temporarily finished the documentation
This commit is contained in:
69
README.md
69
README.md
@@ -64,13 +64,18 @@ mk.cli()
|
|||||||
### Search for Metadata
|
### Search for Metadata
|
||||||
|
|
||||||
The whole programm takes the data it processes further from the cache, a sqlite database.
|
The whole programm takes the data it processes further from the cache, a sqlite database.
|
||||||
So before you can do anything, you will need to fill it with the songs you want to download.
|
So before you can do anything, you will need to fill it with the songs you want to download (*or create song objects manually, but more on that later*).
|
||||||
For now the base of everything is musicbrainz, so you need to get the
|
|
||||||
musicbrainz id and the type the id corresponds to (artist/release group/release/track).
|
For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type` the id corresponds to either
|
||||||
To get this you first have to initialize a search object (`music_kraken.metadata.metadata_search.Search`).
|
- an artist
|
||||||
|
- a release group
|
||||||
|
- a release
|
||||||
|
- a recording/track).
|
||||||
|
|
||||||
|
To get this info, you first have to initialize a search object (`music_kraken.MetadataSearch`).
|
||||||
|
|
||||||
```python
|
```python
|
||||||
search_object = mk.metadata.metadata_search.Search()
|
search_object = music_kraken.MetadataSearch()
|
||||||
```
|
```
|
||||||
|
|
||||||
Then you need an initial "text search" to get some options you can choose from. For
|
Then you need an initial "text search" to get some options you can choose from. For
|
||||||
@@ -91,7 +96,7 @@ print(multiple_options)
|
|||||||
|
|
||||||
After the first "*text search*" you can either again search the same way as before,
|
After the first "*text search*" you can either again search the same way as before,
|
||||||
or you can further explore one of the options from the previous search.
|
or you can further explore one of the options from the previous search.
|
||||||
To explore and select one options from `MultipleOptions`, simply call `Search.choose(self, index: int)`.
|
To explore and select one options from `MultipleOptions`, simply call `MetadataSearch.choose(self, index: int)`.
|
||||||
The index represents the number in the previously returned instance of MultipleOptions.
|
The index represents the number in the previously returned instance of MultipleOptions.
|
||||||
The selected Option will be selected and can be downloaded in the next step.
|
The selected Option will be selected and can be downloaded in the next step.
|
||||||
|
|
||||||
@@ -111,29 +116,32 @@ A search history is kept in the Search instance. You could go back to
|
|||||||
the previous search (without any loading time) like this:
|
the previous search (without any loading time) like this:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
multiple_options = search.get_previous_options()
|
multiple_options = search_object.get_previous_options()
|
||||||
```
|
```
|
||||||
|
|
||||||
### Downloading Metadata / Filling up the Cache
|
### Downloading Metadata / Filling up the Cache
|
||||||
|
|
||||||
If you selected the Option you want with `Search.choose(i)`, you can
|
You can download following metadata:
|
||||||
finally download the metadata of either:
|
|
||||||
- an artist (the whole discography)
|
- an artist (the whole discography)
|
||||||
- a release group
|
- a release group
|
||||||
- a release
|
- a release
|
||||||
- a track/recording
|
- a track/recording
|
||||||
To download you need the selected Option Object (`music_kraken.metadata.metadata_search.Option`)
|
|
||||||
it is simply stored in `Search.current_option`.
|
|
||||||
|
|
||||||
If you already know what you want to download you can skip all the steps above and just create
|
If you got an instance of `MetadataSearch`, like I elaborated [previously](#search-for-metadata), downloading every piece of metadata from the currently selected Option is really quite easy.
