: str) -> MultipleOptions:
|
||||
logger.info(f"searching unspecified: \"{query}\"")
|
||||
|
||||
results = []
|
||||
results.extend(self.search_artist_from_text(query=query))
|
||||
results.extend(self.search_release_group_from_text(query=query))
|
||||
results.extend(self.search_recording_from_text(query=query))
|
||||
|
||||
return self.append_new_choices(results)
|
||||
|
||||
def search_from_query(self, query: str) -> MultipleOptions:
|
||||
if query is None:
|
||||
return MultipleOptions([])
|
||||
"""
|
||||
mit # wird ein neuer Parameter gestartet
|
||||
der Buchstabe dahinter legt die Art des Parameters fest
|
||||
"#a Psychonaut 4 #r Tired, Numb and #t Drop by Drop"
|
||||
if no # is in the query it gets treated as "unspecified query"
|
||||
:param query:
|
||||
:return:
|
||||
"""
|
||||
|
||||
if not '#' in query:
|
||||
return self.search_from_text_unspecified(query)
|
||||
|
||||
artist = None
|
||||
release_group = None
|
||||
recording = None
|
||||
|
||||
query = query.strip()
|
||||
parameters = query.split('#')
|
||||
parameters.remove('')
|
||||
|
||||
if len(parameters) > MAX_PARAMETERS:
|
||||
raise ValueError(f"too many parameters. Only {MAX_PARAMETERS} are allowed")
|
||||
|
||||
for parameter in parameters:
|
||||
splitted = parameter.split(" ")
|
||||
type_ = splitted[0]
|
||||
input_ = " ".join(splitted[1:]).strip()
|
||||
|
||||
if type_ == "a":
|
||||
artist = input_
|
||||
continue
|
||||
if type_ == "r":
|
||||
release_group = input_
|
||||
continue
|
||||
if type_ == "t":
|
||||
recording = input_
|
||||
continue
|
||||
|
||||
return self.search_from_text(artist=artist, release_group=release_group, recording=recording)
|
||||
|
||||
|
||||
def automated_demo():
|
||||
search = Search()
|
||||
search.search_from_text(artist="I Prevail")
|
||||
|
||||
# choose an artist
|
||||
search.choose(0)
|
||||
# choose a release group
|
||||
search.choose(9)
|
||||
# choose a release
|
||||
search.choose(2)
|
||||
# choose a recording
|
||||
search.choose(4)
|
||||
|
||||
|
||||
def interactive_demo():
|
||||
search = Search()
|
||||
while True:
|
||||
input_ = input(
|
||||
"q to quit, .. for previous options, int for this element, str to search for query, ok to download: ")
|
||||
input_.strip()
|
||||
if input_.lower() == "ok":
|
||||
break
|
||||
if input_.lower() == "q":
|
||||
break
|
||||
if input_.lower() == "..":
|
||||
search.get_previous_options()
|
||||
continue
|
||||
if input_.isdigit():
|
||||
search.choose(int(input_))
|
||||
continue
|
||||
search.search_from_query(input_)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
interactive_demo()
|
||||
@@ -0,0 +1,181 @@
|
||||
Metadata-Version: 2.1
|
||||
Name: music-kraken
|
||||
Version: 0.0.1
|
||||
Summary: An extensive music downloader crawling the internet. It gets its metadata from a couple metadata provider, and it scrapes the audiofiles.
|
||||
Home-page: https://github.com/HeIIow2/music-downloader
|
||||
Author: Hellow2
|
||||
Author-email: Hellow2 <Hellow2@outlook.de>
|
||||
Project-URL: Homepage, https://github.com/HeIIow2/music-downloader
|
||||
Classifier: Programming Language :: Python :: 3
|
||||
Classifier: Operating System :: OS Independent
|
||||
Requires-Python: >=3.7
|
||||
Description-Content-Type: text/markdown
|
||||
|
||||
# Music Kraken
|
||||
|
||||
RUN WITH: `python3 -m src` from the project Directory
|
||||
|
||||
This programm will first get the metadata of various songs from metadata provider like musicbrainz, and then search for download links on pages like bandcamp. Then it will download the song and edit the metadata according.
|
||||
|
||||
## Metadata
|
||||
|
||||
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz](musicbrainz.org/). This is a result of them being a website with a large Database spanning over all Genres.
