refactored packaging
This commit is contained in:
@@ -1,3 +1,17 @@
|
|||||||
|
|
||||||
|
rm /tmp/music-downloader/*.db
|
||||||
|
rm /tmp/music-downloader/*.sql
|
||||||
|
|
||||||
|
version=$(cut -d@ -f1 version)
|
||||||
|
echo version: $version
|
||||||
|
|
||||||
|
python3 setup.py sdist bdist_wheel
|
||||||
|
sudo python3 -m pip uninstall music-kraken -y
|
||||||
|
|
||||||
|
python3 -m pip install dist/music-kraken-$version.tar.gz --user
|
||||||
|
music-kraken
|
||||||
|
exit
|
||||||
|
|
||||||
# https://packaging.python.org/en/latest/tutorials/packaging-projects/
|
# https://packaging.python.org/en/latest/tutorials/packaging-projects/
|
||||||
#echo "building............"
|
#echo "building............"
|
||||||
#echo "python3 -m pip install --upgrade build"
|
#echo "python3 -m pip install --upgrade build"
|
||||||
|
|||||||
@@ -1,66 +0,0 @@
|
|||||||
DROP TABLE IF EXISTS artist;
|
|
||||||
CREATE TABLE artist (
|
|
||||||
id TEXT PRIMARY KEY NOT NULL,
|
|
||||||
name TEXT
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS artist_release_group;
|
|
||||||
CREATE TABLE artist_release_group (
|
|
||||||
artist_id TEXT NOT NULL,
|
|
||||||
release_group_id TEXT NOT NULL
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS artist_track;
|
|
||||||
CREATE TABLE artist_track (
|
|
||||||
artist_id TEXT NOT NULL,
|
|
||||||
track_id TEXT NOT NULL
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS release_group;
|
|
||||||
CREATE TABLE release_group (
|
|
||||||
id TEXT PRIMARY KEY NOT NULL,
|
|
||||||
albumartist TEXT,
|
|
||||||
albumsort INT,
|
|
||||||
musicbrainz_albumtype TEXT,
|
|
||||||
compilation TEXT,
|
|
||||||
album_artist_id TEXT
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS release_;
|
|
||||||
CREATE TABLE release_ (
|
|
||||||
id TEXT PRIMARY KEY NOT NULL,
|
|
||||||
release_group_id TEXT NOT NULL,
|
|
||||||
title TEXT,
|
|
||||||
copyright TEXT,
|
|
||||||
album_status TEXT,
|
|
||||||
language TEXT,
|
|
||||||
year TEXT,
|
|
||||||
date TEXT,
|
|
||||||
country TEXT,
|
|
||||||
barcode TEXT
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS track;
|
|
||||||
CREATE TABLE track (
|
|
||||||
id TEXT PRIMARY KEY NOT NULL,
|
|
||||||
downloaded BOOLEAN NOT NULL DEFAULT 0,
|
|
||||||
release_id TEXT NOT NULL,
|
|
||||||
track TEXT,
|
|
||||||
length INT,
|
|
||||||
tracknumber TEXT,
|
|
||||||
isrc TEXT,
|
|
||||||
genre TEXT,
|
|
||||||
lyrics TEXT,
|
|
||||||
path TEXT,
|
|
||||||
file TEXT,
|
|
||||||
url TEXT,
|
|
||||||
src TEXT
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS source;
|
|
||||||
CREATE TABLE source (
|
|
||||||
track_id TEXT NOT NULL,
|
|
||||||
src TEXT NOT NULL,
|
|
||||||
url TEXT NOT NULL,
|
|
||||||
valid BOOLEAN NOT NULL DEFAULT 1
|
|
||||||
);
|
|
||||||
@@ -1,20 +0,0 @@
|
|||||||
[build-system]
|
|
||||||
requires = ["setuptools>=61.0", "requests~=2.28.1", "mutagen~=1.46.0", "musicbrainzngs~=0.7.1", "jellyfish~=0.9.0", "pydub~=0.25.1", "youtube_dl", "beautifulsoup4~=4.11.1", "pycountry~=22.3.5"]
|
|
||||||
build-backend = "setuptools.build_meta"
|
|
||||||
|
|
||||||
[project]
|
|
||||||
name = "music_kraken"
|
|
||||||
version = "1.2.2"
|
|
||||||
authors = [
|
|
||||||
{ name="Hellow2", email="Hellow2@outlook.de" },
|
|
||||||
]
|
|
||||||
description = "An extensive music downloader crawling the internet. It gets its metadata from a couple metadata provider, and it scrapes the audiofiles."