|
||||||
a dictionary like this and use it later (*might change and break after I add multiple metadata sources which I will*):
|
|
||||||
```python
|
```python
|
||||||
download_dict = {
|
# this is it :)
|
||||||
'type': option_type,
|
music_kraken.fetch_metadata_from_search(search_object)
|
||||||
'id': musicbrainz_id
|
|
||||||
}
|
|
||||||
```
|
```
|
||||||
The option type is a string (I'm sorry for not making it an enum I know its a bad pratice), which can
|
|
||||||
|
If you already know what you want to download you can skip the search instance and simply do the following.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# might change and break after I add multiple metadata sources which I will
|
||||||
|
|
||||||
|
music_kraken.fetch_metadata(id_=musicbrainz_id, type=metadata_type)
|
||||||
|
```
|
||||||
|
The option type is a string (*I'm sorry for not making it an enum I know its a bad pratice*), which can
|
||||||
have following values:
|
have following values:
|
||||||
- 'artist'
|
- 'artist'
|
||||||
- 'release_group'
|
- 'release_group'
|
||||||
@@ -144,26 +152,6 @@ have following values:
|
|||||||
|
|
||||||
The musicbrainz id is just the id of the object from musicbrainz.
|
The musicbrainz id is just the id of the object from musicbrainz.
|
||||||
|
|
||||||
```python
|
|
||||||
# in this example I will choose the previous selected option.
|
|
||||||
option_to_download = search_object.current_option
|
|
||||||
print(option_to_download)
|
|
||||||
|
|
||||||
download_dict = {
|
|
||||||
'type': option_to_download.type,
|
|
||||||
'id': option_to_download.id
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
If you got the Option instance you want to download and created the dictionary, then downloading the metadata is really straight
|
|
||||||
forward, so I just show the code.
|
|
||||||
|
|
||||||
```python
|
|
||||||
# I am aware of abstrackt classes
|
|
||||||
metadata_downloader = mk.metadata.metadata_fetch.MetadataDownloader()
|
|
||||||
metadata_downloader.download(download_dict)
|
|
||||||
```
|
|
||||||
|
|
||||||
After following those steps, it might take a couple seconds/minutes to execute, but then the Cache will be filled.
|
After following those steps, it might take a couple seconds/minutes to execute, but then the Cache will be filled.
|
||||||
|
|
||||||
|
|
||||||
@@ -238,13 +226,13 @@ To download audio two cases have to be met:
|
|||||||
|
|
||||||
## Metadata
|
## Metadata
|
||||||
|
|
||||||
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz](musicbrainz.org/). This is a result of them being a website with a large Database spanning over all Genres.
|
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz][mb]. This is a result of them being a website with a large Database spanning over all Genres.
|
||||||
|
|
||||||
### Musicbrainz
|
### Musicbrainz
|
||||||
|
|
||||||
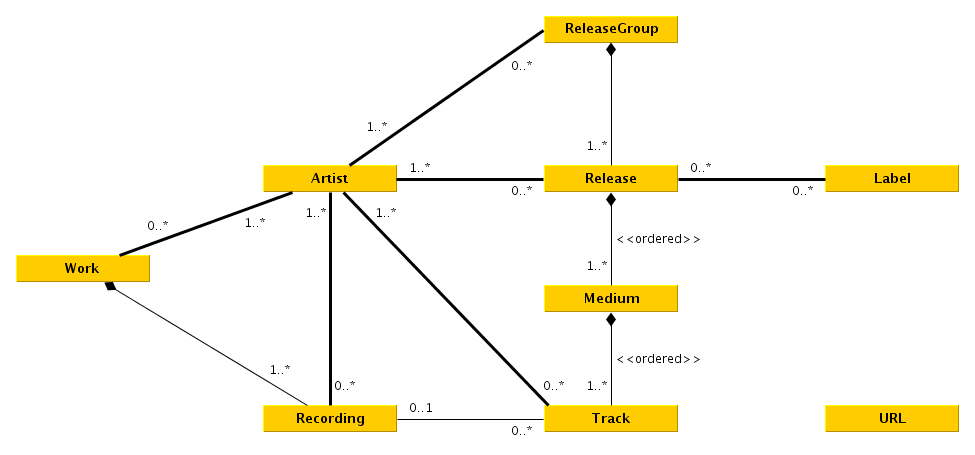
|

|
||||||
|
|
||||||
To fetch from [Musicbrainz](musicbrainz.org/) we first have to know what to fetch. A good start is to get an input querry, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
To fetch from [Musicbrainz][mb] we first have to know what to fetch. A good start is to get an input querry, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
