Merge pull request #3 from GabrieleAncillai/development
edited readme + cli improvements
This commit is contained in:
@@ -10,3 +10,6 @@ __pycache__/
|
|||||||
|
|
||||||
/build/*
|
/build/*
|
||||||
!/build/build.sh
|
!/build/build.sh
|
||||||
|
|
||||||
|
# Virtual Environment
|
||||||
|
venv
|
||||||
|
|||||||
Generated
+1
-1
@@ -1,4 +1,4 @@
|
|||||||
<?xml version="1.0" encoding="UTF-8"?>
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
<project version="4">
|
<project version="4">
|
||||||
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.10" project-jdk-type="Python SDK" />
|
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.10 (music-downloader)" project-jdk-type="Python SDK" />
|
||||||
</project>
|
</project>
|
||||||
Generated
+1
-1
@@ -4,7 +4,7 @@
|
|||||||
<content url="file://$MODULE_DIR$">
|
<content url="file://$MODULE_DIR$">
|
||||||
<excludeFolder url="file://$MODULE_DIR$/venv" />
|
<excludeFolder url="file://$MODULE_DIR$/venv" />
|
||||||
</content>
|
</content>
|
||||||
<orderEntry type="jdk" jdkName="Python 3.10" jdkType="Python SDK" />
|
<orderEntry type="jdk" jdkName="Python 3.10 (music-downloader)" jdkType="Python SDK" />
|
||||||
<orderEntry type="sourceFolder" forTests="false" />
|
<orderEntry type="sourceFolder" forTests="false" />
|
||||||
<orderEntry type="module" module-name="rythmbox-id3-lyrics-support" />
|
<orderEntry type="module" module-name="rythmbox-id3-lyrics-support" />
|
||||||
</component>
|
</component>
|
||||||
|
|||||||
@@ -1,3 +1,4 @@
|
|||||||
|
from .utils.functions import *
|
||||||
from .utils.shared import *
|
from .utils.shared import *
|
||||||
|
|
||||||
from .metadata import (
|
from .metadata import (
|
||||||
@@ -37,24 +38,42 @@ def get_existing_genre():
|
|||||||
|
|
||||||
|
|
||||||
def search_for_metadata():
|
def search_for_metadata():
|
||||||
|
clear_console()
|
||||||
|
|
||||||
search = metadata_search.Search()
|
search = metadata_search.Search()
|
||||||
|
|
||||||
while True:
|
while True:
|
||||||
input_ = input(
|
input_ = input(
|
||||||
"q to quit, .. for previous options, int for this element, str to search for query, ok to download\n")
|
"""
|
||||||
input_.strip()
|
- - - Type the command you want to execute - - -
|
||||||
if input_.lower() == "ok":
|
.. - Previous Options
|
||||||
break
|
(query_string) - Search for songs, albums, bands...
|
||||||
if input_.lower() == "q":
|
(int) - Select an item from the search results
|
||||||
break
|
d - Start the download
|
||||||
if input_.lower() == "..":
|
h - Help
|
||||||
print()
|
q - Quit / Exit
|
||||||
print(search.get_previous_options())
|
|
||||||
continue
|
command: """
|
||||||
if input_.isdigit():
|
)
|
||||||
print()
|
|
||||||
print(search.choose(int(input_)))
|
match (input_.strip().lower()):
|
||||||
continue
|
case "d" | "ok" | "dl" | "download":
|
||||||
|
break
|
||||||
|
case "q" | "quit" | "exit":
|
||||||
|
clear_console()
|
||||||
|
exit()
|
||||||
|
case "h" | "help":
|
||||||
|
print()
|
||||||
|
# TODO: Help text (mainly explaining query strings and alternative command functionalities)
|
||||||
|
print("Insert here help text....")
|
||||||
|
case inp if inp.isdigit():
|
||||||
|
print()
|
||||||
|
print(search.choose(int(input_)))
|
||||||
|
continue
|
||||||
|
case ".." :
|
||||||
|
print()
|
||||||
|
print(search.get_previous_options())
|
||||||
|
|
||||||
print()
|
print()
|
||||||
print(search.search_from_query(input_))
|
print(search.search_from_query(input_))
|
||||||
|
|
||||||
@@ -81,6 +100,8 @@ def get_genre():
|
|||||||
|
|
||||||
|
|
||||||
def cli(start_at: int = 0, only_lyrics: bool = False):
|
def cli(start_at: int = 0, only_lyrics: bool = False):
|
||||||
|
clear_console()
|
||||||
|
|
||||||
if start_at <= 2 and not only_lyrics:
|
if start_at <= 2 and not only_lyrics:
|
||||||
genre = get_genre()
|
genre = get_genre()
|
||||||
logging.info(f"{genre} has been set as genre.")
|
logging.info(f"{genre} has been set as genre.")