|
|
||||||
readme = "README.md"
|
|
||||||
requires-python = ">=3.7"
|
|
||||||
classifiers = [
|
|
||||||
"Programming Language :: Python :: 3",
|
|
||||||
"Operating System :: OS Independent",
|
|
||||||
]
|
|
||||||
|
|
||||||
[project.urls]
|
|
||||||
"Homepage" = "https://github.com/HeIIow2/music-downloader"
|
|
||||||
@@ -8,35 +8,57 @@ except ImportError:
|
|||||||
# packages=['music_kraken'],
|
# packages=['music_kraken'],
|
||||||
|
|
||||||
#packages = find_packages(where="src")
|
#packages = find_packages(where="src")
|
||||||
packages = ['music_kraken', 'music_kraken.lyrics', 'music_kraken.audio_source', 'music_kraken.target', 'music_kraken.metadata', 'music_kraken.tagging', 'music_kraken.utils', 'music_kraken.audio_source.sources', 'music_kraken.database']
|
packages = ['music_kraken', 'music_kraken.lyrics', 'music_kraken.audio_source', 'music_kraken.target', 'music_kraken.metadata', 'music_kraken.tagging', 'music_kraken.utils', 'music_kraken.audio_source.sources', 'music_kraken.database', 'music_kraken.static_files']
|
||||||
|
|
||||||
print("packages")
|
print("packages")
|
||||||
print(packages)
|
print(packages)
|
||||||
# packages.extend(["music_kraken.database"])
|
# packages.extend(["music_kraken.database"])
|
||||||
|
|
||||||
|
with open("README.md", "r") as readme_file:
|
||||||
|
long_description = readme_file.read()
|
||||||
|
|
||||||
|
install_requires = [
|
||||||
|
"requests~=2.28.1",
|
||||||
|
"mutagen~=1.46.0",
|
||||||
|
"musicbrainzngs~=0.7.1",
|
||||||
|
"jellyfish~=0.9.0",
|
||||||
|
"pydub~=0.25.1",
|
||||||
|
"youtube_dl",
|
||||||
|
"beautifulsoup4~=4.11.1",
|
||||||
|
"pycountry~=22.3.5"
|
||||||
|
]
|
||||||
|
|
||||||
|
with open("requirements.txt", "r") as requirements_txt:
|
||||||
|
install_requires = []
|
||||||
|
for requirement in requirements_txt:
|
||||||
|
requirement = requirement.strip()
|
||||||
|
install_requires.append(requirement)
|
||||||
|
print(requirement)
|
||||||
|
|
||||||
|
version = '1.2.1'
|
||||||
|
with open('version', 'r') as version_file:
|
||||||
|
version = version_file.read()
|
||||||
|
print(f"version: {version}")
|
||||||
|
|
||||||
setup(
|
setup(
|
||||||
name='music-kraken',
|
name='music-kraken',
|
||||||
version='1.0',
|
version=version,
|
||||||
description='An extensive music downloader crawling the internet. It gets its metadata from a couple metadata '
|
description='An extensive music downloader crawling the internet. It gets its metadata from a couple metadata '
|
||||||
'provider, and it scrapes the audiofiles.',
|
'provider, and it scrapes the audiofiles.',
|
||||||
|
long_description=long_description,
|
||||||
author='Hellow2',
|
author='Hellow2',
|
||||||
author_email='Hellow2@outlook.de',
|
author_email='Hellow2@outlook.de',
|
||||||
url='https://github.com/HeIIow2/music-downloader',
|
url='https://github.com/HeIIow2/music-downloader',
|
||||||
packages=packages,
|
packages=packages,
|
||||||
package_dir={'': 'src'},
|
package_dir={'': 'src', 'music_kraken': 'src/music_kraken'},
|
