Merge branch 'HeIIow2:master' into master
This commit is contained in:
@@ -2,15 +2,19 @@
|
|||||||
|
|
||||||
<img align="right" src="assets/logo.svg" width=300>
|
<img align="right" src="assets/logo.svg" width=300>
|
||||||
|
|
||||||
1. [Installlation](#installation)
|
- [Music Kraken](#music-kraken)
|
||||||
2. [Command Line Usage](#quick-guide)
|
- [Installation](#installation)
|
||||||
3. [Contribute](#contribute)
|
- [Notes for Python 3.9](#notes-for-python-39)
|
||||||
4. [Matrix Space](#matrix-space), if you don't wanna read: **[Invite](https://matrix.to/#/#music-kraken:matrix.org)**
|
- [Notes for WSL](#notes-for-wsl)
|
||||||
|
- [Quick-Guide](#quick-guide)
|
||||||
5. [Library Usage / Python Interface](#programming-interface--use-as-library)
|
- [CONTRIBUTE](#contribute)
|
||||||
6. [About Metadata](#metadata)
|
- [Matrix Space](#matrix-space)
|
||||||
7. [About the Audio](#download)
|
- [Programming Interface / Use as Library](#programming-interface--use-as-library)
|
||||||
8. [About the Lyrics](#lyrics)
|
- [Quick Overview](#quick-overview)
|
||||||
|
- [Data Model](#data-model)
|
||||||
|
- [Data Objects](#data-objects)
|
||||||
|
- [Creation](#creation)
|
||||||
|
- [Appending and Merging data](#appending-and-merging-data)
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -83,10 +87,12 @@ I decided against creating a discord server, due to piracy communities get often
|
|||||||
|
|
||||||
This application is $100\%$ centered around Data. Thus the most important thing for working with musik kraken is, to understand how I structured the data.
|
This application is $100\%$ centered around Data. Thus the most important thing for working with musik kraken is, to understand how I structured the data.
|
||||||
|
|
||||||
## quick Overview
|
## Quick Overview
|
||||||
|
|
||||||
- explanation of the [Data Model](#data-model)
|
- explanation of the [Data Model](#data-model)
|
||||||
- how to use the [Data Objects](#data-objects)
|
- how to use the [Data Objects](#data-objects)
|
||||||
|
- further Dokumentation of *hopefully* [most relevant classes](documentation/objects.md)
|
||||||
|
- the [old implementation](documentation/old_implementation.md)
|
||||||
|
|
||||||
```mermaid
|
```mermaid
|
||||||
---
|
---
|
||||||
@@ -299,8 +305,7 @@ For those who don't want any bugs and use it as intended *(which is recommended,
|
|||||||
|
|
||||||
If you want to append for example a Song to an Album, you obviously need to check beforehand if the Song already exists in the Album, and if so, you need to merge their data in one Song object, to not loose any Information.
|
If you want to append for example a Song to an Album, you obviously need to check beforehand if the Song already exists in the Album, and if so, you need to merge their data in one Song object, to not loose any Information.
|
||||||
|
|
||||||
Fortunately I implemented all of this functionality in [objects.Collection](#collection).append(music_object).
|
This is how I solve this problem:
|
||||||
I made a flow chart showing how it works:
|
|
||||||
|
|
||||||
```mermaid
|
```mermaid
|
||||||
---
|
---
|
||||||
@@ -345,9 +350,9 @@ the music_object exists
|
|||||||
exist-->|"if already exists"|merge --> return
|
exist-->|"if already exists"|merge --> return
|
||||||
```
|
```
|
||||||
|
|
||||||
This is Implemented in [music_kraken.objects.Collection.append()](src/music_kraken/objects/collection.py).
|
This is Implemented in [music_kraken.objects.Collection.append()](documentation/objects.md#collection). The merging which is mentioned in the flowchart is explained in the documentation of [DatabaseObject.merge()](documentation/objects.md#databaseobjectmerge).
|
||||||
|
|
||||||
The <u>indexing values</u> are defined in the superclass [DatabaseObject](src/music_kraken/objects/parents.py) and get implemented for each Object seperately. I will just give as example its implementation for the `Song` class:
|
The <u>indexing values</u> are defined in the superclass [DatabaseObject](documentation/objects.md#databaseobject) and get implemented for each Object seperately. I will just give as example its implementation for the `Song` class:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
@property
|
@property
|
||||||
@@ -359,332 +364,6 @@ def indexing_values(self) -> List[Tuple[str, object]]:
|
|||||||
*[('url', source.url) for source in self.source_collection]
|
*[('url', source.url) for source in self.source_collection]
|
||||||
]
|
]
|
||||||
```
|
```
|
||||||
|
|
||||||
## Classes and Objects
|
|
||||||
|
|
||||||
### music_kraken.objects
|
|
||||||
|
|
||||||
#### Collection
|
|
||||||
|
|
||||||
#### Song
|
|
||||||
|
|
||||||
So as you can see, the probably most important Class is the `music_kraken.Song` class. It is used to save the song in *(duh)*.
|
|
||||||
|
|
||||||
It has handful attributes, where half of em are self-explanatory, like `title` or `genre`. The ones like `isrc` are only relevant to you, if you know what it is, so I won't elaborate on it.
|
|
||||||
|
|
||||||
Interesting is the `date`. It uses a custom class. More on that [here](#music_krakenid3timestamp).
|
|
||||||
|
|
||||||
#### ID3Timestamp
|
|
||||||
|
|
||||||
For multiple Reasons I don't use the default `datetime.datetime` class.
|
|
||||||
|
|
||||||
The most important reason is, that you need to pass in at least year, month and day. For every other values there are default values, that are indistinguishable from values that are directly passed in. But I need optional values. The ID3 standart allows default values. Additionally `datetime.datetime` is immutable, thus I can't inherint all the methods. Sorry.
|
|
||||||
|
|
||||||
Anyway you can create those custom objects easily.
|
|
||||||
|
|
||||||
```python
|
|
||||||
from music_kraken import ID3Timestamp
|
|
||||||
|
|
||||||
# returns an instance of ID3Timestamp with the current time
|
|
||||||
ID3Timestamp.now()
|
|
||||||
|
|
||||||
# yea
|
|
||||||
ID3Timestamp(year=1986, month=3, day=1)
|
|
||||||
```
|
|
||||||
|
|
||||||
you can pass in the Arguments:
|
|
||||||
- year
|
|
||||||
- month
|
|
||||||
- day
|
|
||||||
- hour
|
|
||||||
- minute
|
|
||||||
- second
|
|
||||||
|
|
||||||
:)
|
|
||||||
|
|
||||||
# Old implementation
|
|
||||||
|
|
||||||
> IF U USE THIS NOW YOU ARE DUMB *no offense thoug*. IT ISN'T FINISHED AND THE STUFF YOU CODE NOW WILL BE BROKEN TOMORROW
|
|
||||||
> SOON YOU CAN THOUGH
|
|
||||||
|
|
||||||
If you want to use this project, or parts from it in your own projects from it,
|
|
||||||
make sure to be familiar with [Python Modules](https://docs.python.org/3/tutorial/modules.html).
|
|
||||||
Further and better documentation including code examples are yet to come, so here is the rough
|
|
||||||
module structure for now. (Should be up-to-date, but no guarantees)
|
|
||||||
|
|
||||||
If you simply want to run the builtin minimal cli just do this:
|
|
||||||
```python
|
|
||||||
from music_kraken import cli
|
|
||||||
|
|
||||||
cli()
|
|
||||||
```
|
|
||||||
|
|
||||||
### Search for Metadata
|
|
||||||
|
|
||||||
The whole program takes the data it processes further from the cache, a sqlite database.
|
|
||||||
So before you can do anything, you will need to fill it with the songs you want to download (*or create song objects manually, but more on that later*).
|
|
||||||
|
|
||||||
For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type`. The `id` corresponds to either
|
|
||||||
- an artist
|
|
||||||
- a release group
|
|
||||||
- a release
|
|
||||||
- a recording/track).
|
|
||||||
|
|
||||||
To get this info, you first have to initialize a search object (`music_kraken.MetadataSearch`).
|
|
||||||
|
|
||||||
```python
|
|
||||||
search_object = music_kraken.MetadataSearch()
|
|
||||||
```
|
|
||||||
|
|
||||||
Then you need an initial "text search" to get some options you can choose from. For
|
|
||||||
this you can either specify artists releases and whatever directly with one of the following functions:
|
|
||||||
|
|
||||||
```python
|
|
||||||
# you can directly specify artist, release group, release or recording/track
|
|
||||||
multiple_options = search_object.search_from_text(artist=input("input the name of the artist: "))
|
|
||||||
# you can specify a query see the simple integrated cli on how to use the query
|
|
||||||
multiple_options = search_object.search_from_query(query=input("input the query: "))
|
|
||||||
```
|
|
||||||
|
|
||||||
Both methods return an instance of `MultipleOptions`, which can be directly converted to a string.
|
|
||||||
|
|
||||||
```python
|
|
||||||
print(multiple_options)
|
|
||||||
```
|
|
||||||
|
|
||||||
After the first "*text search*" you can either again search the same way as before,
|
|
||||||
or you can further explore one of the options from the previous search.
|
|
||||||
To explore and select one options from `MultipleOptions`, simply call `MetadataSearch.choose(self, index: int)`.
|
|
||||||
The index represents the number in the previously returned instance of MultipleOptions.
|
|
||||||
The selected Option will be selected and can be downloaded in the next step.
|
|
||||||
|
|
||||||
*Thus, this has to be done **after either search_from_text or search_from_query***
|
|
||||||
|
|
||||||
```python
|
|
||||||
# choosing the best matching band
|
|
||||||
multiple_options = search_object.choose(0)
|
|
||||||
# choosing the first ever release group of this band
|
|
||||||
multiple_options = search_object.choose(1)
|
|
||||||
# printing out the current options
|
|
||||||
print(multiple_options)
|
|
||||||
```
|
|
||||||
|
|
||||||
This process can be repeated indefinitely (until you run out of memory).
|
|
||||||
A search history is kept in the Search instance. You could go back to
|
|
||||||
the previous search (without any loading time) like this:
|
|
||||||
|
|
||||||
```python
|
|
||||||
multiple_options = search_object.get_previous_options()
|
|
||||||
```
|
|
||||||
|
|
||||||
### Downloading Metadata / Filling up the Cache
|
|
||||||
|
|
||||||
You can download following metadata:
|
|
||||||
- an artist (the whole discography)
|
|
||||||
- a release group
|
|
||||||
- a release
|
|
||||||
- a track/recording
|
|
||||||
|
|
||||||
If you got an instance of `MetadataSearch`, like I elaborated [previously](#search-for-metadata), downloading every piece of metadata from the currently selected Option is really quite easy.
|
|
||||||
|
|
||||||
```python
|
|
||||||
from music_kraken import fetch_metadata_from_search
|
|
||||||
|
|
||||||
# this is it :)
|
|
||||||
music_kraken.fetch_metadata_from_search(search_object)
|
|
||||||
```
|
|
||||||
|
|
||||||
If you already know what you want to download you can skip the search instance and simply do the following.
|
|
||||||
|
|
||||||
```python
|
|
||||||
from music_kraken import fetch_metadata
|
|
||||||
|
|
||||||
# might change and break after I add multiple metadata sources which I will
|
|
||||||
|
|
||||||
fetch_metadata(id_=musicbrainz_id, type=metadata_type)
|
|
||||||
```
|
|
||||||
The option type is a string (*I'm sorry for not making it an enum I know its a bad pratice*), which can
|
|
||||||
have following values:
|
|
||||||
- 'artist'
|
|
||||||
- 'release_group'
|
|
||||||
- 'release'
|
|
||||||
- 'recording'
|
|
||||||
|
|
||||||
**PAY ATTENTION TO TYPOS, IT'S CASE SENSITIVE**
|
|
||||||
|
|
||||||
The musicbrainz id is just the id of the object from musicbrainz.
|
|
||||||
|
|
||||||
After following those steps, it might take a couple seconds/minutes to execute, but then the Cache will be filled.
|
|
||||||
|
|
||||||
|
|
||||||
### Cache / Temporary Database
|
|
||||||
|
|
||||||
All the data, the functions that download stuff use, can be gotten from the temporary database / cache.
|
|
||||||
The cache can be simply used like this:
|
|
||||||
|
|
||||||
```python
|
|
||||||
music_kraken.test_db
|
|
||||||
```
|
|
||||||
|
|
||||||
When fetching any song data from the cache, you will get it as Song
|
|
||||||
object (music_kraken.Song). There are multiple methods
|
|
||||||
to get different sets of Songs. The names explain the methods pretty
|
|
||||||
well:
|
|
||||||
|
|
||||||
```python
|
|
||||||
from music_kraken import cache
|
|
||||||
|
|
||||||
# gets a single track specified by the id
|
|
||||||
cache.get_track_metadata(id: str)
|
|
||||||
|
|
||||||
# gets a list of tracks.
|
|
||||||
cache.get_tracks_to_download()
|
|
||||||
cache.get_tracks_without_src()
|
|
||||||
cache.get_tracks_without_isrc()
|
|
||||||
cache.get_tracks_without_filepath()
|
|
||||||
```
|
|
||||||
|
|
||||||
The id always is a musicbrainz id and distinct for every track.
|
|
||||||
|
|
||||||
### Setting the Target
|
|
||||||
|
|
||||||
By default the music downloader doesn't know where to save the music file, if downloaded. To set those variables (the directory to save the file in and the filepath), it is enough to run one single command:
|
|
||||||
|
|
||||||
```python
|
|
||||||
from music_kraken import set_target
|
|
||||||
|
|
||||||
# adds file path, file directory and the genre to the database
|
|
||||||
set_target(genre="some test genre")
|
|
||||||
```
|
|
||||||
|
|
||||||
The concept of genres is too loose, to definitely say, this band exclusively plays this genre, or this song is this genre. This doesn't work manually, this will never work automatically. Thus, I've decided to just use the genre as category, to sort the artists and songs by. Most Music players support that.
|
|
||||||
|
|
||||||
As a result of this decision you will have to pass the genre in this function.
|
|
||||||
|
|
||||||
### Get Audio
|
|
||||||
|
|
||||||
This is most likely the most useful and unique feature of this Project. If the cache is filled, you can get audio sources for the songs you only have the metadata, and download them. This works for most songs. I'd guess for about 97% (?)
|
|
||||||
|
|
||||||
First of you will need a List of song objects `music_kraken.Song`. As [mentioned above](#cache--temporary-database), you could get a list like that from the cache.
|
|
||||||
|
|
||||||
```python
|
|
||||||
# Here is an Example
|
|
||||||
from music_kraken import (
|
|
||||||
cache,
|
|
||||||
fetch_sources,
|
|
||||||
fetch_audios
|
|
||||||
)
|
|
||||||
|
|
||||||
# scanning pages, searching for a download and storing results
|
|
||||||
fetch_sources(cache.get_tracks_without_src())
|
|
||||||
|
|
||||||
# downloading all previously fetched sources to previously defined targets
|
|
||||||
fetch_audios(cache.get_tracks_to_download())
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
*Note:*
|
|
||||||
To download audio two cases have to be met:
|
|
||||||
1. [The target](#setting-the-target) has to be set beforehand
|
|
||||||
2. The sources have to be fetched beforehand
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## Metadata
|
|
||||||
|
|
||||||
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz][mb]. This is a result of them being a website with a large Database spanning over all Genres.
|
|
||||||
|
|
||||||
### Musicbrainz
|
|
||||||
|
|
||||||
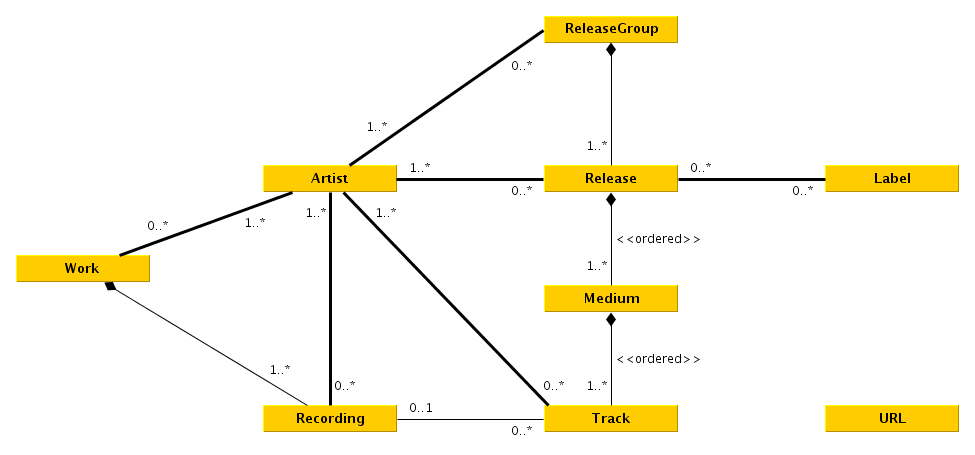
|
|
||||||
|
|
||||||
To fetch from [Musicbrainz][mb] we first have to know what to fetch. A good start is to get an input query, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
|
||||||
|
|
||||||
If the following chosen element is an artist, its discography + a couple tracks are printed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
|
||||||
|
|
||||||
For now, it doesn't if the discography or tracklist is chosen.