|
||||
|
||||
### Musicbrainz
|
||||
|
||||
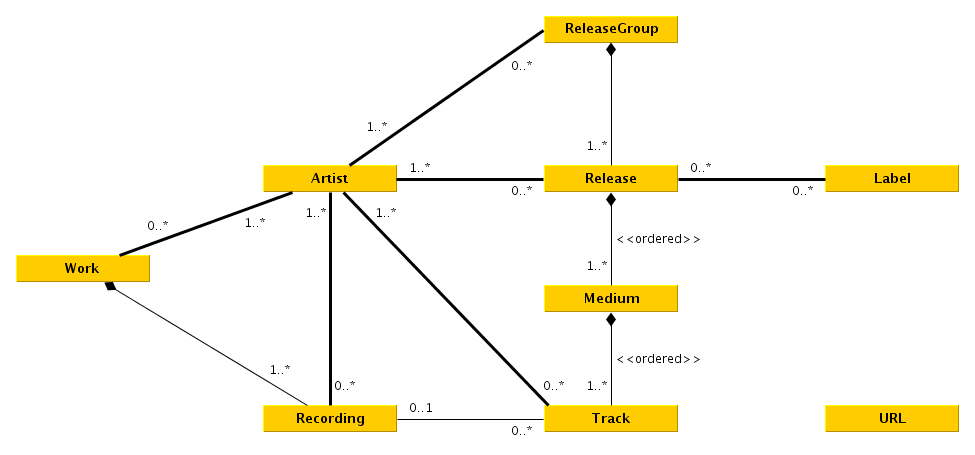
|
||||
|
||||
To fetch from [Musicbrainz](musicbrainz.org/) we first have to know what to fetch. A good start is to get an input querry, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
||||
|
||||
Then we can output them in the Terminal and ask for further input. Following can be inputed afterwards:
|
||||
|
||||
- `q` to quit
|
||||
- `ok` to download
|
||||
- `..` for previous options
|
||||
- `.` for current options
|
||||
- `an integer` for this element
|
||||
|
||||
If the following chosen element is an artist, its discography + a couple tracks are outputed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
||||
|
||||
**TO DO**
|
||||
|
||||
- Schow always the whole tracklist of an release if it is chosen
|
||||
- Show always the whole discography of an artist if it is chosen
|
||||
|
||||
Up to now it doesn't if the discography or tracklist is chosen.
|
||||
|
||||
### Metadata to fetch
|
||||
|
||||
I orient on which metadata to download on the keys in `mutagen.EasyID3` . Following I fatch and thus tag the MP3 with:
|
||||
- title
|
||||
- artist
|
||||
- albumartist
|
||||
- tracknumber
|
||||
- albumsort can sort albums cronological
|
||||
- titlesort is just set to the tracknumber to sort by track order to sort correctly
|
||||
- isrc
|
||||
- musicbrainz_artistid
|
||||
- musicbrainz_albumid
|
||||
- musicbrainz_albumartistid
|
||||
- musicbrainz_albumstatus
|
||||
- language
|
||||
- musicbrainz_albumtype
|
||||
- releasecountry
|
||||
- barcode
|
||||
|
||||
#### albumsort/titlesort
|
||||
|
||||
Those Tags are for the musicplayer to not sort for Example the albums of a band alphabetically, but in another way. I set it just to chronological order
|
||||
|
||||
#### isrc
|
||||
|
||||
This is the **international standart release code**. With this a track can be identified 100% percicely all of the time, if it is known and the website has a search api for that. Obviously this will get important later.
|
||||
|
||||
---
|
||||
|
||||
## Download
|
||||
|
||||
Now that the metadata is downloaded and cached, download sources need to be sound, because one can't listen to metadata. Granted it would be amazing if that would be possible.
|
||||
|
||||
### Musify
|
||||
|
||||
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). Its a russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search suff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottelneck defently is not at the speed of those requests.
|
||||
|
||||
For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"id":"Lorna Shore",
|
||||
"label":"Lorna Shore",
|
||||
"value":"Lorna Shore",
|
||||
"category":"Исполнители",
|
||||
"image":"https://39s.musify.club/img/68/9561484/25159224.jpg",
|
||||
"url":"/artist/lorna-shore-59611"
|
||||
},
|
||||
{"id":"Immortal","label":"Lorna Shore - Immortal (2020)","value":"Immortal","category":"Релизы","image":"https://39s-a.musify.club/img/70/20335517/52174338.jpg","url":"/release/lorna-shore-immortal-2020-1241300"},
|
||||
{"id":"Immortal","label":"Lorna Shore - Immortal","value":"Immortal","category":"Треки","image":"","url":"/track/lorna-shore-immortal-12475071"}
|
||||
]
|
||||
```
|
||||
|
||||
This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
|
||||
|
||||
- call the api with the querry being the track name
|
||||
- parse the json response to an object
|
||||
- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
|
||||
- If they match get the download links and cache them.