||||||
install_requires=[
|
install_requires=install_requires,
|
||||||
"requests~=2.28.1",
|
|
||||||
"mutagen~=1.46.0",
|
|
||||||
"musicbrainzngs~=0.7.1",
|
|
||||||
"jellyfish~=0.9.0",
|
|
||||||
"pydub~=0.25.1",
|
|
||||||
"youtube_dl",
|
|
||||||
"beautifulsoup4~=4.11.1",
|
|
||||||
"pycountry~=22.3.5"
|
|
||||||
],
|
|
||||||
entry_points={'console_scripts': ['music-kraken = music_kraken:cli']},
|
entry_points={'console_scripts': ['music-kraken = music_kraken:cli']},
|
||||||
include_package_data=False,
|
include_package_data=True,
|
||||||
|
package_data={'music_kraken': ['*.sql']},
|
||||||
data_files=[
|
data_files=[
|
||||||
('music_kraken', ['database_structure.sql'])
|
('', ['requirements.txt', 'README.md', 'version'])
|
||||||
]
|
]
|
||||||
)
|
)
|
||||||
|
|
||||||
|
# ('music_kraken', ['static_files/database_structure.sql']),
|
||||||
|
|
||||||
|
|||||||
@@ -1,15 +1,10 @@
|
|||||||
Metadata-Version: 2.1
|
Metadata-Version: 2.1
|
||||||
Name: music-kraken
|
Name: music-kraken
|
||||||
Version: 1.2.2
|
Version: 1.2.1
|
||||||
Summary: An extensive music downloader crawling the internet. It gets its metadata from a couple metadata provider, and it scrapes the audiofiles.
|
Summary: An extensive music downloader crawling the internet. It gets its metadata from a couple metadata provider, and it scrapes the audiofiles.
|
||||||
Home-page: https://github.com/HeIIow2/music-downloader
|
Home-page: https://github.com/HeIIow2/music-downloader
|
||||||
Author: Hellow2
|
Author: Hellow2
|
||||||
Author-email: Hellow2 <Hellow2@outlook.de>
|
Author-email: Hellow2@outlook.de
|
||||||
Project-URL: Homepage, https://github.com/HeIIow2/music-downloader
|
|
||||||
Classifier: Programming Language :: Python :: 3
|
|
||||||
Classifier: Operating System :: OS Independent
|
|
||||||
Requires-Python: >=3.7
|
|
||||||
Description-Content-Type: text/markdown
|
|
||||||
License-File: LICENSE
|
License-File: LICENSE
|
||||||
|
|
||||||
# Music Kraken
|
# Music Kraken
|
||||||
|
|||||||
@@ -1,8 +1,9 @@
|
|||||||
LICENSE
|
LICENSE
|
||||||
README.md
|
README.md
|
||||||
database_structure.sql
|
requirements.txt
|
||||||
pyproject.toml
|
|
||||||
setup.py
|
setup.py
|
||||||
|
version
|
||||||
|
assets/database_structure.sql
|
||||||
assets/temp_database_structure.sql
|
assets/temp_database_structure.sql
|
||||||
src/music_kraken/__init__.py
|
src/music_kraken/__init__.py
|
||||||
src/music_kraken/__main__.py
|
src/music_kraken/__main__.py
|
||||||
|
|||||||
@@ -19,14 +19,7 @@ from .utils.shared import (
|
|||||||
|
|
||||||
from .lyrics import lyrics
|
from .lyrics import lyrics
|
||||||
|
|
||||||
"""
|
|
||||||
# try reading a static file:
|
|
||||||
print("TEST")
|
|
||||||
import pkgutil
|
|
||||||
|
|
||||||
data = pkgutil.get_data(__name__, "temp_database_structure.sql")
|
|
||||||
print(data)
|
|
||||||
"""
|
|
||||||
"""
|
"""
|
||||||
At the start I modify the garbage collector to run a bit fewer times.
|
At the start I modify the garbage collector to run a bit fewer times.