|
|
||||||
|
|
||||||
### Metadata to fetch
|
|
||||||
|
|
||||||
I orient on which metadata to download on the keys in `mutagen.EasyID3`. The following I fetch and tag the MP3 with:
|
|
||||||
- title
|
|
||||||
- artist
|
|
||||||
- albumartist
|
|
||||||
- tracknumber
|
|
||||||
- albumsort can sort albums cronological
|
|
||||||
- titlesort is just set to the tracknumber to sort by track order to sort correctly
|
|
||||||
- isrc
|
|
||||||
- musicbrainz_artistid
|
|
||||||
- musicbrainz_albumid
|
|
||||||
- musicbrainz_albumartistid
|
|
||||||
- musicbrainz_albumstatus
|
|
||||||
- language
|
|
||||||
- musicbrainz_albumtype
|
|
||||||
- releasecountry
|
|
||||||
- barcode
|
|
||||||
|
|
||||||
#### albumsort/titlesort
|
|
||||||
|
|
||||||
Those Tags are for the musicplayer to not sort for Example the albums of a band alphabetically, but in another way. I set it just to chronological order
|
|
||||||
|
|
||||||
#### isrc
|
|
||||||
|
|
||||||
This is the **international standart release code**. With this a track can be identified 99% of the time, if it is known and the website has a search api for that. Obviously this will get important later.
|
|
||||||
|
|
||||||
## Download
|
|
||||||
|
|
||||||
Now that the metadata is downloaded and cached, download sources need to be sound, because one can't listen to metadata. Granted it would be amazing if that would be possible.
|
|
||||||
|
|
||||||
### Musify
|
|
||||||
|
|
||||||
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). It's a Russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search suff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottleneck definitely is not at the speed of those requests.
|
|
||||||
|
|
||||||
For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
|
|
||||||
|
|
||||||
```json
|
|
||||||
[
|
|
||||||
{
|
|
||||||
"id":"Lorna Shore",
|
|
||||||
"label":"Lorna Shore",
|
|
||||||
"value":"Lorna Shore",
|
|
||||||
"category":"Исполнители",
|
|
||||||
"image":"https://39s.musify.club/img/68/9561484/25159224.jpg",
|
|
||||||
"url":"/artist/lorna-shore-59611"
|
|
||||||
},
|
|
||||||
{"id":"Immortal","label":"Lorna Shore - Immortal (2020)","value":"Immortal","category":"Релизы","image":"https://39s-a.musify.club/img/70/20335517/52174338.jpg","url":"/release/lorna-shore-immortal-2020-1241300"},
|
|
||||||
{"id":"Immortal","label":"Lorna Shore - Immortal","value":"Immortal","category":"Треки","image":"","url":"/track/lorna-shore-immortal-12475071"}
|
|
||||||
]
|
|
||||||
```
|
|
||||||
|
|
||||||
This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
|
|
||||||
|
|
||||||
- call the api with the query being the track name
|
|
||||||
- parse the json response to an object
|
|
||||||
- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
|
|
||||||
- If they match get the download links and cache them.
|
|
||||||
|
|
||||||
### Youtube
|
|
||||||
|
|
||||||
Herte the **isrc** plays a huge role. You probably know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
|
|
||||||
|
|
||||||
Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
|
|
||||||
|
|
||||||
For searching, as well as for downloading I use the programm `youtube-dl`, which also has a programming interface for python.
|
|
||||||
|
|
||||||
There are two bottlenecks with this approach though:
|
|
||||||
1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
|
|
||||||
2. Ofthen musicbrainz just doesn't give the isrc for some songs.
|
|
||||||
|
|
||||||
|
|
||||||
## Lyrics
|
|
||||||
|
|
||||||
To get the Lyrics, I scrape them, and put those in the USLT ID3 Tags of for example mp3 files. Unfortunately some players, like the one I use, Rhythmbox don't support USLT Lyrics. So I created an Plugin for Rhythmbox. You can find it here: [https://github.com/HeIIow2/rythmbox-id3-lyrics-support](https://github.com/HeIIow2/rythmbox-id3-lyrics-support).
|
|
||||||
|
|
||||||
### Genius
|
|
||||||
|
|
||||||
For the lyrics source the page [https://genius.com/](https://genius.com/) is easily sufficient. It has most songs. Some songs are not present though, but that is fine, because the lyrics are optional anyways.
|
|
||||||
|
|
||||||
|
|
||||||
[i10]: https://github.com/HeIIow2/music-downloader/issues/10
|
[i10]: https://github.com/HeIIow2/music-downloader/issues/10
|
||||||
[i2]: https://github.com/HeIIow2/music-downloader/issues/2
|
[i2]: https://github.com/HeIIow2/music-downloader/issues/2
|
||||||
[mb]: https://musicbrainz.org/
|
|
||||||
|
|||||||
@@ -0,0 +1,88 @@
|
|||||||
|
# music_kraken.objects
|
||||||
|
|
||||||
|
## DatabaseObject
|
||||||
|
|
||||||
|
[music_kraken.objects.DatabaseObject](../src/music_kraken/objects/parents.py)
|
||||||
|
|
||||||
|
This is a parent object, which most Music-Objects inherit from. It provides the **functionality** to:
|
||||||
|
|
||||||
|
- autogenerate id's *(UUID)*, if not passed in the constructur.
|
||||||
|
- [merge](#databaseobjectmerge) the data of another instance of the same time in self.
|
||||||
|
- Check if two different instances of the same type represent the same data, using `__eq__`.
|
||||||
|
|
||||||
|
Additionally it provides an **Interface** to:
|
||||||
|
|
||||||
|
- define the attributes used to [merge](#databaseobjectmerge).
|
||||||
|
- define the attribuse and values used to check for equal data. *(used in `__eq__` and in the merge)*
|
||||||
|
- get the id3 [metadata](#metadata).
|
||||||
|
- get all [options](#options) *(used in searching from e.g. the command line)*
|
||||||
|
|
||||||
|
### DatabaseObject.merge()
|
||||||
|
|
||||||
|
To merge the data of two instances of the same type, the attributes defined in `DatabaseObject.COLLECTION_ATTRIBUTES` and `SIMPLE_ATTRIBUTES` are used.
|
||||||
|
|
||||||
|
The simple attributes just get carried from the other instance, to the self instance.
|
||||||
|
|
||||||
|
The collection attributes appends all elements from other.collection to self.collection, but ofc [checks if already exists](#collection).
|
||||||
|
|
||||||
|
## Collection
|
||||||
|
|
||||||
|
[music_kraken.objects.Collection](../src/music_kraken/objects/collection.py)
|
||||||
|
|
||||||
|
This is an object, which acts as a list. You can save instaces of a subclass of [DatabaseObject](#databaseobject).
|
||||||
|
|
||||||
|
Then you can for example append a new Object. The difference to a normal list is, that if you have two different objects that both represent the same data, it doesn't get added, but all data gets [merged](#databaseobjectmerge) into the existing Object instead.
|
||||||
|
|
||||||
|
For example, you have two different Artist-Objects, where both have one source in common. The one Artist-Object already is in the Collection. The other artist object is passed in the append command.
|
||||||
|
In this case it doesn't simply add the artist object to the collection, but modifies the already existing Artist-Object, adding all attributes the new artist object has, and then discards the other object.
|
||||||
|
|
||||||
|
```python
|
||||||
|
artist_collection = Collection(element_type=Artist)
|
||||||
|
|
||||||
|
# adds the artist to the list (len 1)
|
||||||
|
artist_collection.append(artist_1)
|
||||||
|
|
||||||
|
# detects artist 2 has a mutual source
|
||||||
|
# thus not adding but mergin (len 1)
|
||||||
|
artist_collection.appent(artist_2)
|
||||||
|
```
|
||||||
|
|
||||||
|
Function | Explanation
|
||||||
|
---|---
|
||||||
|
`append()` | appends an object to the collection
|
||||||
|
`extend()` | appends a list of objects to the collection
|
||||||
|
`__len__()` | gets the ammount of objects in collection
|
||||||
|
`shallow_list` | gets a shallow copy of the list `_data` the objects are contained in
|
||||||
|
`sort()` | takes the same arguments than `list.sort`, and does the same
|
||||||
|
`__iter__()` | allows you to use collections e.g. a for loop
|
||||||
|
|
||||||
|
## Options
|
||||||
|
|
||||||
|
## Metadata
|
||||||
|
|
||||||
|
## Song
|
||||||
|
|
||||||
|
This object inherits from [DatabaseObject](#databaseobject) and implements all its interfaces.
|
||||||
|
|
||||||
|
It has handful attributes, where half of em are self-explanatory, like `title` or `genre`. The ones like `isrc` are only relevant to you, if you know what it is, so I won't elaborate on it.
|
||||||
|
|
||||||
|
Interesting is the `date`. It uses a custom class. More on that [here](#music_krakenid3timestamp).
|
||||||
|
|
||||||
|
## ID3Timestamp
|
||||||
|
|
||||||
|
For multiple Reasons I don't use the default `datetime.datetime` class.
|
||||||
|
|
||||||
|
The most important reason is, that you need to pass in at least year, month and day. For every other values there are default values, that are indistinguishable from values that are directly passed in. But I need optional values. The ID3 standart allows default values. Additionally `datetime.datetime` is immutable, thus I can't inherint all the methods. Sorry.
|
||||||
|
|
||||||
|
Anyway you can create those custom objects easily.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from music_kraken import ID3Timestamp
|
||||||
|
|
||||||
|
# returns an instance of ID3Timestamp with the current time
|
||||||
|
ID3Timestamp.now()
|
||||||
|
|
||||||
|
# returns an instance of ID3Timestamp with the given values
|
||||||
|
# all values are optional if unknown
|
||||||
|
ID3Timestamp(year=1986, month=3, day=1, hour=12, minute=30, second=6)
|
||||||
|
```
|
||||||
@@ -0,0 +1,285 @@
|
|||||||
|
# Old implementation
|
||||||
|
|
||||||
|
> IF U USE THIS NOW YOU ARE DUMB *no offense thoug*. IT ISN'T FINISHED AND THE STUFF YOU CODE NOW WILL BE BROKEN TOMORROW
|
||||||
|
> SOON YOU CAN THOUGH
|
||||||
|
|
||||||
|
If you want to use this project, or parts from it in your own projects from it,
|
||||||
|
make sure to be familiar with [Python Modules](https://docs.python.org/3/tutorial/modules.html).
|
||||||
|
Further and better documentation including code examples are yet to come, so here is the rough
|
||||||
|
module structure for now. (Should be up-to-date, but no guarantees)
|
||||||
|
|
||||||
|
If you simply want to run the builtin minimal cli just do this:
|
||||||
|
```python
|
||||||
|
from music_kraken import cli
|
||||||
|
|
||||||
|
cli()
|
||||||
|
```
|
||||||
|
|
||||||
|
### Search for Metadata
|
||||||
|
|
||||||
|
The whole program takes the data it processes further from the cache, a sqlite database.
|
||||||
|
So before you can do anything, you will need to fill it with the songs you want to download (*or create song objects manually, but more on that later*).
|
||||||
|
|
||||||
|
For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type`. The `id` corresponds to either
|
||||||
|
- an artist
|
||||||
|
- a release group
|
||||||
|
- a release
|
||||||
|
- a recording/track).
|
||||||
|
|
||||||
|
To get this info, you first have to initialize a search object (`music_kraken.MetadataSearch`).
|
||||||
|
|
||||||
|
```python
|
||||||
|
search_object = music_kraken.MetadataSearch()
|
||||||
|
```
|
||||||
|
|
||||||
|
Then you need an initial "text search" to get some options you can choose from. For
|
||||||
|
this you can either specify artists releases and whatever directly with one of the following functions:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# you can directly specify artist, release group, release or recording/track
|
||||||
|
multiple_options = search_object.search_from_text(artist=input("input the name of the artist: "))
|
||||||
|
# you can specify a query see the simple integrated cli on how to use the query
|
||||||
|
multiple_options = search_object.search_from_query(query=input("input the query: "))
|
||||||
|
```
|
||||||
|
|
||||||
|
Both methods return an instance of `MultipleOptions`, which can be directly converted to a string.
|
||||||
|
|
||||||
|
```python
|
||||||
|
print(multiple_options)
|
||||||
|
```
|
||||||
|
|
||||||
|
After the first "*text search*" you can either again search the same way as before,
|
||||||
|
or you can further explore one of the options from the previous search.
|
||||||
|
To explore and select one options from `MultipleOptions`, simply call `MetadataSearch.choose(self, index: int)`.
|
||||||
|
The index represents the number in the previously returned instance of MultipleOptions.
|
||||||
|
The selected Option will be selected and can be downloaded in the next step.
|
||||||
|
|
||||||
|
*Thus, this has to be done **after either search_from_text or search_from_query***
|
||||||
|
|
||||||
|
```python
|
||||||
|
# choosing the best matching band
|
||||||
|
multiple_options = search_object.choose(0)
|
||||||
|
# choosing the first ever release group of this band
|
||||||
|
multiple_options = search_object.choose(1)
|
||||||
|
# printing out the current options
|
||||||
|
print(multiple_options)
|
||||||
|
```
|
||||||
|
|
||||||
|
This process can be repeated indefinitely (until you run out of memory).
|
||||||
|
A search history is kept in the Search instance. You could go back to
|
||||||
|
the previous search (without any loading time) like this:
|
||||||
|
|
||||||
|
```python
|
||||||
|
multiple_options = search_object.get_previous_options()
|
||||||
|
```
|
||||||
|
|
||||||
|
### Downloading Metadata / Filling up the Cache
|
||||||
|
|
||||||
|
You can download following metadata:
|
||||||
|
- an artist (the whole discography)
|
||||||
|
- a release group
|
||||||
|
- a release
|
||||||
|
- a track/recording
|
||||||
|
|
||||||
|
If you got an instance of `MetadataSearch`, like I elaborated [previously](#search-for-metadata), downloading every piece of metadata from the currently selected Option is really quite easy.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from music_kraken import fetch_metadata_from_search
|
||||||
|
|
||||||
|
# this is it :)
|
||||||
|
music_kraken.fetch_metadata_from_search(search_object)
|
||||||
|
```
|
||||||
|
|
||||||
|
If you already know what you want to download you can skip the search instance and simply do the following.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from music_kraken import fetch_metadata
|
||||||
|
|
||||||
|
# might change and break after I add multiple metadata sources which I will
|
||||||
|
|
||||||
|
fetch_metadata(id_=musicbrainz_id, type=metadata_type)
|
||||||
|
```
|
||||||
|
The option type is a string (*I'm sorry for not making it an enum I know its a bad pratice*), which can
|
||||||
|
have following values:
|
||||||
|
- 'artist'
|
||||||
|
- 'release_group'
|
||||||
|
- 'release'
|
||||||
|
- 'recording'
|
||||||
|
|
||||||
|
**PAY ATTENTION TO TYPOS, IT'S CASE SENSITIVE**
|
||||||
|
|
||||||
|
The musicbrainz id is just the id of the object from musicbrainz.
|
||||||
|
|
||||||
|
After following those steps, it might take a couple seconds/minutes to execute, but then the Cache will be filled.
|
||||||
|
|
||||||
|
|
||||||
|
### Cache / Temporary Database
|
||||||
|
|
||||||
|
All the data, the functions that download stuff use, can be gotten from the temporary database / cache.
|
||||||
|
The cache can be simply used like this:
|
||||||
|
|
||||||
|
```python
|
||||||
|
music_kraken.test_db
|
||||||
|
```
|
||||||
|
|
||||||
|
When fetching any song data from the cache, you will get it as Song
|
||||||
|
object (music_kraken.Song). There are multiple methods
|
||||||
|
to get different sets of Songs. The names explain the methods pretty
|
||||||
|
well:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from music_kraken import cache
|
||||||
|
|
||||||
|
# gets a single track specified by the id
|
||||||
|
cache.get_track_metadata(id: str)
|
||||||
|
|
||||||
|
# gets a list of tracks.
|
||||||
|
cache.get_tracks_to_download()
|
||||||
|
cache.get_tracks_without_src()
|
||||||
|
cache.get_tracks_without_isrc()
|
||||||
|
cache.get_tracks_without_filepath()
|
||||||
|
```
|
||||||
|
|
||||||
|
The id always is a musicbrainz id and distinct for every track.
|
||||||
|
|
||||||
|
### Setting the Target
|
||||||
|
|
||||||
|
By default the music downloader doesn't know where to save the music file, if downloaded. To set those variables (the directory to save the file in and the filepath), it is enough to run one single command:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from music_kraken import set_target
|
||||||
|
|
||||||
|
# adds file path, file directory and the genre to the database
|
||||||
|
set_target(genre="some test genre")
|
||||||
|
```
|
||||||
|
|
||||||
|
The concept of genres is too loose, to definitely say, this band exclusively plays this genre, or this song is this genre. This doesn't work manually, this will never work automatically. Thus, I've decided to just use the genre as category, to sort the artists and songs by. Most Music players support that.
|
||||||
|
|
||||||
|
As a result of this decision you will have to pass the genre in this function.
|
||||||
|
|
||||||
|
### Get Audio
|
||||||
|
|
||||||
|
This is most likely the most useful and unique feature of this Project. If the cache is filled, you can get audio sources for the songs you only have the metadata, and download them. This works for most songs. I'd guess for about 97% (?)