|
||||
|
||||
### Youtube
|
||||
|
||||
Herte the **isrc** plays a huge role. You probaply know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
|
||||
|
||||
Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
|
||||
|
||||
For searching, as well as for downloading I use the programm `youtube-dl`, which also has a programming interface for python.
|
||||
|
||||
There are two bottlenecks with this approach though:
|
||||
1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
|
||||
2. Ofthen musicbrainz just doesn't give the isrc for some songs.
|
||||
|
||||
**TODO**
|
||||
- look at how the isrc id derived an try to generate it for the tracks without directly getting it from mb.
|
||||
|
||||
|
||||
**Progress**
|
||||
- There is a great site whith a huge isrc database [https://isrc.soundexchange.com/](https://isrc.soundexchange.com/).
|
||||
|
||||
|
||||
## Lyrics
|
||||
|
||||
To get the Lyrics, I scrape them, and put those in the USLT ID3 Tags of for example mp3 files. Unfortunately some players, like the one I use, Rhythmbox don't support USLT Lyrics. So I created an Plugin for Rhythmbox. You can find it here: [https://github.com/HeIIow2/rythmbox-id3-lyrics-support](https://github.com/HeIIow2/rythmbox-id3-lyrics-support).
|
||||
|
||||
### Genius
|
||||
|
||||
For the lyrics source the page [https://genius.com/](https://genius.com/) is easily sufficient. It has most songs. Some songs are not present though, but that is fine, because the lyrics are optional anyways.
|
||||
|
||||
## Project overview
|
||||
|
||||
The file structure is as follows (might be slightly outdated):
|
||||
|
||||
```
|
||||
music-downloader
|
||||
├── assets
|
||||
│ └── database_structure.sql
|
||||
├── LICENSE
|
||||
├── notes.md
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
└── src
|
||||
├── audio
|
||||
│ └── song.py
|
||||
├── download_links.py
|
||||
├── download.py
|
||||
├── lyrics
|
||||
│ ├── genius.py
|
||||
│ └── lyrics.py
|
||||
├── __main__.py
|
||||
├── metadata
|
||||
│ ├── database.py
|
||||
│ ├── download.py
|
||||
│ ├── object_handeling.py
|
||||
│ └── search.py
|
||||
├── scraping
|
||||
│ ├── file_system.py
|
||||
│ ├── musify.py
|
||||
│ ├── phonetic_compares.py
|
||||
│ └── youtube_music.py
|
||||
├── url_to_path.py
|
||||
└── utils
|
||||
├── object_handeling.py
|
||||
├── phonetic_compares.py
|
||||
└── shared.py
|
||||
|
||||
```
|
||||
|
||||
You can obviously find the source code in the folder src. The two "most important" files are `__main__.py` and `utils/shared.py`.
|
||||
|
||||
In the first one is the code gluing everything together and providing the cli.
|
||||
|
||||
### utils
|
||||
|
||||
The constants like the global database object can be found in `shared.py`.