|
||||||
This should increase speed:
|
This should increase speed:
|
||||||
@@ -74,6 +67,9 @@ def fetch_audios(songs: List[Song], override_existing: bool = False):
|
|||||||
audio_source.fetch_audios(songs=songs, override_existing=override_existing)
|
audio_source.fetch_audios(songs=songs, override_existing=override_existing)
|
||||||
|
|
||||||
|
|
||||||
|
def clear_cache():
|
||||||
|
cache.init_db(reset_anyways=True)
|
||||||
|
|
||||||
def get_existing_genre():
|
def get_existing_genre():
|
||||||
valid_directories = []
|
valid_directories = []
|
||||||
for elem in os.listdir(MUSIC_DIR):
|
for elem in os.listdir(MUSIC_DIR):
|
||||||
|
|||||||
@@ -4,6 +4,7 @@ import os
|
|||||||
import logging
|
import logging
|
||||||
import json
|
import json
|
||||||
import requests
|
import requests
|
||||||
|
from pkg_resources import resource_string
|
||||||
|
|
||||||
from . import song
|
from . import song
|
||||||
from ..utils.shared import (
|
from ..utils.shared import (
|
||||||
@@ -13,17 +14,16 @@ from ..utils.shared import (
|
|||||||
logger = DATABASE_LOGGER
|
logger = DATABASE_LOGGER
|
||||||
|
|
||||||
class Database:
|
class Database:
|
||||||
def __init__(self, path_to_db: str, db_structure: str, db_structure_fallback: str, reset_anyways: bool = False):
|
def __init__(self, path_to_db: str, reset_anyways: bool = False):
|
||||||
self.path_to_db = path_to_db
|
self.path_to_db = path_to_db
|
||||||
|
|
||||||
self.connection = sqlite3.connect(self.path_to_db)
|
self.connection = sqlite3.connect(self.path_to_db)
|
||||||
self.cursor = self.connection.cursor()
|
self.cursor = self.connection.cursor()
|
||||||
|
|
||||||
# init database
|
# init database
|
||||||
self.init_db(database_structure=db_structure, database_structure_fallback=db_structure_fallback,
|
self.init_db(reset_anyways=reset_anyways)
|
||||||
reset_anyways=reset_anyways)
|
|
||||||
|
|
||||||
def init_db(self, database_structure: str, database_structure_fallback: str, reset_anyways: bool = False):
|
def init_db(self, reset_anyways: bool = False):
|
||||||
# check if db exists
|
# check if db exists
|
||||||
exists = True
|
exists = True
|
||||||
try:
|
try:
|
||||||
@@ -38,20 +38,11 @@ class Database:
|
|||||||
|
|
||||||
if reset_anyways or not exists:
|
if reset_anyways or not exists:
|
||||||
# reset the database if reset_anyways is true or if an error has been thrown previously.
|
# reset the database if reset_anyways is true or if an error has been thrown previously.
|
||||||
logger.info("Creating/Reseting Database.")
|
logger.info(f"Reseting the database.")
|
||||||
|
|
||||||
if not os.path.exists(database_structure):
|
query = resource_string("music_kraken", "static_files/temp_database_structure.sql").decode('utf-8')
|
||||||
logger.info("database structure file doesn't exist yet, fetching from github")
|
self.cursor.executescript(query)
|
||||||
r = requests.get(database_structure_fallback)
|
self.connection.commit()
|
||||||
|
|
||||||
with open(database_structure, "w") as f:
|
|
||||||
f.write(r.text)
|
|
||||||
|
|
||||||
# read the file
|
|
||||||
with open(database_structure, "r") as database_structure_file:
|
|
||||||
query = database_structure_file.read()
|
|
||||||
self.cursor.executescript(query)
|
|
||||||
self.connection.commit()
|
|
||||||
|
|
||||||
def add_artist(
|
def add_artist(
|
||||||
self,
|
self,
|
||||||
|
|||||||
@@ -2,8 +2,6 @@ from .database import Database
|
|||||||
|
|
||||||
from ..utils.shared import (
|
from ..utils.shared import (
|
||||||
TEMP_DATABASE_PATH,
|
TEMP_DATABASE_PATH,
|
||||||
DATABASE_STRUCTURE_FILE,
|
|
||||||
DATABASE_STRUCTURE_FALLBACK,
|
|
||||||
DATABASE_LOGGER
|
DATABASE_LOGGER