|
||||||
|
|
||||||
|
First of you will need a List of song objects `music_kraken.Song`. As [mentioned above](#cache--temporary-database), you could get a list like that from the cache.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Here is an Example
|
||||||
|
from music_kraken import (
|
||||||
|
cache,
|
||||||
|
fetch_sources,
|
||||||
|
fetch_audios
|
||||||
|
)
|
||||||
|
|
||||||
|
# scanning pages, searching for a download and storing results
|
||||||
|
fetch_sources(cache.get_tracks_without_src())
|
||||||
|
|
||||||
|
# downloading all previously fetched sources to previously defined targets
|
||||||
|
fetch_audios(cache.get_tracks_to_download())
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
*Note:*
|
||||||
|
To download audio two cases have to be met:
|
||||||
|
1. [The target](#setting-the-target) has to be set beforehand
|
||||||
|
2. The sources have to be fetched beforehand
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Metadata
|
||||||
|
|
||||||
|
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz][mb]. This is a result of them being a website with a large Database spanning over all Genres.
|
||||||
|
|
||||||
|
### Musicbrainz
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
To fetch from [Musicbrainz][mb] we first have to know what to fetch. A good start is to get an input query, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
||||||
|
|
||||||
|
If the following chosen element is an artist, its discography + a couple tracks are printed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
||||||
|
|
||||||
|
For now, it doesn't if the discography or tracklist is chosen.
|
||||||
|
|
||||||
|
### Metadata to fetch
|
||||||
|
|
||||||
|
I orient on which metadata to download on the keys in `mutagen.EasyID3`. The following I fetch and tag the MP3 with:
|
||||||
|
- title
|
||||||
|
- artist
|
||||||
|
- albumartist
|
||||||
|
- tracknumber
|
||||||
|
- albumsort can sort albums cronological
|
||||||
|
- titlesort is just set to the tracknumber to sort by track order to sort correctly
|
||||||
|
- isrc
|
||||||
|
- musicbrainz_artistid
|
||||||
|
- musicbrainz_albumid
|
||||||
|
- musicbrainz_albumartistid
|
||||||
|
- musicbrainz_albumstatus
|
||||||
|
- language
|
||||||
|
- musicbrainz_albumtype
|
||||||
|
- releasecountry
|
||||||
|
- barcode
|
||||||
|
|
||||||
|
#### albumsort/titlesort
|
||||||
|
|
||||||
|
Those Tags are for the musicplayer to not sort for Example the albums of a band alphabetically, but in another way. I set it just to chronological order
|
||||||
|
|
||||||
|
#### isrc
|
||||||
|
|
||||||
|
This is the **international standart release code**. With this a track can be identified 99% of the time, if it is known and the website has a search api for that. Obviously this will get important later.
|
||||||
|
|
||||||
|
## Download
|
||||||
|
|
||||||
|
Now that the metadata is downloaded and cached, download sources need to be sound, because one can't listen to metadata. Granted it would be amazing if that would be possible.
|
||||||
|
|
||||||
|
### Musify
|
||||||
|
|
||||||
|
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). It's a Russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search suff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottleneck definitely is not at the speed of those requests.
|
||||||
|
|
||||||
|
For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
|
||||||
|
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"id":"Lorna Shore",
|
||||||
|
"label":"Lorna Shore",
|
||||||
|
"value":"Lorna Shore",
|
||||||
|
"category":"Исполнители",
|
||||||
|
"image":"https://39s.musify.club/img/68/9561484/25159224.jpg",
|
||||||
|
"url":"/artist/lorna-shore-59611"
|
||||||
|
},
|
||||||
|
{"id":"Immortal","label":"Lorna Shore - Immortal (2020)","value":"Immortal","category":"Релизы","image":"https://39s-a.musify.club/img/70/20335517/52174338.jpg","url":"/release/lorna-shore-immortal-2020-1241300"},
|
||||||
|
{"id":"Immortal","label":"Lorna Shore - Immortal","value":"Immortal","category":"Треки","image":"","url":"/track/lorna-shore-immortal-12475071"}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
|
||||||
|
|
||||||
|
- call the api with the query being the track name
|
||||||
|
- parse the json response to an object
|
||||||
|
- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
|
||||||
|
- If they match get the download links and cache them.
|
||||||
|
|
||||||
|
### Youtube
|
||||||
|
|
||||||
|
Herte the **isrc** plays a huge role. You probably know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
|
||||||
|
|
||||||
|
Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
|
||||||
|
|
||||||
|
For searching, as well as for downloading I use the programm `youtube-dl`, which also has a programming interface for python.
|
||||||
|
|
||||||
|
There are two bottlenecks with this approach though:
|
||||||
|
1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
|
||||||
|
2. Ofthen musicbrainz just doesn't give the isrc for some songs.
|
||||||
|
|
||||||
|
|
||||||
|
## Lyrics
|
||||||
|
|
||||||
|
To get the Lyrics, I scrape them, and put those in the USLT ID3 Tags of for example mp3 files. Unfortunately some players, like the one I use, Rhythmbox don't support USLT Lyrics. So I created an Plugin for Rhythmbox. You can find it here: [https://github.com/HeIIow2/rythmbox-id3-lyrics-support](https://github.com/HeIIow2/rythmbox-id3-lyrics-support).
|
||||||
|
|
||||||
|
### Genius
|
||||||
|
|
||||||
|
For the lyrics source the page [https://genius.com/](https://genius.com/) is easily sufficient. It has most songs. Some songs are not present though, but that is fine, because the lyrics are optional anyways.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
[mb]: https://musicbrainz.org/
|
||||||
@@ -1,4 +1,4 @@
|
|||||||
from music_kraken import objects
|
from music_kraken import objects, recurse
|
||||||
|
|
||||||
import pycountry
|
import pycountry
|
||||||
|
|
||||||
@@ -41,6 +41,9 @@ song = objects.Song(
|
|||||||
objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
|
objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
|
||||||
"https://www.metal-archives.com/bands/I%27m_in_a_Coffin/127727"
|
"https://www.metal-archives.com/bands/I%27m_in_a_Coffin/127727"
|
||||||
)
|
)
|
||||||
|
],
|
||||||
|
label_list=[
|
||||||
|
objects.Label(name="Depressive records")
|
||||||
]
|
]
|
||||||
),
|
),
|
||||||
objects.Artist(name="some_split_artist")
|
objects.Artist(name="some_split_artist")
|
||||||
@@ -55,8 +58,6 @@ song = objects.Song(
|
|||||||
],
|
],
|
||||||
)
|
)
|
||||||
|
|
||||||
print(song.option_string)
|
song.compile()
|
||||||
for album in song.album_collection:
|
|
||||||
print(album.option_string)
|
print(song.options)
|
||||||
for artist in song.main_artist_collection:
|
|
||||||
print(artist.option_string)
|
|
||||||
|
|||||||
@@ -5,9 +5,11 @@ from music_kraken.pages import (
|
|||||||
EncyclopaediaMetallum
|
EncyclopaediaMetallum
|
||||||
)
|
)
|
||||||
|
|
||||||
results = EncyclopaediaMetallum.search_by_query("#a Only Smile")
|
|
||||||
|
results = EncyclopaediaMetallum.search_by_query("#a Ghost Bath")
|
||||||
|
|
||||||
artist = results[0]
|
artist = results[0]
|
||||||
artist: objects.Artist = EncyclopaediaMetallum.fetch_details(artist)
|
artist: objects.Artist = EncyclopaediaMetallum.fetch_details(artist)
|
||||||
|
|
||||||
print(artist.options)
|
print(artist.options)
|
||||||
print()
|
print()
|
||||||
|
|||||||
@@ -4,7 +4,9 @@ from . import (
|
|||||||
source,
|
source,
|
||||||
parents,
|
parents,
|
||||||
formatted_text,
|
formatted_text,
|
||||||
album
|
album,
|
||||||
|
option,
|
||||||
|
collection
|
||||||
)
|
)
|
||||||
|
|
||||||
MusicObject = parents.DatabaseObject
|
MusicObject = parents.DatabaseObject
|
||||||
@@ -28,3 +30,6 @@ AlbumStatus = album.AlbumStatus
|
|||||||
Album = song.Album
|
Album = song.Album
|
||||||
|
|
||||||
FormattedText = formatted_text.FormattedText
|
FormattedText = formatted_text.FormattedText
|
||||||
|
|
||||||
|
Options = option.Options
|
||||||
|
Collection = collection.Collection
|
||||||
|
|||||||
@@ -22,4 +22,5 @@ class AlbumType(Enum):
|
|||||||
LIVE_ALBUM = "Live Album"
|
LIVE_ALBUM = "Live Album"
|
||||||
COMPILATION_ALBUM = "Compilation Album"
|
COMPILATION_ALBUM = "Compilation Album"
|
||||||
MIXTAPE = "Mixtape"
|
MIXTAPE = "Mixtape"
|
||||||
|
DEMO = "Demo"
|
||||||
OTHER = "Other"
|
OTHER = "Other"
|
||||||
|
|||||||
@@ -0,0 +1,110 @@
|
|||||||
|
from collections import defaultdict
|
||||||
|
from typing import Dict, List, Optional
|
||||||
|
import weakref
|
||||||
|
|
||||||
|
from .parents import DatabaseObject
|
||||||
|
|
||||||
|
"""
|
||||||
|
This is a cache for the objects, that et pulled out of the database.
|
||||||
|
This is necessary, to not have duplicate objects with the same id.
|
||||||
|
|
||||||
|
Using a cache that maps the ojects to their id has multiple benefits:
|
||||||
|
- if you modify the object at any point, all objects with the same id get modified *(copy by reference)*
|
||||||
|
- less ram usage
|
||||||
|
- to further decrease ram usage I only store weak refs and not a strong reference, for the gc to still work
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class ObjectCache:
|
||||||
|
"""
|
||||||
|
ObjectCache is a cache for the objects retrieved from a database.
|
||||||
|
It maps each object to its id and uses weak references to manage its memory usage.
|
||||||
|
Using a cache for these objects provides several benefits:
|
||||||
|
|
||||||
|
- Modifying an object updates all objects with the same id (due to copy by reference)
|
||||||
|
- Reduced memory usage
|
||||||
|
|
||||||
|
:attr object_to_id: Dictionary that maps DatabaseObjects to their id.
|
||||||
|
:attr weakref_map: Dictionary that uses weak references to DatabaseObjects as keys and their id as values.
|
||||||
|
|
||||||
|
:method exists: Check if a DatabaseObject already exists in the cache.
|
||||||
|
:method append: Add a DatabaseObject to the cache if it does not already exist.
|
||||||
|
:method extent: Add a list of DatabaseObjects to the cache.
|
||||||
|
:method remove: Remove a DatabaseObject from the cache by its id.
|
||||||
|
:method get: Retrieve a DatabaseObject from the cache by its id. """
|
||||||
|
object_to_id: Dict[str, DatabaseObject]
|
||||||
|
weakref_map: Dict[weakref.ref, str]
|
||||||
|
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self.object_to_id = dict()
|
||||||
|
self.weakref_map = defaultdict()
|
||||||
|
|
||||||
|
def exists(self, database_object: DatabaseObject) -> bool:
|
||||||
|
"""
|
||||||
|
Check if a DatabaseObject with the same id already exists in the cache.
|
||||||
|
|
||||||
|
:param database_object: The DatabaseObject to check for.
|
||||||
|
:return: True if the DatabaseObject exists, False otherwise.
|
||||||
|
"""
|
||||||
|
if database_object.dynamic:
|
||||||
|
return True
|
||||||
|
return database_object.id in self.object_to_id
|
||||||
|
|
||||||
|
def on_death(self, weakref_: weakref.ref) -> None:
|
||||||
|
"""
|
||||||
|
Callback function that gets triggered when the reference count of a DatabaseObject drops to 0.
|
||||||
|
This function removes the DatabaseObject from the cache.
|
||||||
|
|
||||||
|
:param weakref_: The weak reference of the DatabaseObject that has been garbage collected.
|
||||||
|
"""
|
||||||
|
data_id = self.weakref_map.pop(weakref_)
|
||||||
|
self.object_to_id.pop(data_id)
|
||||||
|
|
||||||
|
def get_weakref(self, database_object: DatabaseObject) -> weakref.ref:
|
||||||
|
return weakref.ref(database_object, self.on_death)
|
||||||
|
|
||||||
|
|
||||||
|
def append(self, database_object: DatabaseObject) -> bool:
|
||||||
|
"""
|
||||||
|
Add a DatabaseObject to the cache.
|
||||||
|
|
||||||
|
:param database_object: The DatabaseObject to add to the cache.
|
||||||
|
:return: True if the DatabaseObject already exists in the cache, False otherwise.
|
||||||
|
"""
|
||||||
|
if self.exists(database_object):
|
||||||
|
return True
|
||||||
|
|
||||||
|
self.weakref_map[weakref.ref(database_object, self.on_death)] = database_object.id
|
||||||
|
self.object_to_id[database_object.id] = database_object
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
def extent(self, database_object_list: List[DatabaseObject]):
|
||||||
|
"""
|
||||||
|
adjacent to the extent method of list, this appends n Object
|
||||||
|
"""
|
||||||
|
for database_object in database_object_list:
|
||||||
|
self.append(database_object)
|
||||||
|
|
||||||
|
def remove(self, _id: str):
|
||||||
|
"""
|
||||||
|
Remove a DatabaseObject from the cache.
|
||||||
|
|
||||||
|
:param _id: The id of the DatabaseObject to remove from the cache.