|
||||
@@ -0,0 +1,32 @@
|
||||
README.md
|
||||
pyproject.toml
|
||||
setup.py
|
||||
music_kraken/__init__.py
|
||||
music_kraken/__main__.py
|
||||
music_kraken/download.py
|
||||
music_kraken/download_links.py
|
||||
music_kraken/url_to_path.py
|
||||
music_kraken/audio/__init__.py
|
||||
music_kraken/audio/song.py
|
||||
music_kraken/lyrics/__init__.py
|
||||
music_kraken/lyrics/genius.py
|
||||
music_kraken/lyrics/lyrics.py
|
||||
music_kraken/metadata/__init__.py
|
||||
music_kraken/metadata/database.py
|
||||
music_kraken/metadata/download.py
|
||||
music_kraken/metadata/object_handeling.py
|
||||
music_kraken/metadata/search.py
|
||||
music_kraken/music_kraken.egg-info/PKG-INFO
|
||||
music_kraken/music_kraken.egg-info/SOURCES.txt
|
||||
music_kraken/music_kraken.egg-info/dependency_links.txt
|
||||
music_kraken/music_kraken.egg-info/requires.txt
|
||||
music_kraken/music_kraken.egg-info/top_level.txt
|
||||
music_kraken/scraping/__init__.py
|
||||
music_kraken/scraping/file_system.py
|
||||
music_kraken/scraping/musify.py
|
||||
music_kraken/scraping/phonetic_compares.py
|
||||
music_kraken/scraping/youtube_music.py
|
||||
music_kraken/utils/__init__.py
|
||||
music_kraken/utils/object_handeling.py
|
||||
music_kraken/utils/phonetic_compares.py
|
||||
music_kraken/utils/shared.py
|
||||
@@ -0,0 +1 @@
|
||||
|
||||
@@ -0,0 +1,8 @@
|
||||
requests~=2.28.1
|
||||
mutagen~=1.46.0
|
||||
musicbrainzngs~=0.7.1
|
||||
jellyfish~=0.9.0
|
||||
pydub~=0.25.1
|
||||
youtube_dl
|
||||
beautifulsoup4~=4.11.1
|
||||
pycountry~=22.3.5
|
||||
@@ -0,0 +1,10 @@
|
||||
__init__
|
||||
__main__
|
||||
audio
|
||||
download
|
||||
download_links
|
||||
lyrics
|
||||
metadata
|
||||
scraping
|
||||
url_to_path
|
||||
utils
|
||||
@@ -0,0 +1,57 @@
|
||||
import os
|
||||
|
||||
from ..utils.shared import *
|
||||
from ..utils import phonetic_compares
|
||||
|
||||
|
||||
def is_valid(a1, a2, t1, t2) -> bool:
|
||||
title_match, title_distance = phonetic_compares.match_titles(t1, t2)
|
||||
artist_match, artist_distance = phonetic_compares.match_artists(a1, a2)
|
||||
|
||||
return not title_match and not artist_match
|
||||
|
||||
|
||||
def get_metadata(file):
|
||||
artist = None
|
||||
title = None
|
||||
|
||||
audiofile = EasyID3(file)
|
||||
artist = audiofile['artist']
|
||||
title = audiofile['title']
|
||||
|
||||
return artist, title
|
||||
|
||||
|
||||
def check_for_song(folder, artists, title):
|
||||
if not os.path.exists(folder):
|
||||
return False
|
||||
files = [os.path.join(folder, i) for i in os.listdir(folder)]
|
||||
|
||||
for file in files:
|
||||
artists_, title_ = get_metadata(file)
|
||||
if is_valid(artists, artists_, title, title_):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def get_path(row):
|
||||
title = row['title']
|
||||
artists = row['artists']
|
||||
path_ = os.path.join(MUSIC_DIR, row['path'])
|
||||
|
||||
print(artists, title, path_)
|
||||
check_for_song(path_, artists, title)
|
||||
|
||||
return None
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
row = {'artists': ['Psychonaut 4'], 'id': '6b40186b-6678-4328-a4b8-eb7c9806a9fb', 'tracknumber': None,
|
||||
'titlesort ': None, 'musicbrainz_releasetrackid': '6b40186b-6678-4328-a4b8-eb7c9806a9fb',
|
||||
'musicbrainz_albumid': '0d229a02-74f6-4c77-8c20-6612295870ae', 'title': 'Sweet Decadance', 'isrc': None,
|
||||
'album': 'Neurasthenia', 'copyright': 'Talheim Records', 'album_status': 'Official', 'language': 'eng',
|
||||
'year': '2016', 'date': '2016-10-07', 'country': 'AT', 'barcode': None, 'albumartist': 'Psychonaut 4',
|
||||
'albumsort': None, 'musicbrainz_albumtype': 'Album', 'compilation': None,
|
||||