|
||||||
@@ -107,3 +128,7 @@ def cli(start_at: int = 0, only_lyrics: bool = False):
|
|||||||
if start_at <= 4:
|
if start_at <= 4:
|
||||||
logging.info("starting to fetch the lyrics")
|
logging.info("starting to fetch the lyrics")
|
||||||
lyrics.fetch_lyrics()
|
lyrics.fetch_lyrics()
|
||||||
|
|
||||||
|
|
||||||
|
def gtk_gui():
|
||||||
|
pass
|
||||||
|
|||||||
@@ -14,7 +14,7 @@ class Option:
|
|||||||
def __init__(self, type_: str, id_: str, name: str, additional_info: str = "") -> None:
|
def __init__(self, type_: str, id_: str, name: str, additional_info: str = "") -> None:
|
||||||
# print(type_, id_, name)
|
# print(type_, id_, name)
|
||||||
if type_ not in OPTION_TYPES:
|
if type_ not in OPTION_TYPES:
|
||||||
raise ValueError(f"type: {type_} doesn't exist. Leagal Values: {OPTION_TYPES}")
|
raise ValueError(f"type: {type_} doesn't exist. Legal Values: {OPTION_TYPES}")
|
||||||
self.type = type_
|
self.type = type_
|
||||||
self.name = name
|
self.name = name
|
||||||
self.id = id_
|
self.id = id_
|
||||||
|
|||||||
@@ -16,7 +16,7 @@ License-File: LICENSE
|
|||||||
|
|
||||||
RUN WITH: `python3 -m src` from the project Directory
|
RUN WITH: `python3 -m src` from the project Directory
|
||||||
|
|
||||||
This programm will first get the metadata of various songs from metadata provider like musicbrainz, and then search for download links on pages like bandcamp. Then it will download the song and edit the metadata according.
|
This program will first get the metadata of various songs from metadata provider like musicbrainz, and then search for download links on pages like bandcamp. Then it will download the song and edit the metadata according.
|
||||||
|
|
||||||
## Metadata
|
## Metadata
|
||||||
|
|
||||||
@@ -26,9 +26,9 @@ First the metadata has to be downloaded. The best api to do so is undeniably [Mu
|
|||||||
|
|
||||||
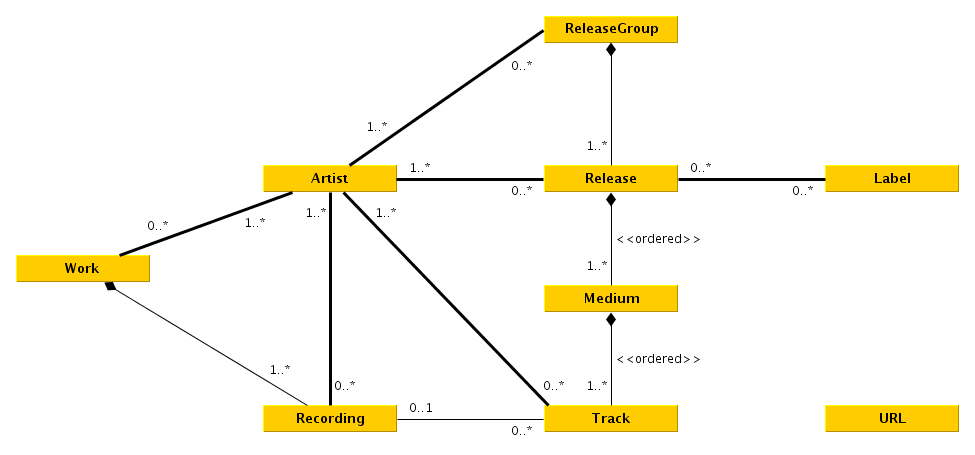
|

|
||||||
|
|
||||||
To fetch from [Musicbrainz](musicbrainz.org/) we first have to know what to fetch. A good start is to get an input querry, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
To fetch from [Musicbrainz](musicbrainz.org/) we first have to know what to fetch. A good start is to get an input query, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
||||||
|
|
||||||
Then we can output them in the Terminal and ask for further input. Following can be inputed afterwards:
|
Then we can output them in the Terminal and ask for further input. Following can be inputted afterwards:
|
||||||
|
|
||||||
- `q` to quit
|
- `q` to quit
|
||||||
- `ok` to download
|
- `ok` to download
|
||||||
@@ -36,18 +36,18 @@ Then we can output them in the Terminal and ask for further input. Following can
|
|||||||
- `.` for current options
|
- `.` for current options
|
||||||
- `an integer` for this element
|
- `an integer` for this element
|
||||||
|
|
||||||
If the following chosen element is an artist, its discography + a couple tracks are outputed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
If the following chosen element is an artist, its discography + a couple tracks are outputted, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
||||||
|
|
||||||
**TO DO**
|
**TO DO**
|
||||||
|
|
||||||
- Schow always the whole tracklist of an release if it is chosen
|
- Show always the whole tracklist of an release if it is chosen
|
||||||
- Show always the whole discography of an artist if it is chosen
|
- Show always the whole discography of an artist if it is chosen
|
||||||
|
|
||||||
Up to now it doesn't if the discography or tracklist is chosen.
|
Up to now it doesn't if the discography or tracklist is chosen.