|
||||||
|
"""
|
||||||
|
data = self.object_to_id.get(_id)
|
||||||
|
if data:
|
||||||
|
self.weakref_map.pop(weakref.ref(data))
|
||||||
|
self.object_to_id.pop(_id)
|
||||||
|
|
||||||
|
def __getitem__(self, item) -> Optional[DatabaseObject]:
|
||||||
|
"""
|
||||||
|
this returns the data obj
|
||||||
|
:param item: the id of the music object
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.object_to_id.get(item)
|
||||||
|
|
||||||
|
def get(self, _id: str) -> Optional[DatabaseObject]:
|
||||||
|
return self.__getitem__(_id)
|
||||||
@@ -33,6 +33,7 @@ class Collection:
|
|||||||
```
|
```
|
||||||
"""
|
"""
|
||||||
self._attribute_to_object_map: Dict[str, Dict[object, DatabaseObject]] = defaultdict(dict)
|
self._attribute_to_object_map: Dict[str, Dict[object, DatabaseObject]] = defaultdict(dict)
|
||||||
|
self._used_ids: set = set()
|
||||||
|
|
||||||
if data is not None:
|
if data is not None:
|
||||||
self.extend(data, merge_on_conflict=True)
|
self.extend(data, merge_on_conflict=True)
|
||||||
@@ -46,12 +47,27 @@ class Collection:
|
|||||||
continue
|
continue
|
||||||
|
|
||||||
self._attribute_to_object_map[name][value] = element
|
self._attribute_to_object_map[name][value] = element
|
||||||
|
|
||||||
|
self._used_ids.add(element.id)
|
||||||
|
|
||||||
|
def unmap_element(self, element: DatabaseObject):
|
||||||
|
for name, value in element.indexing_values:
|
||||||
|
if value is None:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if value in self._attribute_to_object_map[name]:
|
||||||
|
if element is self._attribute_to_object_map[name][value]:
|
||||||
|
try:
|
||||||
|
self._attribute_to_object_map[name].pop(value)
|
||||||
|
except KeyError:
|
||||||
|
pass
|
||||||
|
|
||||||
def append(self, element: DatabaseObject, merge_on_conflict: bool = True):
|
def append(self, element: DatabaseObject, merge_on_conflict: bool = True, merge_into_existing: bool = True) -> bool:
|
||||||
"""
|
"""
|
||||||
:param element:
|
:param element:
|
||||||
:param merge_on_conflict:
|
:param merge_on_conflict:
|
||||||
:return:
|
:param merge_into_existing:
|
||||||
|
:return did_not_exist:
|
||||||
"""
|
"""
|
||||||
|
|
||||||
# if the element type has been defined in the initializer it checks if the type matches
|
# if the element type has been defined in the initializer it checks if the type matches
|
||||||
@@ -60,17 +76,30 @@ class Collection:
|
|||||||
|
|
||||||
for name, value in element.indexing_values:
|
for name, value in element.indexing_values:
|
||||||
if value in self._attribute_to_object_map[name]:
|
if value in self._attribute_to_object_map[name]:
|
||||||
|
existing_object = self._attribute_to_object_map[name][value]
|
||||||
|
|
||||||
if merge_on_conflict:
|
if merge_on_conflict:
|
||||||
# if the object does already exist
|
# if the object does already exist
|
||||||
# thus merging and don't add it afterwards
|
# thus merging and don't add it afterwards
|
||||||
existing_object = self._attribute_to_object_map[name][value]
|
if merge_into_existing:
|
||||||
existing_object.merge(element)
|
existing_object.merge(element)
|
||||||
# in case any relevant data has been added (e.g. it remaps the old object)
|
# in case any relevant data has been added (e.g. it remaps the old object)
|
||||||
self.map_element(existing_object)
|
self.map_element(existing_object)
|
||||||
return
|
else:
|
||||||
|
element.merge(existing_object)
|
||||||
|
|
||||||
|
exists_at = self._data.index(existing_object)
|
||||||
|
self._data[exists_at] = element
|
||||||
|
|
||||||
|
self.unmap_element(existing_object)
|
||||||
|
self.map_element(element)
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
self._data.append(element)
|
self._data.append(element)
|
||||||
self.map_element(element)
|
self.map_element(element)
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
||||||
def extend(self, element_list: Iterable[DatabaseObject], merge_on_conflict: bool = True):
|
def extend(self, element_list: Iterable[DatabaseObject], merge_on_conflict: bool = True):
|
||||||
for element in element_list:
|
for element in element_list:
|
||||||
|
|||||||
@@ -10,6 +10,10 @@ https://pandoc.org/installing.html
|
|||||||
|
|
||||||
|
|
||||||
class FormattedText:
|
class FormattedText:
|
||||||
|
"""
|
||||||
|
the self.html value should be saved to the database
|
||||||
|
"""
|
||||||
|
|
||||||
doc = None
|
doc = None
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
@@ -39,35 +43,38 @@ class FormattedText:
|
|||||||
|
|
||||||
def get_markdown(self) -> str:
|
def get_markdown(self) -> str:
|
||||||
if self.doc is None:
|
if self.doc is None:
|
||||||
return None
|
return ""
|
||||||
return pandoc.write(self.doc, format="markdown").strip()
|
return pandoc.write(self.doc, format="markdown").strip()
|
||||||
|
|
||||||
def get_html(self) -> str:
|
def get_html(self) -> str:
|
||||||
if self.doc is None:
|
if self.doc is None:
|
||||||
return None
|
return ""
|
||||||
return pandoc.write(self.doc, format="html").strip()
|
return pandoc.write(self.doc, format="html").strip()
|
||||||
|
|
||||||
def get_plaintext(self) -> str:
|
def get_plaintext(self) -> str:
|
||||||
if self.doc is None:
|
if self.doc is None:
|
||||||
return None
|
return ""
|
||||||
return pandoc.write(self.doc, format="plain").strip()
|
return pandoc.write(self.doc, format="plain").strip()
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def json(self) -> str:
|
def is_empty(self) -> bool:
|
||||||
if self.doc is None:
|
return self.doc is None
|
||||||
return None
|
|
||||||
return pandoc.write(self.doc, format="json")
|
def __eq__(self, other) -> False:
|
||||||
|
if type(other) != type(self):
|
||||||
|
return False
|
||||||
|
if self.is_empty and other.is_empty:
|
||||||
|
return True
|
||||||
|
|
||||||
|
return self.doc == other.doc
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
plaintext = property(fget=get_plaintext, fset=set_plaintext)
|
plaintext = property(fget=get_plaintext, fset=set_plaintext)
|
||||||
markdown = property(fget=get_markdown, fset=set_markdown)
|
markdown = property(fget=get_markdown, fset=set_markdown)
|
||||||
html = property(fget=get_html, fset=set_html)
|
html = property(fget=get_html, fset=set_html)
|
||||||
|
|
||||||
|
|
||||||
class NotesAttributes:
|
|
||||||
def __init__(self) -> None:
|
|
||||||
pass
|
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
if __name__ == "__main__":
|
||||||
_plaintext = """
|
_plaintext = """
|
||||||
World of Work
|
World of Work
|
||||||
|
|||||||
@@ -1,14 +1,19 @@
|
|||||||
from typing import List
|
from typing import List
|
||||||
|
from collections import defaultdict
|
||||||
import pycountry
|
import pycountry
|
||||||
|
|
||||||
from .parents import DatabaseObject
|
from .parents import DatabaseObject
|
||||||
from .source import Source, SourceCollection
|
from .source import Source, SourceCollection
|
||||||
from .metadata import Metadata
|
|
||||||
from .formatted_text import FormattedText
|
from .formatted_text import FormattedText
|
||||||
|
|
||||||
|
|
||||||
class Lyrics(DatabaseObject):
|
class Lyrics(DatabaseObject):
|
||||||
|
COLLECTION_ATTRIBUTES = ("source_collection",)
|
||||||
|
SIMPLE_ATTRIBUTES = {
|
||||||
|
"text": FormattedText(),
|
||||||
|
"language": None
|
||||||
|
}
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
text: FormattedText,
|
text: FormattedText,
|
||||||
@@ -18,9 +23,9 @@ class Lyrics(DatabaseObject):
|
|||||||
source_list: List[Source] = None,
|
source_list: List[Source] = None,
|
||||||
**kwargs
|
**kwargs
|
||||||
) -> None:
|
) -> None:
|
||||||
DatabaseObject.__init__(self, _id=_id, dynamic=dynamic)
|
DatabaseObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
||||||
|
|
||||||
self.text: FormattedText = text
|
self.text: FormattedText = text or FormattedText()
|
||||||
self.language: pycountry.Languages = language
|
self.language: pycountry.Languages = language
|
||||||
|
|
||||||
self.source_collection: SourceCollection = SourceCollection(source_list)
|
self.source_collection: SourceCollection = SourceCollection(source_list)
|
||||||
|
|||||||
@@ -154,6 +154,8 @@ class ID3Timestamp:
|
|||||||
return self.date_obj >= other.date_obj
|
return self.date_obj >= other.date_obj
|
||||||
|
|
||||||
def __eq__(self, other):
|
def __eq__(self, other):
|
||||||
|
if type(other) != type(self):
|
||||||
|
return False
|
||||||
return self.date_obj == other.date_obj
|
return self.date_obj == other.date_obj
|
||||||
|
|
||||||
def get_time_format(self) -> str:
|
def get_time_format(self) -> str:
|
||||||
|
|||||||
@@ -21,8 +21,10 @@ class Options:
|
|||||||
|
|
||||||
return self._data[index].options
|
return self._data[index].options
|
||||||
|
|
||||||
def __getitem__(self, item: int) -> 'Options':
|
def __getitem__(self, item: int) -> 'DatabaseObject':
|
||||||
if type(item) != int:
|
if type(item) != int:
|
||||||
raise TypeError("Key needs to be an Integer")
|
raise TypeError("Key needs to be an Integer")
|
||||||
|
if item >= len(self._data):
|
||||||
|
raise ValueError("Index out of bounds")
|
||||||
|
|
||||||
return self.get_next_options(item)
|
return self._data[item]
|
||||||
|
|||||||
@@ -11,15 +11,18 @@ from .option import Options
|
|||||||
|
|
||||||
class DatabaseObject:
|
class DatabaseObject:
|
||||||
COLLECTION_ATTRIBUTES: tuple = tuple()
|
COLLECTION_ATTRIBUTES: tuple = tuple()
|
||||||
SIMPLE_ATTRIBUTES: tuple = tuple()
|
SIMPLE_ATTRIBUTES: dict = dict()
|
||||||
|
|
||||||
def __init__(self, _id: str = None, dynamic: bool = False, **kwargs) -> None:
|
def __init__(self, _id: str = None, dynamic: bool = False, **kwargs) -> None:
|
||||||
|
self.automatic_id: bool = False
|
||||||
|
|
||||||
if _id is None and not dynamic:
|
if _id is None and not dynamic:
|
||||||
"""
|
"""
|
||||||
generates a random UUID
|
generates a random UUID
|
||||||
https://docs.python.org/3/library/uuid.html
|
https://docs.python.org/3/library/uuid.html
|
||||||
"""
|
"""
|
||||||
_id = str(uuid.uuid4())
|
_id = str(uuid.uuid4())
|
||||||
|
self.automatic_id = True
|
||||||
LOGGER.debug(f"id for {type(self).__name__} isn't set. Setting to {_id}")
|
LOGGER.debug(f"id for {type(self).__name__} isn't set. Setting to {_id}")
|
||||||
|
|
||||||
# The id can only be None, if the object is dynamic (self.dynamic = True)
|
# The id can only be None, if the object is dynamic (self.dynamic = True)
|
||||||
@@ -43,7 +46,7 @@ class DatabaseObject:
|
|||||||
return True
|
return True
|
||||||
|
|
||||||
return False
|
return False
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def indexing_values(self) -> List[Tuple[str, object]]:
|
def indexing_values(self) -> List[Tuple[str, object]]:
|
||||||
"""
|
"""
|
||||||
@@ -53,9 +56,9 @@ class DatabaseObject:
|
|||||||
Returns:
|
Returns:
|
||||||
List[Tuple[str, object]]: the first element in the tuple is the name of the attribute, the second the value.
|
List[Tuple[str, object]]: the first element in the tuple is the name of the attribute, the second the value.
|
||||||
"""
|
"""
|
||||||
|
|
||||||
return list()
|
return list()
|
||||||
|
|
||||||
def merge(self, other, override: bool = False):
|
def merge(self, other, override: bool = False):
|
||||||
if not isinstance(other, type(self)):
|
if not isinstance(other, type(self)):
|
||||||
LOGGER.warning(f"can't merge \"{type(other)}\" into \"{type(self)}\"")
|
LOGGER.warning(f"can't merge \"{type(other)}\" into \"{type(self)}\"")
|
||||||
@@ -64,11 +67,11 @@ class DatabaseObject:
|
|||||||
for collection in type(self).COLLECTION_ATTRIBUTES:
|
for collection in type(self).COLLECTION_ATTRIBUTES:
|
||||||
getattr(self, collection).extend(getattr(other, collection))
|
getattr(self, collection).extend(getattr(other, collection))
|
||||||
|
|
||||||
for simple_attribute in type(self).SIMPLE_ATTRIBUTES:
|
for simple_attribute, default_value in type(self).SIMPLE_ATTRIBUTES.items():
|
||||||
if getattr(other, simple_attribute) is None:
|
if getattr(other, simple_attribute) == default_value:
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if override or getattr(self, simple_attribute) is None:
|
if override or getattr(self, simple_attribute) == default_value:
|
||||||
setattr(self, simple_attribute, getattr(other, simple_attribute))
|
setattr(self, simple_attribute, getattr(other, simple_attribute))
|
||||||
|
|
||||||
@property
|
@property
|
||||||
@@ -83,6 +86,18 @@ class DatabaseObject:
|
|||||||
def option_string(self) -> str:
|
def option_string(self) -> str:
|
||||||
return self.__repr__()
|
return self.__repr__()
|
||||||
|
|
||||||
|
def compile(self) -> bool:
|
||||||
|
"""
|
||||||
|
compiles the recursive structures,
|
||||||
|
|
||||||
|
Args:
|
||||||
|
traceback (set, optional): Defaults to an empty set.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
bool: returns true if id has been found in set
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
class MainObject(DatabaseObject):
|
class MainObject(DatabaseObject):
|
||||||
"""
|
"""
|
||||||
@@ -95,7 +110,7 @@ class MainObject(DatabaseObject):
|
|||||||
It has all the functionality of the "DatabaseObject" (it inherits from said class)
|
It has all the functionality of the "DatabaseObject" (it inherits from said class)
|
||||||
but also some added functions as well.
|
but also some added functions as well.
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def __init__(self, _id: str = None, dynamic: bool = False, **kwargs):
|
def __init__(self, _id: str = None, dynamic: bool = False, **kwargs):
|
||||||
DatabaseObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
DatabaseObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
||||||
|
|
||||||
|
|||||||
@@ -1,6 +1,7 @@
|
|||||||
import os
|
import os
|
||||||
from typing import List, Optional, Dict, Tuple
|
from typing import List, Optional, Dict, Tuple
|
||||||
import pycountry
|
import pycountry
|
||||||
|
from collections import defaultdict
|
||||||
|
|
||||||
from .metadata import (
|
from .metadata import (
|
||||||
Mapping as id3Mapping,
|
Mapping as id3Mapping,
|
||||||
@@ -46,7 +47,15 @@ class Song(MainObject):
|
|||||||
COLLECTION_ATTRIBUTES = (
|
COLLECTION_ATTRIBUTES = (
|
||||||
"lyrics_collection", "album_collection", "main_artist_collection", "feature_artist_collection",
|
"lyrics_collection", "album_collection", "main_artist_collection", "feature_artist_collection",
|
||||||
"source_collection")
|
"source_collection")
|
||||||
SIMPLE_ATTRIBUTES = ("title", "unified_title", "isrc", "length", "tracksort", "genre")
|
SIMPLE_ATTRIBUTES = {
|
||||||
|
"title": None,
|
||||||
|
"unified_title": None,
|
||||||
|
"isrc": None,
|
||||||
|
"length": None,
|
||||||
|
"tracksort": 0,
|
||||||
|
"genre": None,
|
||||||
|
"notes": FormattedText()
|
||||||
|
}
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
@@ -64,17 +73,21 @@ class Song(MainObject):
|
|||||||
album_list: List['Album'] = None,
|
album_list: List['Album'] = None,
|
||||||
main_artist_list: List['Artist'] = None,
|
main_artist_list: List['Artist'] = None,
|
||||||
feature_artist_list: List['Artist'] = None,
|
feature_artist_list: List['Artist'] = None,
|
||||||
|
notes: FormattedText = None,
|
||||||
**kwargs
|
**kwargs
|
||||||
) -> None:
|
) -> None:
|
||||||
MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
||||||
# attributes
|
# attributes
|
||||||
self.title: str = title
|
self.title: str = title
|
||||||
self.unified_title: str = unified_title or unify(title)
|
self.unified_title: str = unified_title
|
||||||
|
if unified_title is None and title is not None:
|
||||||
|
self.unified_title = unify(title)
|
||||||
|
|
||||||
self.isrc: str = isrc
|
self.isrc: str = isrc
|
||||||
self.length: int = length
|
self.length: int = length
|
||||||
self.tracksort: int = tracksort or 0
|
self.tracksort: int = tracksort or 0
|
||||||
self.genre: str = genre
|
self.genre: str = genre
|
||||||
|
self.notes: FormattedText = notes or FormattedText()
|
||||||
|
|
||||||
self.source_collection: SourceCollection = SourceCollection(source_list)
|
self.source_collection: SourceCollection = SourceCollection(source_list)
|
||||||
self.target_collection: Collection = Collection(data=target_list, element_type=Target)
|
self.target_collection: Collection = Collection(data=target_list, element_type=Target)
|
||||||
@@ -83,6 +96,22 @@ class Song(MainObject):
|
|||||||
self.main_artist_collection = Collection(data=main_artist_list, element_type=Artist)
|
self.main_artist_collection = Collection(data=main_artist_list, element_type=Artist)
|
||||||
self.feature_artist_collection = Collection(data=feature_artist_list, element_type=Artist)
|
self.feature_artist_collection = Collection(data=feature_artist_list, element_type=Artist)
|
||||||
|
|
||||||
|
def compile(self):
|
||||||
|
album: Album
|
||||||
|
for album in self.album_collection:
|
||||||
|
if album.song_collection.append(self, merge_into_existing=False):
|
||||||
|
album.compile()
|
||||||
|
|
||||||
|
artist: Artist
|
||||||
|
for artist in self.feature_artist_collection:
|
||||||
|
if artist.feature_song_collection.append(self, merge_into_existing=False):
|
||||||
|
artist.compile()
|
||||||
|
|
||||||
|
for artist in self.main_artist_collection:
|
||||||
|
for album in self.album_collection:
|
||||||
|
if artist.main_album_collection.append(album, merge_into_existing=False):
|
||||||
|
artist.compile()
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def indexing_values(self) -> List[Tuple[str, object]]:
|
def indexing_values(self) -> List[Tuple[str, object]]:
|
||||||
return [
|
return [
|
||||||