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -12,7 +10,7 @@ logger = DATABASE_LOGGER
|
|||||||
|
|
||||||
class TempDatabase(Database):
|
class TempDatabase(Database):
|
||||||
def __init__(self) -> None:
|
def __init__(self) -> None:
|
||||||
super().__init__(TEMP_DATABASE_PATH, DATABASE_STRUCTURE_FILE, DATABASE_STRUCTURE_FALLBACK, False)
|
super().__init__(TEMP_DATABASE_PATH, False)
|
||||||
|
|
||||||
|
|
||||||
temp_database = TempDatabase()
|
temp_database = TempDatabase()
|
||||||
|
|||||||
@@ -1,66 +0,0 @@
|
|||||||
DROP TABLE IF EXISTS artist;
|
|
||||||
CREATE TABLE artist (
|
|
||||||
id TEXT PRIMARY KEY NOT NULL,
|
|
||||||
name TEXT
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS artist_release_group;
|
|
||||||
CREATE TABLE artist_release_group (
|
|
||||||
artist_id TEXT NOT NULL,
|
|
||||||
release_group_id TEXT NOT NULL
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS artist_track;
|
|
||||||
CREATE TABLE artist_track (
|
|
||||||
artist_id TEXT NOT NULL,
|
|
||||||
track_id TEXT NOT NULL
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS release_group;
|
|
||||||
CREATE TABLE release_group (
|
|
||||||
id TEXT PRIMARY KEY NOT NULL,
|
|
||||||
albumartist TEXT,
|
|
||||||
albumsort INT,
|
|
||||||
musicbrainz_albumtype TEXT,
|
|
||||||
compilation TEXT,
|
|
||||||
album_artist_id TEXT
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS release_;
|
|
||||||
CREATE TABLE release_ (
|
|
||||||
id TEXT PRIMARY KEY NOT NULL,
|
|
||||||
release_group_id TEXT NOT NULL,
|
|
||||||
title TEXT,
|
|
||||||
copyright TEXT,
|
|
||||||
album_status TEXT,
|
|
||||||
language TEXT,
|
|
||||||
year TEXT,
|
|
||||||
date TEXT,
|
|
||||||
country TEXT,
|
|
||||||
barcode TEXT
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS track;
|
|
||||||
CREATE TABLE track (
|
|
||||||
id TEXT PRIMARY KEY NOT NULL,
|
|
||||||
downloaded BOOLEAN NOT NULL DEFAULT 0,
|
|
||||||
release_id TEXT NOT NULL,
|
|
||||||
track TEXT,
|
|
||||||
length INT,
|
|
||||||
tracknumber TEXT,
|
|
||||||
isrc TEXT,
|
|
||||||
genre TEXT,
|
|
||||||
lyrics TEXT,
|
|
||||||
path TEXT,
|
|
||||||
file TEXT,
|
|
||||||
url TEXT,
|
|
||||||
src TEXT
|
|
||||||
);
|
|
||||||
|
|
||||||
DROP TABLE IF EXISTS source;
|
|
||||||
CREATE TABLE source (
|
|
||||||
track_id TEXT NOT NULL,
|
|
||||||
src TEXT NOT NULL,
|
|
||||||
url TEXT NOT NULL,
|
|
||||||
valid BOOLEAN NOT NULL DEFAULT 1
|
|
||||||
);
|
|
||||||
@@ -1,182 +0,0 @@
|
|||||||
Metadata-Version: 2.1
|
|
||||||
Name: music-kraken
|
|
||||||
Version: 0.0.4
|
|
||||||
Summary: An extensive music downloader crawling the internet. It gets its metadata from a couple metadata provider, and it scrapes the audiofiles.
|
|
||||||
Home-page: https://github.com/HeIIow2/music-downloader
|
|
||||||
Author: Hellow2
|
|
||||||
Author-email: Hellow2 <Hellow2@outlook.de>
|
|
||||||
Project-URL: Homepage, https://github.com/HeIIow2/music-downloader
|
|
||||||
Classifier: Programming Language :: Python :: 3
|
|
||||||
Classifier: Operating System :: OS Independent
|
|
||||||
Requires-Python: >=3.7
|
|
||||||
Description-Content-Type: text/markdown
|
|
||||||
License-File: LICENSE
|
|
||||||
|
|
||||||
# Music Kraken
|
|
||||||
|
|
||||||
RUN WITH: `python3 -m src` from the project Directory
|
|
||||||
|
|
||||||
This program will first get the metadata of various songs from metadata provider like musicbrainz, and then search for download links on pages like bandcamp. Then it will download the song and edit the metadata according.
|
|
||||||
|
|
||||||
## Metadata
|
|
||||||
|
|
||||||
First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz](musicbrainz.org/). This is a result of them being a website with a large Database spanning over all Genres.