|
||||||
|
|
||||||
### Metadata to fetch
|
### Metadata to fetch
|
||||||
|
|
||||||
I orient on which metadata to download on the keys in `mutagen.EasyID3` . Following I fatch and thus tag the MP3 with:
|
I orient on which metadata to download on the keys in `mutagen.EasyID3` . Following I fetch and thus tag the MP3 with:
|
||||||
- title
|
- title
|
||||||
- artist
|
- artist
|
||||||
- albumartist
|
- albumartist
|
||||||
@@ -70,7 +70,7 @@ Those Tags are for the musicplayer to not sort for Example the albums of a band
|
|||||||
|
|
||||||
#### isrc
|
#### isrc
|
||||||
|
|
||||||
This is the **international standart release code**. With this a track can be identified 100% percicely all of the time, if it is known and the website has a search api for that. Obviously this will get important later.
|
This is the **international standard release code**. With this a track can be identified 100% precisely all of the time, if it is known and the website has a search api for that. Obviously this will get important later.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -80,7 +80,7 @@ Now that the metadata is downloaded and cached, download sources need to be soun
|
|||||||
|
|
||||||
### Musify
|
### Musify
|
||||||
|
|
||||||
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). Its a russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search suff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottelneck defently is not at the speed of those requests.
|
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). Its a russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search stuff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottleneck definitely is not at the speed of those requests.
|
||||||
|
|
||||||
For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
|
For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
|
||||||
|
|
||||||
@@ -101,29 +101,29 @@ For musify the endpoint is following: [https://musify.club/search/suggestions?te
|
|||||||
|
|
||||||
This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
|
This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
|
||||||
|
|
||||||
- call the api with the querry being the track name
|
- call the api with the query being the track name
|
||||||
- parse the json response to an object
|
- parse the json response to an object
|
||||||
- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
|
- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
|
||||||
- If they match get the download links and cache them.
|
- If they match get the download links and cache them.
|
||||||
|
|
||||||
### Youtube
|
### Youtube
|
||||||
|
|
||||||
Herte the **isrc** plays a huge role. You probaply know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
|
Here the **isrc** plays a huge role. You probably know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
|
||||||
|
|
||||||
Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
|
Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
|
||||||
|
|
||||||
For searching, as well as for downloading I use the programm `youtube-dl`, which also has a programming interface for python.
|
For searching, as well as for downloading I use the program `youtube-dl`, which also has a programming interface for python.
|
||||||
|
|
||||||
There are two bottlenecks with this approach though:
|
There are two bottlenecks with this approach though:
|
||||||
1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
|
1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
|
||||||
2. Ofthen musicbrainz just doesn't give the isrc for some songs.
|
2. Often musicbrainz just doesn't give the isrc for some songs.
|
||||||
|
|
||||||
**TODO**
|
**TODO**
|
||||||
- look at how the isrc id derived an try to generate it for the tracks without directly getting it from mb.
|
- look at how the isrc id derived an try to generate it for the tracks without directly getting it from mb.
|
||||||
|
|
||||||
|
|
||||||
**Progress**
|
**Progress**
|
||||||
- There is a great site whith a huge isrc database [https://isrc.soundexchange.com/](https://isrc.soundexchange.com/).
|
- There is a great site with a huge isrc database [https://isrc.soundexchange.com/](https://isrc.soundexchange.com/).
|
||||||
|
|
||||||
|
|
||||||
## Lyrics
|
## Lyrics
|
||||||
@@ -158,7 +158,7 @@ music-downloader
|
|||||||
├── metadata
|
├── metadata
|
||||||
│ ├── database.py
|
│ ├── database.py
|
||||||
│ ├── download.py
|
│ ├── download.py
|
||||||
│ ├── object_handeling.py
|
│ ├── object_handling.py
|
||||||
│ └── search.py
|
│ └── search.py
|
||||||
├── scraping
|
├── scraping
|
||||||
│ ├── file_system.py
|
│ ├── file_system.py
|
||||||
@@ -167,7 +167,7 @@ music-downloader
|
|||||||
│ └── youtube_music.py
|
│ └── youtube_music.py
|
||||||
├── url_to_path.py
|
├── url_to_path.py
|
||||||
└── utils
|
└── utils
|
||||||
├── object_handeling.py
|
├── object_handling.py
|
||||||
├── phonetic_compares.py
|
├── phonetic_compares.py
|
||||||
└── shared.py
|
└── shared.py
|
||||||
|
|
||||||
|
|||||||
@@ -1,2 +1,2 @@
|
|||||||
# tells what exists
|
# tells what exists
|
||||||
__all__ = ["shared", "object_handeling", "phonetic_compares"]
|
__all__ = ["shared", "object_handeling", "phonetic_compares", "functions"]
|
||||||
|
|||||||
@@ -0,0 +1,4 @@
|
|||||||
|
import os
|
||||||
|
|
||||||
|
def clear_console():
|
||||||
|
os.system('cls' if os.name in ('nt', 'dos') else 'clear')
|
||||||
@@ -0,0 +1,4 @@
|
|||||||
|
from music_kraken import gtk_gui
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
gtk_gui()
|
||||||
Reference in New Issue
Block a user