@@ -166,7 +195,17 @@ All objects dependent on Album
|
|||||||
|
|
||||||
class Album(MainObject):
|
class Album(MainObject):
|
||||||
COLLECTION_ATTRIBUTES = ("label_collection", "artist_collection", "song_collection")
|
COLLECTION_ATTRIBUTES = ("label_collection", "artist_collection", "song_collection")
|
||||||
SIMPLE_ATTRIBUTES = ("title", "album_status", "album_type", "language", "date", "barcode", "albumsort")
|
SIMPLE_ATTRIBUTES = {
|
||||||
|
"title": None,
|
||||||
|
"unified_title": None,
|
||||||
|
"album_status": None,
|
||||||
|
"album_type": AlbumType.OTHER,
|
||||||
|
"language": None,
|
||||||
|
"date": ID3Timestamp(),
|
||||||
|
"barcode": None,
|
||||||
|
"albumsort": None,
|
||||||
|
"notes": FormattedText()
|
||||||
|
}
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
@@ -184,15 +223,18 @@ class Album(MainObject):
|
|||||||
album_status: AlbumStatus = None,
|
album_status: AlbumStatus = None,
|
||||||
album_type: AlbumType = None,
|
album_type: AlbumType = None,
|
||||||
label_list: List['Label'] = None,
|
label_list: List['Label'] = None,
|
||||||
|
notes: FormattedText = None,
|
||||||
**kwargs
|
**kwargs
|
||||||
) -> None:
|
) -> None:
|
||||||
MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
||||||
|
|
||||||
self.title: str = title
|
self.title: str = title
|
||||||
self.unified_title: str = unified_title or unify(self.title)
|
self.unified_title: str = unified_title
|
||||||
|
if unified_title is None and title is not None:
|
||||||
|
self.unified_title = unify(title)
|
||||||
|
|
||||||
self.album_status: AlbumStatus = album_status
|
self.album_status: AlbumStatus = album_status
|
||||||
self.album_type: AlbumType = album_type
|
self.album_type: AlbumType = album_type or AlbumType.OTHER
|
||||||
self.language: pycountry.Languages = language
|
self.language: pycountry.Languages = language
|
||||||
self.date: ID3Timestamp = date or ID3Timestamp()
|
self.date: ID3Timestamp = date or ID3Timestamp()
|
||||||
|
|
||||||
@@ -208,12 +250,29 @@ class Album(MainObject):
|
|||||||
to set albumsort with help of the release year
|
to set albumsort with help of the release year
|
||||||
"""
|
"""
|
||||||
self.albumsort: Optional[int] = albumsort
|
self.albumsort: Optional[int] = albumsort
|
||||||
|
self.notes = notes or FormattedText()
|
||||||
|
|
||||||
self.source_collection: SourceCollection = SourceCollection(source_list)
|
self.source_collection: SourceCollection = SourceCollection(source_list)
|
||||||
self.song_collection: Collection = Collection(data=song_list, element_type=Song)
|
self.song_collection: Collection = Collection(data=song_list, element_type=Song)
|
||||||
self.artist_collection: Collection = Collection(data=artist_list, element_type=Artist)
|
self.artist_collection: Collection = Collection(data=artist_list, element_type=Artist)
|
||||||
self.label_collection: Collection = Collection(data=label_list, element_type=Label)
|
self.label_collection: Collection = Collection(data=label_list, element_type=Label)
|
||||||
|
|
||||||
|
def compile(self):
|
||||||
|
song: Song
|
||||||
|
for song in self.song_collection:
|
||||||
|
if song.album_collection.append(self, merge_into_existing=False):
|
||||||
|
song.compile()
|
||||||
|
|
||||||
|
artist: Artist
|
||||||
|
for artist in self.artist_collection:
|
||||||
|
if artist.main_album_collection.append(self, merge_into_existing=False):
|
||||||
|
artist.compile()
|
||||||
|
|
||||||
|
label: Label
|
||||||
|
for label in self.label_collection:
|
||||||
|
if label.album_collection.append(self, merge_into_existing=False):
|
||||||
|
label.compile()
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def indexing_values(self) -> List[Tuple[str, object]]:
|
def indexing_values(self) -> List[Tuple[str, object]]:
|
||||||
return [
|
return [
|
||||||
@@ -309,16 +368,23 @@ class Album(MainObject):
|
|||||||
return len(self.artist_collection) > 1
|
return len(self.artist_collection) > 1
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
"""
|
"""
|
||||||
All objects dependent on Artist
|
All objects dependent on Artist
|
||||||
"""
|
"""
|
||||||
|
|
||||||
|
|
||||||
class Artist(MainObject):
|
class Artist(MainObject):
|
||||||
COLLECTION_ATTRIBUTES = ("feature_song_collection", "main_album_collection", "label_collection")
|
COLLECTION_ATTRIBUTES = (
|
||||||
SIMPLE_ATTRIBUTES = ("name", "name", "country", "formed_in", "notes", "lyrical_themes", "general_genre")
|
"feature_song_collection", "main_album_collection", "label_collection", "source_collection")
|
||||||
|
SIMPLE_ATTRIBUTES = {
|
||||||
|
"name": None,
|
||||||
|
"unified_name": None,
|
||||||
|
"country": None,
|
||||||
|
"formed_in": ID3Timestamp(),
|
||||||
|
"notes": FormattedText(),
|
||||||
|
"lyrical_themes": [],
|
||||||
|
"general_genre": ""
|
||||||
|
}
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
@@ -340,7 +406,9 @@ class Artist(MainObject):
|
|||||||
MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
||||||
|
|
||||||
self.name: str = name
|
self.name: str = name
|
||||||
self.unified_name: str = unified_name or unify(self.name)
|
self.unified_name: str = unified_name
|
||||||
|
if unified_name is None and name is not None:
|
||||||
|
self.unified_name = unify(name)
|
||||||
|
|
||||||
"""
|
"""
|
||||||
TODO implement album type and notes
|
TODO implement album type and notes
|
||||||
@@ -365,6 +433,22 @@ class Artist(MainObject):
|
|||||||
self.main_album_collection: Collection = Collection(data=main_album_list, element_type=Album)
|
self.main_album_collection: Collection = Collection(data=main_album_list, element_type=Album)
|
||||||
self.label_collection: Collection = Collection(data=label_list, element_type=Label)
|
self.label_collection: Collection = Collection(data=label_list, element_type=Label)
|
||||||
|
|
||||||
|
def compile(self):
|
||||||
|
song: "Song"
|
||||||
|
for song in self.feature_song_collection:
|
||||||
|
if song.feature_artist_collection.append(self, merge_into_existing=False):
|
||||||
|
song.compile()
|
||||||
|
|
||||||
|
album: "Album"
|
||||||
|
for album in self.main_album_collection:
|
||||||
|
if album.artist_collection.append(self, merge_into_existing=False):
|
||||||
|
album.compile()
|
||||||
|
|
||||||
|
label: Label
|
||||||
|
for label in self.label_collection:
|
||||||
|
if label.current_artist_collection.append(self, merge_into_existing=False):
|
||||||
|
label.compile()
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def indexing_values(self) -> List[Tuple[str, object]]:
|
def indexing_values(self) -> List[Tuple[str, object]]:
|
||||||
return [
|
return [
|
||||||
@@ -463,7 +547,11 @@ Label
|
|||||||
|
|
||||||
class Label(MainObject):
|
class Label(MainObject):
|
||||||
COLLECTION_ATTRIBUTES = ("album_collection", "current_artist_collection")
|
COLLECTION_ATTRIBUTES = ("album_collection", "current_artist_collection")
|
||||||
SIMPLE_ATTRIBUTES = ("name",)
|
SIMPLE_ATTRIBUTES = {
|
||||||
|
"name": None,
|
||||||
|
"unified_name": None,
|
||||||
|
"notes": FormattedText()
|
||||||
|
}
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
@@ -471,6 +559,7 @@ class Label(MainObject):
|
|||||||
dynamic: bool = False,
|
dynamic: bool = False,
|
||||||
name: str = None,
|
name: str = None,
|
||||||
unified_name: str = None,
|
unified_name: str = None,
|
||||||
|
notes: FormattedText = None,
|
||||||
album_list: List[Album] = None,
|
album_list: List[Album] = None,
|
||||||
current_artist_list: List[Artist] = None,
|
current_artist_list: List[Artist] = None,
|
||||||
source_list: List[Source] = None,
|
source_list: List[Source] = None,
|
||||||
@@ -479,12 +568,26 @@ class Label(MainObject):
|
|||||||
MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
|
||||||
|
|
||||||
self.name: str = name
|
self.name: str = name
|
||||||
self.unified_name: str = unified_name or unify(self.name)
|
self.unified_name: str = unified_name
|
||||||
|
if unified_name is None and name is not None:
|
||||||
|
self.unified_name = unify(name)
|
||||||
|
self.notes = notes or FormattedText()
|
||||||
|
|
||||||
self.source_collection: SourceCollection = SourceCollection(source_list)
|
self.source_collection: SourceCollection = SourceCollection(source_list)
|
||||||
self.album_collection: Collection = Collection(data=album_list, element_type=Album)
|
self.album_collection: Collection = Collection(data=album_list, element_type=Album)
|
||||||
self.current_artist_collection: Collection = Collection(data=current_artist_list, element_type=Artist)
|
self.current_artist_collection: Collection = Collection(data=current_artist_list, element_type=Artist)
|
||||||
|
|
||||||
|
def compile(self) -> bool:
|
||||||
|
album: Album
|
||||||
|
for album in self.album_collection:
|
||||||
|
if album.label_collection.append(self, merge_into_existing=False):
|
||||||
|
album.compile()
|
||||||
|
|
||||||
|
artist: Artist
|
||||||
|
for artist in self.current_artist_collection:
|
||||||
|
if artist.label_collection.append(self, merge_into_existing=False):
|
||||||
|
artist.compile()
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def indexing_values(self) -> List[Tuple[str, object]]:
|
def indexing_values(self) -> List[Tuple[str, object]]:
|
||||||
return [
|
return [
|
||||||
@@ -497,4 +600,4 @@ class Label(MainObject):
|
|||||||
def options(self) -> Options:
|
def options(self) -> Options:
|
||||||
options = [self]
|
options = [self]
|
||||||
options.extend(self.current_artist_collection.shallow_list)
|
options.extend(self.current_artist_collection.shallow_list)
|
||||||
options.extend(self.album_collection.shallow_list)
|
options.extend(self.album_collection.shallow_list)
|
||||||
|
|||||||
@@ -1,6 +1,7 @@
|
|||||||
from collections import defaultdict
|
from collections import defaultdict
|
||||||
from enum import Enum
|
from enum import Enum
|
||||||
from typing import List, Dict, Tuple
|
from typing import List, Dict, Tuple, Optional
|
||||||
|
from urllib.parse import urlparse
|
||||||
|
|
||||||
from .metadata import Mapping, Metadata
|
from .metadata import Mapping, Metadata
|
||||||
from .parents import DatabaseObject
|
from .parents import DatabaseObject
|
||||||
@@ -25,9 +26,11 @@ class SourcePages(Enum):
|
|||||||
SPOTIFY = "spotify"
|
SPOTIFY = "spotify"
|
||||||
|
|
||||||
# This has nothing to do with audio, but bands can be here
|
# This has nothing to do with audio, but bands can be here
|
||||||
|
WIKIPEDIA = "wikipedia"
|
||||||
INSTAGRAM = "instagram"
|
INSTAGRAM = "instagram"
|
||||||
FACEBOOK = "facebook"
|
FACEBOOK = "facebook"
|
||||||
TWITTER = "twitter" # I will use nitter though lol
|
TWITTER = "twitter" # I will use nitter though lol
|
||||||
|
MYSPACE = "myspace" # Yes somehow this ancient site is linked EVERYWHERE
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def get_homepage(cls, attribute) -> str:
|
def get_homepage(cls, attribute) -> str:
|
||||||
@@ -42,7 +45,9 @@ class SourcePages(Enum):
|
|||||||
cls.INSTAGRAM: "https://www.instagram.com/",
|
cls.INSTAGRAM: "https://www.instagram.com/",
|
||||||
cls.FACEBOOK: "https://www.facebook.com/",
|
cls.FACEBOOK: "https://www.facebook.com/",
|
||||||
cls.SPOTIFY: "https://open.spotify.com/",
|
cls.SPOTIFY: "https://open.spotify.com/",
|
||||||
cls.TWITTER: "https://twitter.com/"
|
cls.TWITTER: "https://twitter.com/",
|
||||||
|
cls.MYSPACE: "https://myspace.com/",
|
||||||
|
cls.WIKIPEDIA: "https://en.wikipedia.org/wiki/Main_Page"
|
||||||
}
|
}
|
||||||
return homepage_map[attribute]
|
return homepage_map[attribute]
|
||||||
|
|
||||||
@@ -55,6 +60,12 @@ class Source(DatabaseObject):
|
|||||||
Source(src="youtube", url="https://youtu.be/dfnsdajlhkjhsd")
|
Source(src="youtube", url="https://youtu.be/dfnsdajlhkjhsd")
|
||||||
```
|
```
|
||||||
"""
|
"""
|
||||||
|
COLLECTION_ATTRIBUTES = tuple()
|
||||||
|
SIMPLE_ATTRIBUTES = {
|
||||||
|
"type_enum": None,
|
||||||
|
"page_enum": None,
|
||||||
|
"url": None
|
||||||
|
}
|
||||||
|
|
||||||
def __init__(self, page_enum: SourcePages, url: str, id_: str = None, type_enum=None) -> None:
|
def __init__(self, page_enum: SourcePages, url: str, id_: str = None, type_enum=None) -> None:
|
||||||
DatabaseObject.__init__(self, id_=id_)
|
DatabaseObject.__init__(self, id_=id_)
|
||||||
@@ -65,11 +76,14 @@ class Source(DatabaseObject):
|
|||||||
self.url = url
|
self.url = url
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def match_url(cls, url: str):
|
def match_url(cls, url: str) -> Optional["Source"]:
|
||||||
"""
|
"""
|
||||||
this shouldn't be used, unlesse you are not certain what the source is for
|
this shouldn't be used, unlesse you are not certain what the source is for
|
||||||
the reason is that it is more inefficient
|
the reason is that it is more inefficient
|
||||||
"""
|
"""
|
||||||
|
parsed = urlparse(url)
|
||||||
|
url = parsed.geturl()
|
||||||
|
|
||||||
if url.startswith("https://www.youtube"):
|
if url.startswith("https://www.youtube"):
|
||||||
return cls(SourcePages.YOUTUBE, url)
|
return cls(SourcePages.YOUTUBE, url)
|
||||||
|
|
||||||
@@ -82,6 +96,9 @@ class Source(DatabaseObject):
|
|||||||
if "bandcamp" in url:
|
if "bandcamp" in url:
|
||||||
return cls(SourcePages.BANDCAMP, url)
|
return cls(SourcePages.BANDCAMP, url)
|
||||||
|
|
||||||
|
if "wikipedia" in parsed.netloc:
|
||||||
|
return cls(SourcePages.WIKIPEDIA, url)
|
||||||
|
|
||||||
if url.startswith("https://www.metal-archives.com/"):
|
if url.startswith("https://www.metal-archives.com/"):
|
||||||
return cls(SourcePages.ENCYCLOPAEDIA_METALLUM, url)
|
return cls(SourcePages.ENCYCLOPAEDIA_METALLUM, url)
|
||||||
|
|
||||||
@@ -95,6 +112,9 @@ class Source(DatabaseObject):
|
|||||||
if url.startswith("https://twitter"):
|
if url.startswith("https://twitter"):
|
||||||
return cls(SourcePages.TWITTER, url)
|
return cls(SourcePages.TWITTER, url)
|
||||||
|
|
||||||
|
if url.startswith("https://myspace.com"):
|
||||||
|
return cls(SourcePages.MYSPACE, url)
|
||||||
|
|
||||||
def get_song_metadata(self) -> Metadata:
|
def get_song_metadata(self) -> Metadata:
|
||||||
return Metadata({
|
return Metadata({
|
||||||
Mapping.FILE_WEBPAGE_URL: [self.url],
|
Mapping.FILE_WEBPAGE_URL: [self.url],
|
||||||
@@ -151,4 +171,4 @@ class SourceCollection(Collection):
|
|||||||
getting the sources for a specific page like
|
getting the sources for a specific page like
|
||||||
YouTube or musify
|
YouTube or musify
|
||||||
"""
|
"""
|
||||||
return self._page_to_source_list[source_page]
|
return self._page_to_source_list[source_page].copy()
|
||||||
|
|||||||
@@ -1,5 +1,6 @@
|
|||||||
from typing import Optional, List, Tuple
|
from typing import Optional, List, Tuple
|
||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
|
from collections import defaultdict
|
||||||
|
|
||||||
from ..utils import shared
|
from ..utils import shared
|
||||||
from .parents import DatabaseObject
|
from .parents import DatabaseObject
|
||||||
@@ -14,7 +15,11 @@ class Target(DatabaseObject):
|
|||||||
```
|
```
|
||||||
"""
|
"""
|
||||||
|
|
||||||
SIMPLE_ATTRIBUTES = ("_file", "_path")
|
SIMPLE_ATTRIBUTES = {
|
||||||
|
"_file": None,
|
||||||
|
"_path": None
|
||||||
|
}
|
||||||
|
COLLECTION_ATTRIBUTES = tuple()
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
|
|||||||
@@ -1,11 +1,14 @@
|
|||||||
from .encyclopaedia_metallum import EncyclopaediaMetallum
|
from .encyclopaedia_metallum import EncyclopaediaMetallum
|
||||||
|
from .musify import Musify
|
||||||
|
|
||||||
EncyclopaediaMetallum = EncyclopaediaMetallum
|
EncyclopaediaMetallum = EncyclopaediaMetallum
|
||||||
|
Musify = Musify
|
||||||
|
|
||||||
MetadataPages = {
|
MetadataPages = {
|
||||||
EncyclopaediaMetallum
|
EncyclopaediaMetallum,
|
||||||
|
Musify
|
||||||
}
|
}
|
||||||
|
|
||||||
AudioPages = {
|
AudioPages = {
|
||||||
|
Musify
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -1,6 +1,10 @@
|
|||||||
from typing import (
|
from typing import Optional
|
||||||
List
|
import requests
|
||||||
)
|
import logging
|
||||||
|
|
||||||
|
LOGGER = logging.getLogger("this shouldn't be used")
|
||||||
|
|
||||||
|
from ..utils import shared
|
||||||
|
|
||||||
from ..objects import (
|
from ..objects import (
|
||||||
Song,
|
Song,
|
||||||
@@ -9,7 +13,10 @@ from ..objects import (
|
|||||||
Artist,
|
Artist,
|
||||||
Lyrics,
|
Lyrics,
|
||||||
Target,
|
Target,
|
||||||
MusicObject
|
MusicObject,
|
||||||
|
Options,
|
||||||
|
SourcePages,
|
||||||
|
Collection
|
||||||
)
|
)
|
||||||
|
|
||||||
|
|
||||||
@@ -18,6 +25,50 @@ class Page:
|
|||||||
This is an abstract class, laying out the
|
This is an abstract class, laying out the
|
||||||
functionality for every other class fetching something
|
functionality for every other class fetching something
|
||||||
"""
|
"""
|
||||||
|
API_SESSION: requests.Session = requests.Session()
|
||||||
|
API_SESSION.proxies = shared.proxies
|
||||||
|
TIMEOUT = 5
|
||||||
|
TRIES = 5
|
||||||
|
|
||||||
|
SOURCE_TYPE: SourcePages
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_request(cls, url: str, accepted_response_codes: set = set((200,)), trie: int = 0) -> Optional[
|
||||||
|
requests.Request]:
|
||||||
|
try:
|
||||||
|
r = cls.API_SESSION.get(url, timeout=cls.TIMEOUT)
|
||||||
|
except requests.exceptions.Timeout:
|
||||||
|
return None
|
||||||
|
|
||||||
|
if r.status_code in accepted_response_codes:
|
||||||
|
return r
|
||||||
|
|
||||||
|
LOGGER.warning(f"{cls.__name__} responded wit {r.status_code} at {url}. ({trie}-{cls.TRIES})")
|
||||||
|
LOGGER.debug(r.content)
|
||||||
|
|
||||||
|
if trie <= cls.TRIES:
|
||||||
|
LOGGER.warning("to many tries. Aborting.")