'album_artist_id': 'c0c720b5-012f-4204-a472-981403f37b12', 'path': 'dsbm/Psychonaut 4/Neurasthenia',
|
||||
'file': 'dsbm/Psychonaut 4/Neurasthenia/Sweet Decadance.mp3', 'genre': 'dsbm', 'url': None, 'src': None}
|
||||
print(get_path(row))
|
||||
@@ -0,0 +1,136 @@
|
||||
import logging
|
||||
import time
|
||||
|
||||
import requests
|
||||
import bs4
|
||||
|
||||
from ..utils.shared import *
|
||||
from ..utils import phonetic_compares
|
||||
|
||||
TRIES = 5
|
||||
TIMEOUT = 10
|
||||
|
||||
session = requests.Session()
|
||||
session.headers = {
|
||||
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:106.0) Gecko/20100101 Firefox/106.0",
|
||||
"Connection": "keep-alive",
|
||||
"Referer": "https://musify.club/"
|
||||
}
|
||||
session.proxies = proxies
|
||||
|
||||
|
||||
def get_musify_url(row):
|
||||
title = row['title']
|
||||
artists = row['artists']
|
||||
|
||||
url = f"https://musify.club/search/suggestions?term={artists[0]} - {title}"
|
||||
|
||||
try:
|
||||
r = session.get(url=url)
|
||||
except requests.exceptions.ConnectionError:
|
||||
return None
|
||||
if r.status_code == 200:
|
||||
autocomplete = r.json()
|
||||
for row in autocomplete:
|
||||
if any(a in row['label'] for a in artists) and "/track" in row['url']:
|
||||
return get_download_link(row['url'])
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def get_download_link(default_url):
|
||||
# https://musify.club/track/dl/18567672/rauw-alejandro-te-felicito-feat-shakira.mp3
|
||||
# /track/sundenklang-wenn-mein-herz-schreit-3883217'
|
||||
|
||||
file_ = default_url.split("/")[-1]
|
||||
musify_id = file_.split("-")[-1]
|
||||
musify_name = "-".join(file_.split("-")[:-1])
|
||||
|
||||
return f"https://musify.club/track/dl/{musify_id}/{musify_name}.mp3"
|
||||
|
||||
|
||||
def download_from_musify(file, url):
|
||||
logging.info(f"downloading: '{url}'")
|
||||
try:
|
||||
r = session.get(url, timeout=15)
|
||||
except requests.exceptions.ConnectionError or requests.exceptions.ReadTimeout:
|
||||
return -1
|
||||
if r.status_code != 200:
|
||||
if r.status_code == 404:
|
||||
logging.warning(f"{r.url} was not found")
|
||||
return -1
|
||||
if r.status_code == 503:
|
||||
logging.warning(f"{r.url} raised an internal server error")
|
||||
return -1
|
||||
raise ConnectionError(f"\"{url}\" returned {r.status_code}: {r.text}")
|
||||
with open(file, "wb") as mp3_file:
|
||||
mp3_file.write(r.content)
|
||||
logging.info("finished")
|
||||
|
||||
|
||||
def download(row):
|
||||
url = row['url']
|
||||
file_ = row['file']
|
||||
return download_from_musify(file_, url)
|
||||
|
||||
|
||||
def get_soup_of_search(query: str, trie=0):
|
||||
url = f"https://musify.club/search?searchText={query}"
|
||||
logging.debug(f"Trying to get soup from {url}")
|
||||
r = session.get(url)
|
||||
if r.status_code != 200:
|
||||
if r.status_code in [503] and trie < TRIES:
|
||||
logging.warning(f"youtube blocked downloading. ({trie}-{TRIES})")
|
||||
logging.warning(f"retrying in {TIMEOUT} seconds again")
|
||||
time.sleep(TIMEOUT)
|
||||
return get_soup_of_search(query, trie=trie + 1)
|
||||
|
||||
logging.warning("too many tries, returning")
|
||||
raise ConnectionError(f"{r.url} returned {r.status_code}:\n{r.content}")
|
||||
return bs4.BeautifulSoup(r.content, features="html.parser")
|
||||
|
||||
|
||||
def search_for_track(row):
|
||||
track = row['title']
|
||||
artist = row['artists']
|
||||
|
||||
soup = get_soup_of_search(f"{artist[0]} - {track}")
|
||||
tracklist_container_soup = soup.find_all("div", {"class": "playlist"})
|
||||
if len(tracklist_container_soup) == 0:
|
||||
return None
|
||||
if len(tracklist_container_soup) != 1:
|
||||
raise Exception("Connfusion Error. HTML Layout of https://musify.club changed.")