||||||
|
|
||||||
If the following chosen element is an artist, its discography + a couple tracks are printed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
If the following chosen element is an artist, its discography + a couple tracks are printed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
||||||
|
|
||||||
@@ -332,3 +320,4 @@ For the lyrics source the page [https://genius.com/](https://genius.com/) is eas
|
|||||||
|
|
||||||
|
|
||||||
[i2]: https://github.com/HeIIow2/music-downloader/issues/2
|
[i2]: https://github.com/HeIIow2/music-downloader/issues/2
|
||||||
|
[mb]: musicbrainz.org/
|
||||||
|
|||||||
@@ -6,7 +6,8 @@ import os
|
|||||||
from . import (
|
from . import (
|
||||||
database,
|
database,
|
||||||
audio_source,
|
audio_source,
|
||||||
target
|
target,
|
||||||
|
metadata
|
||||||
)
|
)
|
||||||
|
|
||||||
from .utils.shared import (
|
from .utils.shared import (
|
||||||
@@ -25,9 +26,18 @@ musicbrainzngs.set_useragent("metadata receiver", "0.1", "https://github.com/HeI
|
|||||||
|
|
||||||
# define the most important values and function for import in the __init__ file
|
# define the most important values and function for import in the __init__ file
|
||||||
Song = database.song.Song
|
Song = database.song.Song
|
||||||
|
MetadataSearch = metadata.metadata_search.Search
|
||||||
|
|
||||||
cache = database.cache
|
cache = database.cache
|
||||||
|
|
||||||
|
def fetch_metadata(type: str, id_: str):
|
||||||
|
metadata_downloader = metadata_fetch.MetadataDownloader()
|
||||||
|
metadata_downloader.download({'type': type, 'id': id_})
|
||||||
|
|
||||||
|
def fetch_metadata_from_search(search_instace: MetadataSearch):
|
||||||
|
current_option = search_instace.current_option
|
||||||
|
fetch_metadata(type=current_option.type, id_= current_option.id)
|
||||||
|
|
||||||
def set_targets(genre: str):
|
def set_targets(genre: str):
|
||||||
target.set_target.UrlPath(genre=genre)
|
target.set_target.UrlPath(genre=genre)
|
||||||
|
|
||||||
@@ -97,7 +107,7 @@ def execute_input(_input: str, search: metadata_search.Search) -> bool:
|
|||||||
|
|
||||||
|
|
||||||
def search_for_metadata():
|
def search_for_metadata():
|
||||||
search = metadata_search.Search()
|
search = MetadataSearch()
|
||||||
|
|
||||||
while True:
|
while True:
|
||||||
_input = input("\"help\" for an overview of commands: ")
|
_input = input("\"help\" for an overview of commands: ")
|
||||||
@@ -134,8 +144,8 @@ def cli(start_at: int = 0, only_lyrics: bool = False):
|
|||||||
if start_at <= 0:
|
if start_at <= 0:
|
||||||
search = search_for_metadata()
|
search = search_for_metadata()
|
||||||
logging.info("Starting Downloading of metadata")
|
logging.info("Starting Downloading of metadata")
|
||||||
metadata_downloader = metadata_fetch.MetadataDownloader()
|
fetch_metadata_from_search(search)
|
||||||
metadata_downloader.download({'type': search.type, 'id': search.id})
|
|
||||||
|
|
||||||
if start_at <= 1 and not only_lyrics:
|
if start_at <= 1 and not only_lyrics:
|
||||||
logging.info("creating Paths")
|
logging.info("creating Paths")
|
||||||
|
|||||||
Reference in New Issue
Block a user