|
||||||
|
|
||||||
|
return cls.get_request(url, accepted_response_codes, trie + 1)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def post_request(cls, url: str, json: dict, accepted_response_codes: set = set((200,)), trie: int = 0) -> Optional[
|
||||||
|
requests.Request]:
|
||||||
|
try:
|
||||||
|
r = cls.API_SESSION.post(url, json=json, timeout=cls.TIMEOUT)
|
||||||
|
except requests.exceptions.Timeout:
|
||||||
|
return None
|
||||||
|
|
||||||
|
if r.status_code in accepted_response_codes:
|
||||||
|
return r
|
||||||
|
|
||||||
|
LOGGER.warning(f"{cls.__name__} responded wit {r.status_code} at {url}. ({trie}-{cls.TRIES})")
|
||||||
|
LOGGER.debug(r.content)
|
||||||
|
|
||||||
|
if trie <= cls.TRIES:
|
||||||
|
LOGGER.warning("to many tries. Aborting.")
|
||||||
|
|
||||||
|
return cls.post_request(url, accepted_response_codes, trie + 1)
|
||||||
|
|
||||||
class Query:
|
class Query:
|
||||||
def __init__(self, query: str):
|
def __init__(self, query: str):
|
||||||
@@ -69,7 +120,7 @@ class Page:
|
|||||||
song_str = property(fget=lambda self: self.get_str(self.song))
|
song_str = property(fget=lambda self: self.get_str(self.song))
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def search_by_query(cls, query: str) -> List[MusicObject]:
|
def search_by_query(cls, query: str) -> Options:
|
||||||
"""
|
"""
|
||||||
# The Query
|
# The Query
|
||||||
You can define a new parameter with "#",
|
You can define a new parameter with "#",
|
||||||
@@ -84,7 +135,7 @@ class Page:
|
|||||||
:return possible_music_objects:
|
:return possible_music_objects:
|
||||||
"""
|
"""
|
||||||
|
|
||||||
return []
|
return Options()
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def fetch_details(cls, music_object: MusicObject, flat: bool = False) -> MusicObject:
|
def fetch_details(cls, music_object: MusicObject, flat: bool = False) -> MusicObject:
|
||||||
@@ -102,16 +153,26 @@ class Page:
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
if type(music_object) == Song:
|
if type(music_object) == Song:
|
||||||
return cls.fetch_song_details(music_object, flat=flat)
|
song = cls.fetch_song_details(music_object, flat=flat)
|
||||||
|
song.compile()
|
||||||
|
return song
|
||||||
|
|
||||||
if type(music_object) == Album:
|
if type(music_object) == Album:
|
||||||
return cls.fetch_album_details(music_object, flat=flat)
|
album = cls.fetch_album_details(music_object, flat=flat)
|
||||||
|
album.compile()
|
||||||
|
return album
|
||||||
|
|
||||||
if type(music_object) == Artist:
|
if type(music_object) == Artist:
|
||||||
return cls.fetch_artist_details(music_object, flat=flat)
|
artist = cls.fetch_artist_details(music_object, flat=flat)
|
||||||
|
artist.compile()
|
||||||
|
return artist
|
||||||
|
|
||||||
raise NotImplementedError(f"MusicObject {type(music_object)} has not been implemented yet")
|
raise NotImplementedError(f"MusicObject {type(music_object)} has not been implemented yet")
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def fetch_song_from_source(cls, source: Source, flat: bool = False) -> Song:
|
||||||
|
return Song()
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def fetch_song_details(cls, song: Song, flat: bool = False) -> Song:
|
def fetch_song_details(cls, song: Song, flat: bool = False) -> Song:
|
||||||
"""
|
"""
|
||||||
@@ -127,9 +188,18 @@ class Page:
|
|||||||
|
|
||||||
:return detailed_song: it modifies the input song
|
:return detailed_song: it modifies the input song
|
||||||
"""
|
"""
|
||||||
|
|
||||||
|
source: Source
|
||||||
|
for source in song.source_collection.get_sources_from_page(cls.SOURCE_TYPE):
|
||||||
|
new_song = cls.fetch_song_from_source(source, flat)
|
||||||
|
song.merge(new_song)
|
||||||
|
|
||||||
return song
|
return song
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def fetch_album_from_source(cls, source: Source, flat: bool = False) -> Album:
|
||||||
|
return Album()
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def fetch_album_details(cls, album: Album, flat: bool = False) -> Album:
|
def fetch_album_details(cls, album: Album, flat: bool = False) -> Album:
|
||||||
"""
|
"""
|
||||||
@@ -147,8 +217,17 @@ class Page:
|
|||||||
:return detailed_artist: it modifies the input artist
|
:return detailed_artist: it modifies the input artist
|
||||||
"""
|
"""
|
||||||
|
|
||||||
|
source: Source
|
||||||
|
for source in album.source_collection.get_sources_from_page(cls.SOURCE_TYPE):
|
||||||
|
new_album: Album = cls.fetch_album_from_source(source, flat)
|
||||||
|
album.merge(new_album)
|
||||||
|
|
||||||
return album
|
return album
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def fetch_artist_from_source(cls, source: Source, flat: bool = False) -> Artist:
|
||||||
|
return Artist()
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def fetch_artist_details(cls, artist: Artist, flat: bool = False) -> Artist:
|
def fetch_artist_details(cls, artist: Artist, flat: bool = False) -> Artist:
|
||||||
"""
|
"""
|
||||||
@@ -163,5 +242,10 @@ class Page:
|
|||||||
|
|
||||||
:return detailed_artist: it modifies the input artist
|
:return detailed_artist: it modifies the input artist
|
||||||
"""
|
"""
|
||||||
|
|
||||||
|
source: Source
|
||||||
|
for source in artist.source_collection.get_sources_from_page(cls.SOURCE_TYPE):
|
||||||
|
new_artist: Artist = cls.fetch_artist_from_source(source, flat)
|
||||||
|
artist.merge(new_artist)
|
||||||
|
|
||||||
return artist
|
return artist
|
||||||
|
|||||||
@@ -17,7 +17,8 @@ from ..objects import (
|
|||||||
Album,
|
Album,
|
||||||
ID3Timestamp,
|
ID3Timestamp,
|
||||||
FormattedText,
|
FormattedText,
|
||||||
Label
|
Label,
|
||||||
|
Options
|
||||||
)
|
)
|
||||||
from ..utils import (
|
from ..utils import (
|
||||||
string_processing
|
string_processing
|
||||||
@@ -34,7 +35,7 @@ class EncyclopaediaMetallum(Page):
|
|||||||
SOURCE_TYPE = SourcePages.ENCYCLOPAEDIA_METALLUM
|
SOURCE_TYPE = SourcePages.ENCYCLOPAEDIA_METALLUM
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def search_by_query(cls, query: str) -> List[MusicObject]:
|
def search_by_query(cls, query: str) -> Options:
|
||||||
query_obj = cls.Query(query)
|
query_obj = cls.Query(query)
|
||||||
|
|
||||||
if query_obj.is_raw:
|
if query_obj.is_raw:
|
||||||
@@ -42,14 +43,14 @@ class EncyclopaediaMetallum(Page):
|
|||||||
return cls.advanced_search(query_obj)
|
return cls.advanced_search(query_obj)
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def advanced_search(cls, query: Page.Query) -> List[MusicObject]:
|
def advanced_search(cls, query: Page.Query) -> Options:
|
||||||
if query.song is not None:
|
if query.song is not None:
|
||||||
return cls.search_for_song(query=query)
|
return Options(cls.search_for_song(query=query))
|
||||||
if query.album is not None:
|
if query.album is not None:
|
||||||
return cls.search_for_album(query=query)
|
return Options(cls.search_for_album(query=query))
|
||||||
if query.artist is not None:
|
if query.artist is not None:
|
||||||
return cls.search_for_artist(query=query)
|
return Options(cls.search_for_artist(query=query))
|
||||||
return []
|
return Options
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def search_for_song(cls, query: Page.Query) -> List[Song]:
|
def search_for_song(cls, query: Page.Query) -> List[Song]:
|
||||||
|
|||||||
File diff suppressed because one or more lines are too long
@@ -0,0 +1,887 @@
|
|||||||
|
from collections import defaultdict
|
||||||
|
from typing import List, Optional, Union
|
||||||
|
import requests
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
|
import pycountry
|
||||||
|
import time
|
||||||
|
from urllib.parse import urlparse
|
||||||
|
from enum import Enum
|
||||||
|
from dataclasses import dataclass
|
||||||
|
|
||||||
|
from ..utils.shared import (
|
||||||
|
ENCYCLOPAEDIA_METALLUM_LOGGER as LOGGER
|
||||||
|
)
|
||||||
|
|
||||||
|
from .abstract import Page
|
||||||
|
from ..objects import (
|
||||||
|
MusicObject,
|
||||||
|
Artist,
|
||||||
|
Source,
|
||||||
|
SourcePages,
|
||||||
|
Song,
|
||||||
|
Album,
|
||||||
|
ID3Timestamp,
|
||||||
|
FormattedText,
|
||||||
|
Label,
|
||||||
|
Options,
|
||||||
|
AlbumType,
|
||||||
|
AlbumStatus
|
||||||
|
)
|
||||||
|
from ..utils import (
|
||||||
|
string_processing,
|
||||||
|
shared
|
||||||
|
)
|
||||||
|
from ..utils.shared import (
|
||||||
|
MUSIFY_LOGGER as LOGGER
|
||||||
|
)
|
||||||
|
|
||||||
|
"""
|
||||||
|
https://musify.club/artist/ghost-bath-280348?_pjax=#bodyContent
|
||||||
|
https://musify.club/artist/ghost-bath-280348/releases?_pjax=#bodyContent
|
||||||
|
https://musify.club/artist/ghost-bath-280348/clips?_pjax=#bodyContent
|
||||||
|
https://musify.club/artist/ghost-bath-280348/photos?_pjax=#bodyContent
|
||||||
|
|
||||||
|
POST https://musify.club/artist/filtersongs
|
||||||
|
ID: 280348
|
||||||
|
NameForUrl: ghost-bath
|
||||||
|
Page: 1
|
||||||
|
IsAllowed: True
|
||||||
|
SortOrder.Property: dateCreated
|
||||||
|
SortOrder.IsAscending: false
|
||||||
|
X-Requested-With: XMLHttpRequest
|
||||||
|
|
||||||
|
POST https://musify.club/artist/filteralbums
|
||||||
|
ArtistID: 280348
|
||||||
|
SortOrder.Property: dateCreated
|
||||||
|
SortOrder.IsAscending: false
|
||||||
|
X-Requested-With: XMLHttpRequest
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class MusifyTypes(Enum):
|
||||||
|
ARTIST = "artist"
|
||||||
|
RELEASE = "release"
|
||||||
|
SONG = "track"
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class MusifyUrl:
|
||||||
|
source_type: MusifyTypes
|
||||||
|
name_without_id: str
|
||||||
|
name_with_id: str
|
||||||
|
musify_id: str
|
||||||
|
url: str
|
||||||
|
|
||||||
|
|
||||||
|
class Musify(Page):
|
||||||
|
API_SESSION: requests.Session = requests.Session()
|
||||||
|
API_SESSION.headers = {
|
||||||
|
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:106.0) Gecko/20100101 Firefox/106.0",
|
||||||
|
"Connection": "keep-alive",
|
||||||
|
"Referer": "https://musify.club/"
|
||||||
|
}
|
||||||
|
API_SESSION.proxies = shared.proxies
|
||||||
|
TIMEOUT = 5
|
||||||
|
TRIES = 5
|
||||||
|
HOST = "https://musify.club"
|
||||||
|
|
||||||
|
SOURCE_TYPE = SourcePages.MUSIFY
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_url(cls, url: str) -> MusifyUrl:
|
||||||
|
parsed = urlparse(url)
|
||||||
|
|
||||||
|
path = parsed.path.split("/")
|
||||||
|
|
||||||
|
split_name = path[2].split("-")
|
||||||
|
url_id = split_name[-1]
|
||||||
|
name_for_url = "-".join(split_name[:-1])
|
||||||
|
|
||||||
|
try:
|
||||||
|
type_enum = MusifyTypes(path[1])
|
||||||
|
except ValueError as e:
|
||||||
|
print(f"{path[1]} is not yet implemented, add it to MusifyTypes")
|
||||||
|
raise e
|
||||||
|
|
||||||
|
return MusifyUrl(
|
||||||
|
source_type=type_enum,
|
||||||
|
name_without_id=name_for_url,
|
||||||
|
name_with_id=path[2],
|
||||||
|
musify_id=url_id,
|
||||||
|
url=url
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def search_by_query(cls, query: str) -> Options:
|
||||||
|
query_obj = cls.Query(query)
|
||||||
|
|
||||||
|
if query_obj.is_raw:
|
||||||
|
return cls.plaintext_search(query_obj.query)
|
||||||
|
return cls.plaintext_search(cls.get_plaintext_query(query_obj))
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_plaintext_query(cls, query: Page.Query) -> str:
|
||||||
|
if query.album is None:
|
||||||
|
return f"{query.artist or '*'} - {query.song or '*'}"
|
||||||
|
return f"{query.artist or '*'} - {query.album or '*'} - {query.song or '*'}"
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_artist_contact(cls, contact: BeautifulSoup) -> Artist:
|
||||||
|
source_list: List[Source] = []
|
||||||
|
name = None
|
||||||
|
_id = None
|
||||||
|
|
||||||
|
# source
|
||||||
|
anchor = contact.find("a")
|
||||||
|
if anchor is not None:
|
||||||
|
href = anchor.get("href")
|
||||||
|
name = anchor.get("title")
|
||||||
|
|
||||||
|
if "-" in href:
|
||||||
|
_id = href.split("-")[-1]
|
||||||
|
|
||||||
|
source_list.append(Source(cls.SOURCE_TYPE, cls.HOST + href))
|
||||||
|
|
||||||
|
# artist image
|
||||||
|
image_soup = contact.find("img")
|
||||||
|
if image_soup is not None:
|
||||||
|
alt = image_soup.get("alt")
|
||||||
|
if alt is not None:
|
||||||
|
name = alt
|
||||||
|
|
||||||
|
artist_thumbnail = image_soup.get("src")
|
||||||
|
|
||||||
|
return Artist(
|
||||||
|
_id=_id,
|
||||||
|
name=name,
|
||||||
|
source_list=source_list
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_album_contact(cls, contact: BeautifulSoup) -> Album:
|
||||||
|
"""
|
||||||
|
<div class="contacts__item">
|
||||||
|
<a href="/release/ghost-bath-ghost-bath-2013-602489" title="Ghost Bath - 2013">
|
||||||
|
|
||||||
|
<div class="contacts__img release">
|
||||||
|
<img alt="Ghost Bath" class="lozad" data-src="https://37s.musify.club/img/69/9060265/24178833.jpg"/>
|
||||||
|
<noscript><img alt="Ghost Bath" src="https://37s.musify.club/img/69/9060265/24178833.jpg"/></noscript>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<div class="contacts__info">
|
||||||
|
<strong>Ghost Bath - 2013</strong>
|
||||||
|
<small>Ghost Bath</small>
|
||||||
|
<small>Треков: 4</small> <!--tracks-->
|
||||||
|
<small><i class="zmdi zmdi-star zmdi-hc-fw"></i> 9,04</small>
|
||||||
|
</div>
|
||||||
|
</a>
|
||||||
|
</div>
|
||||||
|
"""
|
||||||
|
|
||||||
|
source_list: List[Source] = []
|
||||||
|
title = None
|
||||||
|
_id = None
|
||||||
|
year = None
|
||||||
|
artist_list: List[Artist] = []
|
||||||
|
|
||||||
|
def parse_title_date(title_date: Optional[str], delimiter: str = " - "):
|
||||||
|
nonlocal year
|
||||||
|
nonlocal title
|
||||||
|
|
||||||
|
if title_date is None:
|
||||||
|
return
|
||||||
|
|
||||||
|
title_date = title_date.strip()
|
||||||
|
split_attr = title_date.split(delimiter)
|
||||||
|
|
||||||
|
if len(split_attr) < 2:
|
||||||
|
return
|
||||||
|
if not split_attr[-1].isdigit():
|
||||||
|
return
|
||||||
|
|
||||||
|
year = int(split_attr[-1])
|
||||||
|
title = delimiter.join(split_attr[:-1])
|
||||||
|
|
||||||
|
# source
|
||||||
|
anchor = contact.find("a")
|
||||||
|
if anchor is not None:
|
||||||
|
href = anchor.get("href")
|
||||||
|
|
||||||
|
# get the title and year
|
||||||
|
parse_title_date(anchor.get("title"))
|
||||||
|
|
||||||
|
if "-" in href:
|
||||||
|
_id = href.split("-")[-1]
|
||||||
|
|
||||||
|
source_list.append(Source(cls.SOURCE_TYPE, cls.HOST + href))
|
||||||
|
|
||||||
|
# cover art
|
||||||
|
image_soup = contact.find("img")
|
||||||
|
if image_soup is not None:
|
||||||
|
alt = image_soup.get("alt")
|
||||||
|
if alt is not None:
|
||||||
|
title = alt
|
||||||
|
|
||||||
|
cover_art = image_soup.get("src")
|
||||||
|
|
||||||
|
contact_info_soup = contact.find("div", {"class": "contacts__info"})
|
||||||
|
if contact_info_soup is not None:
|
||||||
|
"""
|
||||||
|
<strong>Ghost Bath - 2013</strong>
|
||||||
|
<small>Ghost Bath</small>
|
||||||
|
<small>Треков: 4</small> <!--tracks-->
|
||||||
|
<small><i class="zmdi zmdi-star zmdi-hc-fw"></i> 9,04</small>
|
||||||
|
"""
|
||||||
|
|