|
||||
tracklist_container_soup = tracklist_container_soup[0]
|
||||
|
||||
tracklist_soup = tracklist_container_soup.find_all("div", {"class": "playlist__details"})
|
||||
|
||||
def parse_track_soup(_track_soup):
|
||||
anchor_soups = _track_soup.find_all("a")
|
||||
band_name = anchor_soups[0].text.strip()
|
||||
title = anchor_soups[1].text.strip()
|
||||
url_ = anchor_soups[1]['href']
|
||||
return band_name, title, url_
|
||||
|
||||
for track_soup in tracklist_soup:
|
||||
band_option, title_option, track_url = parse_track_soup(track_soup)
|
||||
|
||||
title_match, title_distance = phonetic_compares.match_titles(track, title_option)
|
||||
band_match, band_distance = phonetic_compares.match_artists(artist, band_option)
|
||||
|
||||
logging.debug(f"{(track, title_option, title_match, title_distance)}")
|
||||
logging.debug(f"{(artist, band_option, band_match, band_distance)}")
|
||||
|
||||
if not title_match and not band_match:
|
||||
return get_download_link(track_url)
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def get_musify_url_slow(row):
|
||||
result = search_for_track(row)
|
||||
if result is not None:
|
||||
return result
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
pass
|
||||
@@ -0,0 +1,22 @@
|
||||
import jellyfish
|
||||
|
||||
TITLE_THRESHOLD_LEVENSHTEIN = 2
|
||||
|
||||
|
||||
def match_titles(title_1: str, title_2: str) -> (bool, int):
|
||||
distance = jellyfish.levenshtein_distance(title_1, title_2)
|
||||
return distance > TITLE_THRESHOLD_LEVENSHTEIN, distance
|
||||
|
||||
|
||||
def match_artists(artist_1, artist_2: str) -> (bool, int):
|
||||
if type(artist_1) == list:
|
||||
distances = []
|
||||
|
||||
for artist_1_ in artist_1:
|
||||
match, distance = match_titles(artist_1_, artist_2)
|
||||
if not match:
|
||||
return match, distance
|
||||
|
||||
distances.append(distance)
|
||||
return True, min(distances)
|
||||
return match_titles(artist_1, artist_2)
|
||||
@@ -0,0 +1,86 @@
|
||||
from typing import List
|
||||
|
||||
import youtube_dl
|
||||
import logging
|
||||
import time
|
||||
|
||||
from ..utils import phonetic_compares
|
||||
|
||||
YDL_OPTIONS = {'format': 'bestaudio', 'noplaylist': 'True'}
|
||||
YOUTUBE_URL_KEY = 'webpage_url'
|
||||
YOUTUBE_TITLE_KEY = 'title'
|
||||
WAIT_BETWEEN_BLOCK = 10
|
||||
MAX_TRIES = 3
|
||||
|
||||
|
||||
def get_youtube_from_isrc(isrc: str) -> List[dict]:
|
||||
# https://stackoverflow.com/questions/63388364/searching-youtube-videos-using-youtube-dl
|
||||
with youtube_dl.YoutubeDL(YDL_OPTIONS) as ydl:
|
||||
try:
|
||||
videos = ydl.extract_info(f"ytsearch:{isrc}", download=False)['entries']
|
||||
except youtube_dl.utils.DownloadError:
|
||||
return []
|
||||
|
||||
return [{
|
||||
'url': video[YOUTUBE_URL_KEY],
|
||||
'title': video[YOUTUBE_TITLE_KEY]
|
||||
} for video in videos]
|
||||
|
||||
|
||||
def get_youtube_url(row):
|
||||
if row['isrc'] is None:
|
||||
return None
|
||||
|
||||
real_title = row['title'].lower()
|
||||
|
||||
final_result = None
|
||||
results = get_youtube_from_isrc(row['isrc'])
|
||||
for result in results:
|
||||
video_title = result['title'].lower()
|
||||
match, distance = phonetic_compares.match_titles(video_title, real_title)
|
||||
|
||||
if match:
|
||||
logging.warning(
|
||||
f"dont downloading {result['url']} cuz the phonetic distance ({distance}) between {real_title} and {video_title} is to high.")