||||||
|
title_soup = contact_info_soup.find("strong")
|
||||||
|
if title_soup is None:
|
||||||
|
parse_title_date(title_soup)
|
||||||
|
|
||||||
|
small_list = contact_info_soup.find_all("small")
|
||||||
|
if len(small_list) == 3:
|
||||||
|
# artist
|
||||||
|
artist_soup: BeautifulSoup = small_list[0]
|
||||||
|
raw_artist_str = artist_soup.text
|
||||||
|
|
||||||
|
for artist_str in raw_artist_str.split("&\r\n"):
|
||||||
|
artist_str = artist_str.rstrip("& ...\r\n")
|
||||||
|
artist_str = artist_str.strip()
|
||||||
|
|
||||||
|
if artist_str.endswith("]") and "[" in artist_str:
|
||||||
|
artist_str = artist_str.rsplit("[", maxsplit=1)[0]
|
||||||
|
|
||||||
|
artist_list.append(Artist(name=artist_str))
|
||||||
|
|
||||||
|
track_count_soup: BeautifulSoup = small_list[1]
|
||||||
|
rating_soup: BeautifulSoup = small_list[2]
|
||||||
|
else:
|
||||||
|
LOGGER.warning("got an unequal ammount than 3 small elements")
|
||||||
|
|
||||||
|
return cls.ALBUM_CACHE.append(Album(
|
||||||
|
_id=_id,
|
||||||
|
title=title,
|
||||||
|
source_list=source_list,
|
||||||
|
date=ID3Timestamp(year=year),
|
||||||
|
artist_list=artist_list
|
||||||
|
))
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_contact_container(cls, contact_container_soup: BeautifulSoup) -> List[Union[Artist, Album]]:
|
||||||
|
# print(contact_container_soup.prettify)
|
||||||
|
contacts = []
|
||||||
|
|
||||||
|
# print(contact_container_soup)
|
||||||
|
|
||||||
|
contact: BeautifulSoup
|
||||||
|
for contact in contact_container_soup.find_all("div", {"class": "contacts__item"}):
|
||||||
|
|
||||||
|
anchor_soup = contact.find("a")
|
||||||
|
|
||||||
|
if anchor_soup is not None:
|
||||||
|
url = anchor_soup.get("href")
|
||||||
|
|
||||||
|
if url is not None:
|
||||||
|
# print(url)
|
||||||
|
if "artist" in url:
|
||||||
|
contacts.append(cls.parse_artist_contact(contact))
|
||||||
|
elif "release" in url:
|
||||||
|
contacts.append(cls.parse_album_contact(contact))
|
||||||
|
return contacts
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_playlist_item(cls, playlist_item_soup: BeautifulSoup) -> Song:
|
||||||
|
_id = None
|
||||||
|
song_title = playlist_item_soup.get("data-name")
|
||||||
|
artist_list: List[Artist] = []
|
||||||
|
source_list: List[Source] = []
|
||||||
|
|
||||||
|
# details
|
||||||
|
playlist_details: BeautifulSoup = playlist_item_soup.find("div", {"class", "playlist__heading"})
|
||||||
|
if playlist_details is not None:
|
||||||
|
anchor_list = playlist_details.find_all("a")
|
||||||
|
|
||||||
|
if len(anchor_list) >= 2:
|
||||||
|
print(anchor_list)
|
||||||
|
# artists
|
||||||
|
artist_anchor: BeautifulSoup
|
||||||
|
for artist_anchor in anchor_list[:-1]:
|
||||||
|
_id = None
|
||||||
|
href = artist_anchor.get("href")
|
||||||
|
artist_source: Source = Source(cls.SOURCE_TYPE, cls.HOST + href)
|
||||||
|
if "-" in href:
|
||||||
|
_id = href.split("-")[-1]
|
||||||
|
|
||||||
|
artist_list.append(Artist(
|
||||||
|
_id=_id,
|
||||||
|
name=artist_anchor.get_text(strip=True),
|
||||||
|
source_list=[artist_source]
|
||||||
|
))
|
||||||
|
|
||||||
|
# track
|
||||||
|
track_soup: BeautifulSoup = anchor_list[-1]
|
||||||
|
"""
|
||||||
|
TODO
|
||||||
|
this anchor text may have something like (feat. some artist)
|
||||||
|
which is not acceptable
|
||||||
|
"""
|
||||||
|
href = track_soup.get("href")
|
||||||
|
if href is not None:
|
||||||
|
if "-" in href:
|
||||||
|
raw_id: str = href.split("-")[-1]
|
||||||
|
if raw_id.isdigit():
|
||||||
|
_id = raw_id
|
||||||
|
source_list.append(Source(cls.SOURCE_TYPE, cls.HOST + href))
|
||||||
|
|
||||||
|
else:
|
||||||
|
LOGGER.warning("there are not enough anchors (2) for artist and track")
|
||||||
|
LOGGER.warning(str(artist_list))
|
||||||
|
|
||||||
|
"""
|
||||||
|
artist_name = playlist_item_soup.get("data-artist")
|
||||||
|
if artist_name is not None:
|
||||||
|
artist_list.append(Artist(name=artist_name))
|
||||||
|
"""
|
||||||
|
id_attribute = playlist_item_soup.get("id")
|
||||||
|
if id_attribute is not None:
|
||||||
|
raw_id = id_attribute.replace("playerDiv", "")
|
||||||
|
if raw_id.isdigit():
|
||||||
|
_id = raw_id
|
||||||
|
|
||||||
|
return Song(
|
||||||
|
_id=_id,
|
||||||
|
title=song_title,
|
||||||
|
main_artist_list=artist_list,
|
||||||
|
source_list=source_list
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_playlist_soup(cls, playlist_soup: BeautifulSoup) -> List[Song]:
|
||||||
|
song_list = []
|
||||||
|
|
||||||
|
for playlist_item_soup in playlist_soup.find_all("div", {"class": "playlist__item"}):
|
||||||
|
song_list.append(cls.parse_playlist_item(playlist_item_soup))
|
||||||
|
|
||||||
|
return song_list
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def plaintext_search(cls, query: str) -> Options:
|
||||||
|
search_results = []
|
||||||
|
|
||||||
|
r = cls.get_request(f"https://musify.club/search?searchText={query}")
|
||||||
|
if r is None:
|
||||||
|
return Options()
|
||||||
|
search_soup: BeautifulSoup = BeautifulSoup(r.content, features="html.parser")
|
||||||
|
|
||||||
|
# album and songs
|
||||||
|
# child of div class: contacts row
|
||||||
|
for contact_container_soup in search_soup.find_all("div", {"class": "contacts"}):
|
||||||
|
search_results.extend(cls.parse_contact_container(contact_container_soup))
|
||||||
|
|
||||||
|
# song
|
||||||
|
# div class: playlist__item
|
||||||
|
for playlist_soup in search_soup.find_all("div", {"class": "playlist"}):
|
||||||
|
search_results.extend(cls.parse_playlist_soup(playlist_soup))
|
||||||
|
|
||||||
|
return Options(search_results)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_album_card(cls, album_card: BeautifulSoup, artist_name: str = None) -> Album:
|
||||||
|
"""
|
||||||
|
<div class="card release-thumbnail" data-type="2">
|
||||||
|
<a href="/release/ghost-bath-self-loather-2021-1554266">
|
||||||
|
<img alt="Self Loather" class="card-img-top lozad" data-src="https://40s-a.musify.club/img/70/24826582/62624396.jpg"/>
|
||||||
|
<noscript><img alt="Self Loather" src="https://40s-a.musify.club/img/70/24826582/62624396.jpg"/></noscript>
|
||||||
|
</a>
|
||||||
|
<div class="card-body">
|
||||||
|
<h4 class="card-subtitle">
|
||||||
|
<a href="/release/ghost-bath-self-loather-2021-1554266">Self Loather</a>
|
||||||
|
</h4>
|
||||||
|
</div>
|
||||||
|
<div class="card-footer"><p class="card-text"><a href="/albums/2021">2021</a></p></div>
|
||||||
|
<div class="card-footer">
|
||||||
|
<p class="card-text genre__labels">
|
||||||
|
<a href="/genre/depressive-black-132">Depressive Black</a><a href="/genre/post-black-metal-295">Post-Black Metal</a> </p>
|
||||||
|
</div>
|
||||||
|
<div class="card-footer">
|
||||||
|
<small><i class="zmdi zmdi-calendar" title="Добавлено"></i> 13.11.2021</small>
|
||||||
|
<small><i class="zmdi zmdi-star zmdi-hc-fw" title="Рейтинг"></i> 5,88</small>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
"""
|
||||||
|
|
||||||
|
album_type_map = defaultdict(lambda: AlbumType.OTHER, {
|
||||||
|
1: AlbumType.OTHER, # literally other xD
|
||||||
|
2: AlbumType.STUDIO_ALBUM,
|
||||||
|
3: AlbumType.EP,
|
||||||
|
4: AlbumType.SINGLE,
|
||||||
|
5: AlbumType.OTHER, # BOOTLEG
|
||||||
|
6: AlbumType.LIVE_ALBUM,
|
||||||
|
7: AlbumType.COMPILATION_ALBUM, # compilation of different artists
|
||||||
|
8: AlbumType.MIXTAPE,
|
||||||
|
9: AlbumType.DEMO,
|
||||||
|
10: AlbumType.MIXTAPE, # DJ Mixes
|
||||||
|
11: AlbumType.COMPILATION_ALBUM, # compilation of only this artist
|
||||||
|
13: AlbumType.COMPILATION_ALBUM, # unofficial
|
||||||
|
14: AlbumType.MIXTAPE # "Soundtracks"
|
||||||
|
})
|
||||||
|
|
||||||
|
_id: Optional[str] = None
|
||||||
|
name: str = None
|
||||||
|
source_list: List[Source] = []
|
||||||
|
timestamp: Optional[ID3Timestamp] = None
|
||||||
|
album_status = None
|
||||||
|
|
||||||
|
def set_name(new_name: str):
|
||||||
|
nonlocal name
|
||||||
|
nonlocal artist_name
|
||||||
|
|
||||||
|
# example of just setting not working: https://musify.club/release/unjoy-eurythmie-psychonaut-4-tired-numb-still-alive-2012-324067
|
||||||
|
if new_name.count(" - ") != 1:
|
||||||
|
name = new_name
|
||||||
|
return
|
||||||
|
|
||||||
|
potential_artist_list, potential_name = new_name.split(" - ")
|
||||||
|
unified_artist_list = string_processing.unify(potential_artist_list)
|
||||||
|
if artist_name is not None:
|
||||||
|
if string_processing.unify(artist_name) not in unified_artist_list:
|
||||||
|
name = new_name
|
||||||
|
return
|
||||||
|
|
||||||
|
name = potential_name
|
||||||
|
return
|
||||||
|
|
||||||
|
name = new_name
|
||||||
|
|
||||||
|
album_status_id = album_card.get("data-type")
|
||||||
|
if album_status_id.isdigit():
|
||||||
|
album_status_id = int(album_status_id)
|
||||||
|
album_type = album_type_map[album_status_id]
|
||||||
|
|
||||||
|
if album_status_id == 5:
|
||||||
|
album_status = AlbumStatus.BOOTLEG
|
||||||
|
|
||||||
|
def parse_release_anchor(_anchor: BeautifulSoup, text_is_name=False):
|
||||||
|
nonlocal _id
|
||||||
|
nonlocal name
|
||||||
|
nonlocal source_list
|
||||||
|
|
||||||
|
if _anchor is None:
|
||||||
|
return
|
||||||
|
|
||||||
|
href = _anchor.get("href")
|
||||||
|
if href is not None:
|
||||||
|
# add url to sources
|
||||||
|
source_list.append(Source(
|
||||||
|
cls.SOURCE_TYPE,
|
||||||
|
cls.HOST + href
|
||||||
|
))
|
||||||
|
|
||||||
|
# split id from url
|
||||||
|
split_href = href.split("-")
|
||||||
|
if len(split_href) > 1:
|
||||||
|
_id = split_href[-1]
|
||||||
|
|
||||||
|
if not text_is_name:
|
||||||
|
return
|
||||||
|
|
||||||
|
set_name(_anchor.text)
|
||||||
|
|
||||||
|
anchor_list = album_card.find_all("a", recursive=False)
|
||||||
|
if len(anchor_list) > 0:
|
||||||
|
anchor = anchor_list[0]
|
||||||
|
parse_release_anchor(anchor)
|
||||||
|
|
||||||
|
thumbnail: BeautifulSoup = anchor.find("img")
|
||||||
|
if thumbnail is not None:
|
||||||
|
alt = thumbnail.get("alt")
|
||||||
|
if alt is not None:
|
||||||
|
set_name(alt)
|
||||||
|
|
||||||
|
image_url = thumbnail.get("src")
|
||||||
|
else:
|
||||||
|
LOGGER.debug("the card has no thumbnail or url")
|
||||||
|
|
||||||
|
card_body = album_card.find("div", {"class": "card-body"})
|
||||||
|
if card_body is not None:
|
||||||
|
parse_release_anchor(card_body.find("a"), text_is_name=True)
|
||||||
|
|
||||||
|
def parse_small_date(small_soup: BeautifulSoup):
|
||||||
|
"""
|
||||||
|
<small>
|
||||||
|
<i class="zmdi zmdi-calendar" title="Добавлено"></i>
|
||||||
|
13.11.2021
|
||||||
|
</small>
|
||||||
|
"""
|
||||||
|
nonlocal timestamp
|
||||||
|
|
||||||
|
italic_tagging_soup: BeautifulSoup = small_soup.find("i")
|
||||||
|
if italic_tagging_soup is None:
|
||||||
|
return
|
||||||
|
if italic_tagging_soup.get("title") != "Добавлено":
|
||||||
|
# "Добавлено" can be translated to "Added (at)"
|
||||||
|
return
|
||||||
|
|
||||||
|
raw_time = small_soup.text.strip()
|
||||||
|
timestamp = ID3Timestamp.strptime(raw_time, "%d.%m.%Y")
|
||||||
|
|
||||||
|
# parse small date
|
||||||
|
card_footer_list = album_card.find_all("div", {"class": "card-footer"})
|
||||||
|
if len(card_footer_list) != 3:
|
||||||
|
LOGGER.debug("there are not exactly 3 card footers in a card")
|
||||||
|
|
||||||
|
if len(card_footer_list) > 0:
|
||||||
|
for any_small_soup in card_footer_list[-1].find_all("small"):
|
||||||
|
parse_small_date(any_small_soup)
|
||||||
|
else:
|
||||||
|
LOGGER.debug("there is not even 1 footer in the album card")
|
||||||
|
|
||||||
|
return cls.ALBUM_CACHE.append(Album(
|
||||||
|
_id=_id,
|
||||||
|
title=name,
|
||||||
|
source_list=source_list,
|
||||||
|
date=timestamp,
|
||||||
|
album_type=album_type,
|
||||||
|
album_status=album_status
|
||||||
|
))
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_discography(cls, url: MusifyUrl, artist_name: str = None, flat=False) -> List[Album]:
|
||||||
|
"""
|
||||||
|
POST https://musify.club/artist/filteralbums
|
||||||
|
ArtistID: 280348
|
||||||
|
SortOrder.Property: dateCreated
|
||||||
|
SortOrder.IsAscending: false
|
||||||
|
X-Requested-With: XMLHttpRequest
|
||||||
|
"""
|
||||||
|
|
||||||
|
endpoint = cls.HOST + "/" + url.source_type.value + "/filteralbums"
|
||||||
|
|
||||||
|
r = cls.post_request(url=endpoint, json={
|
||||||
|
"ArtistID": str(url.musify_id),
|
||||||
|
"SortOrder.Property": "dateCreated",
|
||||||
|
"SortOrder.IsAscending": False,
|
||||||
|
"X-Requested-With": "XMLHttpRequest"
|
||||||
|
})
|
||||||
|
if r is None:
|
||||||
|
return []
|
||||||
|
soup: BeautifulSoup = BeautifulSoup(r.content, features="html.parser")
|
||||||
|
|
||||||
|
discography: List[Album] = []
|
||||||
|
for card_soup in soup.find_all("div", {"class": "card"}):
|
||||||
|
new_album: Album = cls.parse_album_card(card_soup, artist_name)
|
||||||
|
album_source: Source
|
||||||
|
if not flat:
|
||||||
|
for album_source in new_album.source_collection.get_sources_from_page(cls.SOURCE_TYPE):
|
||||||
|
new_album.merge(cls.fetch_album_from_source(album_source))
|
||||||
|
|
||||||
|
discography.append(new_album)
|
||||||
|
|
||||||
|
return discography
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_artist_attributes(cls, url: MusifyUrl) -> Artist:
|
||||||
|
"""
|
||||||
|
fetches the main Artist attributes from this endpoint
|
||||||
|
https://musify.club/artist/ghost-bath-280348?_pjax=#bodyContent
|
||||||
|
it needs to parse html
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
|
||||||
|
r = cls.get_request(f"https://musify.club/{url.source_type.value}/{url.name_with_id}?_pjax=#bodyContent")
|
||||||
|
if r is None:
|
||||||
|
return Artist(_id=url.musify_id)
|
||||||
|
|
||||||
|
soup = BeautifulSoup(r.content, "html.parser")
|
||||||
|
|
||||||
|
"""
|
||||||
|
<ol class="breadcrumb" itemscope="" itemtype="http://schema.org/BreadcrumbList">
|
||||||
|
<li class="breadcrumb-item" itemprop="itemListElement" itemscope="" itemtype="http://schema.org/ListItem"><a href="/" itemprop="item"><span itemprop="name">Главная</span><meta content="1" itemprop="position"/></a></li>
|
||||||
|
<li class="breadcrumb-item" itemprop="itemListElement" itemscope="" itemtype="http://schema.org/ListItem"><a href="/artist" itemprop="item"><span itemprop="name">Исполнители</span><meta content="2" itemprop="position"/></a></li>
|
||||||
|
<li class="breadcrumb-item active">Ghost Bath</li>
|
||||||
|
</ol>
|
||||||
|
|
||||||
|
<ul class="nav nav-tabs nav-fill">
|
||||||
|
<li class="nav-item"><a class="active nav-link" href="/artist/ghost-bath-280348">песни (41)</a></li>
|
||||||
|
<li class="nav-item"><a class="nav-link" href="/artist/ghost-bath-280348/releases">альбомы (12)</a></li>
|
||||||
|
<li class="nav-item"><a class="nav-link" href="/artist/ghost-bath-280348/clips">видеоклипы (23)</a></li>
|
||||||
|
<li class="nav-item"><a class="nav-link" href="/artist/ghost-bath-280348/photos">фото (38)</a></li>
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
<header class="content__title">
|
||||||
|
<h1>Ghost Bath</h1>
|
||||||
|
<div class="actions">
|
||||||
|
...
|
||||||
|
</div>
|
||||||
|
</header>
|
||||||
|
|
||||||
|
<ul class="icon-list">
|
||||||
|
<li>
|
||||||
|
<i class="zmdi zmdi-globe zmdi-hc-fw" title="Страна"></i>
|
||||||
|
<i class="flag-icon US shadow"></i>
|
||||||
|
Соединенные Штаты
|
||||||
|
</li>
|
||||||
|
</ul>
|
||||||
|
"""
|
||||||
|
name = None
|
||||||
|
source_list: List[Source] = []
|
||||||
|
country = None
|
||||||
|
notes: FormattedText = FormattedText()
|
||||||
|
|
||||||
|
breadcrumbs: BeautifulSoup = soup.find("ol", {"class": "breadcrumb"})
|
||||||
|
if breadcrumbs is not None:
|
||||||
|
breadcrumb_list: List[BeautifulSoup] = breadcrumbs.find_all("li", {"class": "breadcrumb-item"}, recursive=False)
|
||||||
|
if len(breadcrumb_list) == 3:
|
||||||
|
name = breadcrumb_list[-1].get_text(strip=True)
|
||||||
|
else:
|
||||||
|
LOGGER.debug("breadcrumb layout on artist page changed")
|
||||||
|
|
||||||
|
nav_tabs: BeautifulSoup = soup.find("ul", {"class": "nav-tabs"})
|
||||||
|
if nav_tabs is not None:
|
||||||
|
list_item: BeautifulSoup
|
||||||
|
for list_item in nav_tabs.find_all("li", {"class": "nav-item"}, recursive=False):
|
||||||
|
if not list_item.get_text(strip=True).startswith("песни"):
|
||||||
|
# "песни" translates to "songs"
|
||||||
|
continue
|
||||||
|
|
||||||
|
anchor: BeautifulSoup = list_item.find("a")
|
||||||
|
if anchor is None:
|
||||||
|
continue
|
||||||
|
href = anchor.get("href")
|
||||||
|
if href is None:
|
||||||
|
continue
|
||||||
|
|
||||||
|
source_list.append(Source(
|
||||||
|
cls.SOURCE_TYPE,
|
||||||
|
cls.HOST + href
|
||||||
|
))
|
||||||
|
|
||||||
|
content_title: BeautifulSoup = soup.find("header", {"class": "content__title"})
|
||||||
|
if content_title is not None:
|
||||||
|
h1_name: BeautifulSoup = content_title.find("h1", recursive=False)
|
||||||
|
if h1_name is not None:
|
||||||
|
name = h1_name.get_text(strip=True)
|
||||||
|
|
||||||
|
# country and sources
|
||||||
|
icon_list: BeautifulSoup = soup.find("ul", {"class": "icon-list"})
|
||||||
|
if icon_list is not None:
|
||||||
|
country_italic: BeautifulSoup = icon_list.find("i", {"class", "flag-icon"})
|
||||||
|
if country_italic is not None:
|
||||||
|
style_classes: set = {'flag-icon', 'shadow'}
|
||||||
|
classes: set = set(country_italic.get("class"))
|
||||||
|
|
||||||
|
country_set: set = classes.difference(style_classes)
|
||||||
|
if len(country_set) != 1:
|
||||||
|
LOGGER.debug("the country set contains multiple values")
|
||||||
|
if len(country_set) != 0:
|
||||||
|
"""
|
||||||
|
This is the css file, where all flags that can be used on musify
|
||||||
|
are laid out and styled.
|
||||||
|
Every flag has two upper case letters, thus I assume they follow the alpha_2
|
||||||
|
standard, though I haven't checked.
|
||||||
|
https://musify.club/content/flags.min.css
|
||||||
|
"""
|
||||||
|
|
||||||
|
country = pycountry.countries.get(alpha_2=list(country_set)[0])
|
||||||
|
|
||||||
|
# get all additional sources
|
||||||
|
additional_source: BeautifulSoup
|
||||||
|
for additional_source in icon_list.find_all("a", {"class", "link"}):
|
||||||
|
href = additional_source.get("href")
|
||||||
|
if href is None:
|
||||||
|
continue
|
||||||
|
new_src = Source.match_url(href)
|
||||||
|
if new_src is None:
|
||||||
|
continue
|
||||||
|
source_list.append(new_src)
|
||||||
|
|
||||||
|
note_soup: BeautifulSoup = soup.find(id="text-main")
|
||||||
|
if note_soup is not None:
|
||||||
|
notes.html = note_soup.decode_contents()
|
||||||
|
|
||||||
|
return Artist(
|
||||||
|
_id=url.musify_id,
|
||||||
|
name=name,
|
||||||
|
country=country,
|
||||||
|
source_list=source_list,
|
||||||
|
notes=notes
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def fetch_artist_from_source(cls, source: Source, flat: bool = False) -> Artist:
|
||||||
|
"""
|
||||||
|
fetches artist from source
|
||||||
|
|
||||||
|
[x] discography
|
||||||
|
[x] attributes
|
||||||
|
[] picture gallery
|
||||||
|
|
||||||
|
Args:
|
||||||
|
source (Source): the source to fetch
|
||||||
|
flat (bool, optional): if it is false, every album from discograohy will be fetched. Defaults to False.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Artist: the artist fetched
|
||||||
|
"""
|
||||||
|
|
||||||
|
url = cls.parse_url(source.url)
|
||||||
|
|
||||||
|
artist = cls.get_artist_attributes(url)
|
||||||
|
|
||||||
|
discography: List[Album] = cls.get_discography(url, artist.name)
|
||||||
|
artist.main_album_collection.extend(discography)
|
||||||
|
|
||||||
|
return artist
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_song_card(cls, song_card: BeautifulSoup) -> Song:
|
||||||
|
"""
|
||||||
|
<div id="playerDiv3051" class="playlist__item" itemprop="track" itemscope="itemscope" itemtype="http://schema.org/MusicRecording" data-artist="Linkin Park" data-name="Papercut">
|
||||||
|
<div id="play_3051" class="playlist__control play" data-url="/track/play/3051/linkin-park-papercut.mp3" data-position="1" data-title="Linkin Park - Papercut" title="Слушать Linkin Park - Papercut">
|
||||||
|
<span class="ico-play"><i class="zmdi zmdi-play-circle-outline zmdi-hc-2-5x"></i></span>
|
||||||
|
<span class="ico-pause"><i class="zmdi zmdi-pause-circle-outline zmdi-hc-2-5x"></i></span>
|
||||||
|
</div>
|
||||||
|
<div class="playlist__position">
|
||||||
|
1
|
||||||
|
</div>
|
||||||
|
<div class="playlist__details">
|
||||||
|
<div class="playlist__heading">
|
||||||
|
<a href="/artist/linkin-park-5" rel="nofollow">Linkin Park</a> - <a class="strong" href="/track/linkin-park-papercut-3051">Papercut</a>
|
||||||
|
<span itemprop="byArtist" itemscope="itemscope" itemtype="http://schema.org/MusicGroup">
|
||||||
|
<meta content="/artist/linkin-park-5" itemprop="url" />
|
||||||
|
<meta content="Linkin Park" itemprop="name" />
|
||||||
|
</span>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
<div>
|
||||||
|
<div class="track__details track__rating hidden-xs-down">
|
||||||
|
<span class="text-muted">
|
||||||
|
<i class="zmdi zmdi-star-circle zmdi-hc-1-3x" title="Рейтинг"></i>
|
||||||
|
326,3K
|
||||||
|
</span>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
<div class="track__details hidden-xs-down">
|
||||||
|
<span class="text-muted">03:05</span>
|
||||||
|
<span class="text-muted">320 Кб/с</span>
|
||||||
|
</div>
|
||||||
|
<div class="track__details hidden-xs-down">
|
||||||
|
<span title='Есть видео Linkin Park - Papercut'><i class='zmdi zmdi-videocam zmdi-hc-1-3x'></i></span>
|
||||||
|
<span title='Есть текст Linkin Park - Papercut'><i class='zmdi zmdi-file-text zmdi-hc-1-3x'></i></span>
|
||||||
|
</div>
|
||||||
|
<div class="playlist__actions">
|
||||||
|
<span class="pl-btn save-to-pl" id="add_3051" title="Сохранить в плейлист"><i class="zmdi zmdi-plus zmdi-hc-1-5x"></i></span>
|
||||||
|
<a target="_blank" itemprop="audio" download="Linkin Park - Papercut.mp3" href="/track/dl/3051/linkin-park-papercut.mp3" class="no-ajaxy yaBrowser" id="dl_3051" title='Скачать Linkin Park - Papercut'>
|
||||||
|
<span><i class="zmdi zmdi-download zmdi-hc-2-5x"></i></span>
|
||||||
|
</a>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
"""
|
||||||
|
song_name = song_card.get("data-name")
|
||||||
|
artist_list: List[Artist] = []
|
||||||
|
source_list: List[Source] = []
|
||||||
|
tracksort = None
|
||||||
|
|
||||||
|
def parse_title(_title: str) -> str:
|
||||||
|
return _title
|
||||||
|
|
||||||
|
"""
|
||||||
|
# get from parent div
|
||||||
|
_artist_name = song_card.get("data-artist")
|
||||||
|
if _artist_name is not None:
|
||||||
|
artist_list.append(Artist(name=_artist_name))
|
||||||
|
"""
|
||||||
|
|
||||||
|
# get tracksort
|
||||||
|
tracksort_soup: BeautifulSoup = song_card.find("div", {"class": "playlist__position"})
|
||||||
|
if tracksort_soup is not None:
|
||||||
|
raw_tracksort: str = tracksort_soup.get_text(strip=True)
|
||||||
|
if raw_tracksort.isdigit():
|
||||||
|
tracksort = int(raw_tracksort)
|
||||||
|
|
||||||
|
# playlist details
|
||||||
|
playlist_details: BeautifulSoup = song_card.find("div", {"class": "playlist__details"})
|
||||||
|
if playlist_details is not None:
|
||||||
|
"""
|
||||||
|
<div class="playlist__heading">
|
||||||
|
<a href="/artist/tamas-141317" rel="nofollow">Tamas</a> ft.<a href="/artist/zombiez-630767" rel="nofollow">Zombiez</a> - <a class="strong" href="/track/tamas-zombiez-voodoo-feat-zombiez-16185276">Voodoo (Feat. Zombiez)</a>
|
||||||
|
<span itemprop="byArtist" itemscope="itemscope" itemtype="http://schema.org/MusicGroup">
|
||||||
|
<meta content="/artist/tamas-141317" itemprop="url" />
|
||||||
|
<meta content="Tamas" itemprop="name" />
|
||||||
|
</span>
|
||||||
|
<span itemprop="byArtist" itemscope="itemscope" itemtype="http://schema.org/MusicGroup">
|
||||||
|
<meta content="/artist/zombiez-630767" itemprop="url" />
|
||||||
|
<meta content="Zombiez" itemprop="name" />
|
||||||
|
</span>
|
||||||
|
</div>
|
||||||
|
"""
|
||||||
|
# track
|
||||||
|
anchor_list: List[BeautifulSoup] = playlist_details.find_all("a")
|
||||||
|
if len(anchor_list) > 1:
|
||||||
|
track_anchor: BeautifulSoup = anchor_list[-1]
|
||||||
|
href: str = track_anchor.get("href")
|
||||||
|
if href is not None:
|
||||||
|
source_list.append(Source(cls.SOURCE_TYPE, cls.HOST + href))
|
||||||
|
song_name = parse_title(track_anchor.get_text(strip=True))
|
||||||
|
|
||||||
|
# artist
|
||||||
|
artist_span: BeautifulSoup
|
||||||
|
for artist_span in playlist_details.find_all("span", {"itemprop": "byArtist"}):
|
||||||
|
_artist_src = None
|
||||||
|
_artist_name = None
|
||||||
|
meta_artist_src = artist_span.find("meta", {"itemprop": "url"})
|
||||||
|
if meta_artist_src is not None:
|
||||||
|
meta_artist_url = meta_artist_src.get("content")
|
||||||
|
if meta_artist_url is not None:
|
||||||
|
_artist_src = [Source(cls.SOURCE_TYPE, cls.HOST + meta_artist_url)]
|
||||||
|
|
||||||
|
meta_artist_name = artist_span.find("meta", {"itemprop": "name"})
|
||||||
|
if meta_artist_name is not None:
|
||||||
|
meta_artist_name_text = meta_artist_name.get("content")
|
||||||
|
_artist_name = meta_artist_name_text
|
||||||
|
|
||||||
|
if _artist_name is not None or _artist_src is not None:
|
||||||
|
artist_list.append(Artist(name=_artist_name, source_list=_artist_src))
|
||||||
|
|
||||||
|
return Song(
|
||||||
|
title=song_name,
|
||||||
|
tracksort=tracksort,
|
||||||
|
main_artist_list=artist_list
|
||||||
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def fetch_album_from_source(cls, source: Source, flat: bool = False) -> Album:
|
||||||
|
"""
|
||||||
|
fetches album from source:
|
||||||
|
eg. 'https://musify.club/release/linkin-park-hybrid-theory-2000-188'
|
||||||
|
|
||||||
|
/html/musify/album_overview.html
|
||||||
|
[] tracklist
|
||||||
|
[] attributes
|
||||||
|
[] ratings
|
||||||
|
|
||||||
|
:param source:
|
||||||
|
:param flat:
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
album = Album(title="Hi :)")
|
||||||
|
|
||||||
|
url = cls.parse_url(source.url)
|
||||||
|
|
||||||
|
endpoint = cls.HOST + "/release/" + url.name_with_id
|
||||||
|
r = cls.get_request(endpoint)
|
||||||
|
if r is None:
|
||||||
|
return album
|
||||||
|
|
||||||
|
soup = BeautifulSoup(r.content, "html.parser")
|
||||||
|
|
||||||
|
# <div class="card"><div class="card-body">...</div></div>
|
||||||
|
cards_soup: BeautifulSoup = soup.find("div", {"class": "card-body"})
|
||||||
|
if cards_soup is not None:
|
||||||
|
card_soup: BeautifulSoup
|
||||||
|
for card_soup in cards_soup.find_all("div", {"class": "playlist__item"}):
|
||||||
|
album.song_collection.append(cls.parse_song_card(card_soup))
|
||||||
|
album.update_tracksort()
|
||||||
|
|
||||||
|
return album
|
||||||
@@ -0,0 +1,30 @@
|
|||||||
|
from music_kraken import objects
|
||||||
|
from music_kraken.pages import Musify
|
||||||
|
|
||||||
|
|
||||||
|
def search():
|
||||||
|
results = Musify.search_by_query("#a Ghost Bath")
|
||||||
|
print(results)
|
||||||
|
|
||||||
|
|
||||||
|
def fetch_artist():
|
||||||
|
artist = objects.Artist(
|
||||||
|
source_list=[objects.Source(objects.SourcePages.MUSIFY, "https://musify.club/artist/psychonaut-4-83193")]
|
||||||
|
)
|
||||||
|
|
||||||
|
artist = Musify.fetch_details(artist)
|
||||||
|
print(artist.options)
|
||||||
|
|
||||||
|
|
||||||
|
def fetch_album():
|
||||||
|
album = objects.Album(
|
||||||
|
source_list=[objects.Source(objects.SourcePages.MUSIFY,
|
||||||
|
"https://musify.club/release/linkin-park-hybrid-theory-2000-188")]
|
||||||
|
)
|
||||||
|
|
||||||
|
album = Musify.fetch_details(album)
|
||||||
|
print(album.options)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
fetch_album()
|
||||||
Reference in New Issue
Block a user