|
||||
continue
|
||||
|
||||
final_result = result
|
||||
|
||||
if final_result is None:
|
||||
return None
|
||||
return final_result['url']
|
||||
|
||||
|
||||
def download(row, trie: int = 0):
|
||||
url = row['url']
|
||||
file_ = row['file']
|
||||
options = {
|
||||
'format': 'bestaudio/best',
|
||||
'postprocessors': [{
|
||||
'key': 'FFmpegExtractAudio',
|
||||
'preferredcodec': 'mp3',
|
||||
'preferredquality': '192',
|
||||
}],
|
||||
'keepvideo': False,
|
||||
'outtmpl': file_
|
||||
}
|
||||
|
||||
try:
|
||||
with youtube_dl.YoutubeDL(options) as ydl:
|
||||
ydl.download([url])
|
||||
except youtube_dl.utils.DownloadError:
|
||||
logging.warning(f"youtube blocked downloading. ({trie}-{MAX_TRIES})")
|
||||
if trie >= MAX_TRIES:
|
||||
logging.warning("too many tries, returning")
|
||||
logging.warning(f"retrying in {WAIT_BETWEEN_BLOCK} seconds again")
|
||||
time.sleep(WAIT_BETWEEN_BLOCK)
|
||||
return download(row, trie=trie+1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# example isrc that exists on YouTube music
|
||||
ISRC = "DEUM71500715"
|
||||
result = get_youtube_from_isrc(ISRC)
|
||||
print(result)
|
||||
result = get_youtube_from_isrc("aslhfklasdhfjklasdfjkhasdjlfhlasdjfkuuiueiw")
|
||||
print(result)
|
||||
@@ -0,0 +1,58 @@
|
||||
import os.path
|
||||
import logging
|
||||
|
||||
from .utils.shared import *
|
||||
|
||||
logger = PATH_LOGGER
|
||||
|
||||
UNHIDE_CHAR = '_'
|
||||
|
||||
def unhide(part: str):
|
||||
if len(part) == 0:
|
||||
return ""
|
||||
if part[0] == ".":
|
||||
return part.replace(".", UNHIDE_CHAR, 1)
|
||||
|
||||
return part
|
||||
|
||||
|
||||
class UrlPath:
|
||||
def __init__(self, genre: str):
|
||||
|
||||
self.genre = genre
|
||||
|
||||
for row in database.get_tracks_without_filepath():
|
||||
file, path = self.get_path_from_row(row)
|
||||
database.set_filepath(row['id'], file, path, genre)
|
||||
|
||||
def get_path_from_row(self, row):
|
||||
"""
|
||||
genre/artist/song.mp3
|
||||
|
||||
:param row:
|
||||
:return: path:
|
||||
"""
|
||||
return os.path.join(self.get_genre(), self.get_artist(row), self.get_album(row),
|
||||
f"{self.get_song(row)}.mp3"), os.path.join(self.get_genre(), self.get_artist(row),
|
||||
self.get_album(row))
|
||||
|
||||
@staticmethod
|
||||
def escape_part(part: str):
|
||||
return unhide(part.replace("/", " "))
|
||||
|
||||
def get_genre(self):
|
||||
return self.escape_part(self.genre)
|
||||
|
||||
def get_album(self, row):
|
||||
return self.escape_part(row['album'])
|
||||
|
||||
def get_artist(self, row):
|
||||
artists = [artist['name'] for artist in row['artists']]
|
||||
return self.escape_part(artists[0])
|
||||
|
||||
def get_song(self, row):
|
||||
return self.escape_part(row['title'])
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
UrlPath("dsbm")
|
||||
@@ -0,0 +1,2 @@
|
||||
# tells what exists
|
||||
__all__ = ["shared", "object_handeling", "phonetic_compares"]
|
||||
@@ -0,0 +1,24 @@
|
||||
from datetime import date
|
||||
|
||||
|
||||
def get_elem_from_obj(current_object, keys: list, after_process=lambda x: x, return_if_none=None):
|
||||
current_object = current_object
|
||||
for key in keys:
|
||||
if key in current_object or (type(key) == int and key < len(current_object)):
|
||||
current_object = current_object[key]
|
||||
else:
|
||||
return return_if_none
|
||||
return after_process(current_object)
|
||||
|
||||
|
||||
def parse_music_brainz_date(mb_date: str) -> date:
|
||||
year = 1
|
||||
month = 1
|
||||
day = 1
|
||||
|
||||
first_release_date = mb_date
|
||||
if first_release_date.count("-") == 2:
|
||||
year, month, day = [int(i) for i in first_release_date.split("-")]
|
||||
elif first_release_date.count("-") == 0 and first_release_date.isdigit():
|
||||
year = int(first_release_date)
|
||||
return date(year, month, day)
|
||||
@@ -0,0 +1,48 @@
|
||||
import jellyfish
|
||||
import string
|
||||
|
||||
TITLE_THRESHOLD_LEVENSHTEIN = 2
|
||||
UNIFY_TO = " "
|
||||
|
||||
|
||||
def unify_punctuation(to_unify: str) -> str:
|
||||
for char in string.punctuation:
|
||||
to_unify = to_unify.replace(char, UNIFY_TO)
|
||||
return to_unify
|
||||
|
||||
|
||||
def remove_feature_part_from_track(title: str) -> str:
|
||||
if ")" != title[-1]:
|
||||
return title
|
||||
if "(" not in title:
|
||||
return title
|
||||
|
||||
return title[:title.index("(")]
|
||||
|
||||
|
||||
def modify_title(to_modify: str) -> str:
|
||||
to_modify = to_modify.strip()
|
||||
to_modify = to_modify.lower()
|
||||
to_modify = remove_feature_part_from_track(to_modify)
|
||||
to_modify = unify_punctuation(to_modify)
|
||||
return to_modify
|
||||
|
||||
|
||||
def match_titles(title_1: str, title_2: str):
|
||||
title_1, title_2 = modify_title(title_1), modify_title(title_2)
|
||||
distance = jellyfish.levenshtein_distance(title_1, title_2)
|
||||
return distance > TITLE_THRESHOLD_LEVENSHTEIN, distance
|
||||
|
||||
|
||||
def match_artists(artist_1, artist_2: str):
|
||||
if type(artist_1) == list:
|
||||
distances = []
|
||||
|
||||
for artist_1_ in artist_1:
|
||||
match, distance = match_titles(artist_1_, artist_2)
|
||||
if not match:
|
||||
return match, distance
|
||||
|
||||
distances.append(distance)
|
||||
return True, min(distances)
|
||||
return match_titles(artist_1, artist_2)
|
||||
@@ -0,0 +1,45 @@
|
||||
import musicbrainzngs
|
||||
import logging
|
||||
import tempfile
|
||||
import os
|
||||
|
||||
from ..metadata.database import Database
|
||||
|
||||
TEMP_FOLDER = "music-downloader"
|
||||
LOG_FILE = "download_logs.log"
|
||||
DATABASE_FILE = "metadata.db"
|
||||
DATABASE_STRUCTURE_FILE = "database_structure.sql"
|
||||
DATABASE_STRUCTURE_FALLBACK = "https://raw.githubusercontent.com/HeIIow2/music-downloader/master/assets/database_structure.sql"
|
||||
|
||||
SEARCH_LOGGER = logging.getLogger("mb-cli")
|
||||
DATABASE_LOGGER = logging.getLogger("database")
|
||||
METADATA_DOWNLOAD_LOGGER = logging.getLogger("metadata-download")
|
||||
URL_DOWNLOAD_LOGGER = logging.getLogger("ling-download")
|
||||
PATH_LOGGER = logging.getLogger("create-paths")
|
||||
DOWNLOAD_LOGGER = logging.getLogger("download")
|
||||
LYRICS_LOGGER = logging.getLogger("lyrics")
|
||||
GENIUS_LOGGER = logging.getLogger("genius")
|
||||
|
||||
NOT_A_GENRE = ".", "..", "misc_scripts", "Music", "script", ".git", ".idea"
|
||||
MUSIC_DIR = os.path.expanduser('~/Music')
|
||||
|
||||
temp_dir = os.path.join(tempfile.gettempdir(), TEMP_FOLDER)
|
||||
if not os.path.exists(temp_dir):
|
||||
os.mkdir(temp_dir)
|
||||
|
||||
logging.getLogger("musicbrainzngs").setLevel(logging.WARNING)
|
||||
musicbrainzngs.set_useragent("metadata receiver", "0.1", "https://github.com/HeIIow2/music-downloader")
|
||||
|
||||
|
||||
database = Database(os.path.join(temp_dir, DATABASE_FILE),
|
||||
os.path.join(temp_dir, DATABASE_STRUCTURE_FILE),
|
||||
DATABASE_STRUCTURE_FALLBACK,
|
||||
DATABASE_LOGGER,
|
||||
reset_anyways=False)
|
||||
|
||||
|
||||
TOR = False
|
||||
proxies = {
|
||||
'http': 'socks5h://127.0.0.1:9150',
|
||||
'https': 'socks5h://127.0.0.1:9150'
|
||||
} if TOR else {}
|
||||
Reference in New Issue
Block a user