|
|
||||||
|
|
||||||
### Musicbrainz
|
|
||||||
|
|
||||||
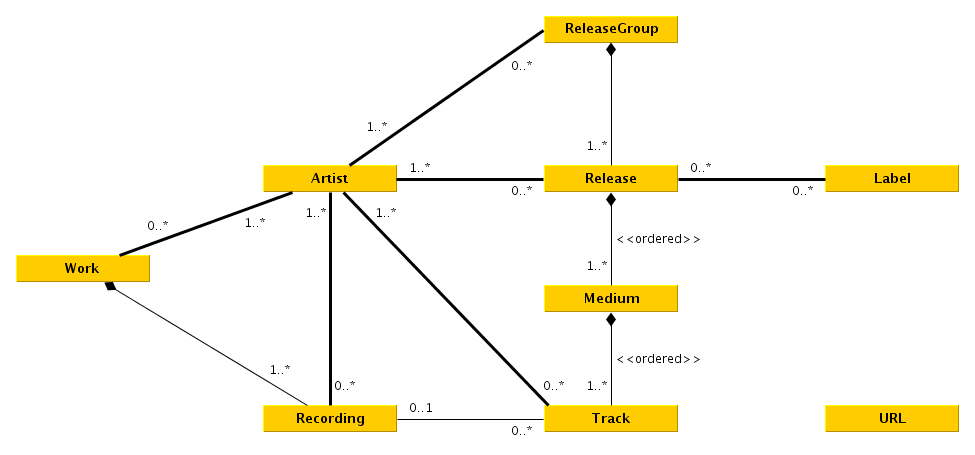
|
|
||||||
|
|
||||||
To fetch from [Musicbrainz](musicbrainz.org/) we first have to know what to fetch. A good start is to get an input query, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
|
|
||||||
|
|
||||||
Then we can output them in the Terminal and ask for further input. Following can be inputted afterwards:
|
|
||||||
|
|
||||||
- `q` to quit
|
|
||||||
- `ok` to download
|
|
||||||
- `..` for previous options
|
|
||||||
- `.` for current options
|
|
||||||
- `an integer` for this element
|
|
||||||
|
|
||||||
If the following chosen element is an artist, its discography + a couple tracks are outputted, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
|
|
||||||
|
|
||||||
**TO DO**
|
|
||||||
|
|
||||||
- Show always the whole tracklist of an release if it is chosen
|
|
||||||
- Show always the whole discography of an artist if it is chosen
|
|
||||||
|
|
||||||
Up to now it doesn't if the discography or tracklist is chosen.
|
|
||||||
|
|
||||||
### Metadata to fetch
|
|
||||||
|
|
||||||
I orient on which metadata to download on the keys in `mutagen.EasyID3` . Following I fetch and thus tag the MP3 with:
|
|
||||||
- title
|
|
||||||
- artist
|
|
||||||
- albumartist
|
|
||||||
- tracknumber
|
|
||||||
- albumsort can sort albums cronological
|
|
||||||
- titlesort is just set to the tracknumber to sort by track order to sort correctly
|
|
||||||
- isrc
|
|
||||||
- musicbrainz_artistid
|
|
||||||
- musicbrainz_albumid
|
|
||||||
- musicbrainz_albumartistid
|
|
||||||
- musicbrainz_albumstatus
|
|
||||||
- language
|
|
||||||
- musicbrainz_albumtype
|
|
||||||
- releasecountry
|
|
||||||
- barcode
|
|
||||||
|
|
||||||
#### albumsort/titlesort
|
|
||||||
|
|
||||||
Those Tags are for the musicplayer to not sort for Example the albums of a band alphabetically, but in another way. I set it just to chronological order
|
|
||||||
|
|
||||||
#### isrc
|
|
||||||
|
|
||||||
This is the **international standard release code**. With this a track can be identified 100% precisely all of the time, if it is known and the website has a search api for that. Obviously this will get important later.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## Download
|
|
||||||
|
|
||||||
Now that the metadata is downloaded and cached, download sources need to be sound, because one can't listen to metadata. Granted it would be amazing if that would be possible.
|
|
||||||
|
|
||||||
### Musify
|
|
||||||
|
|
||||||
The quickest source to get download links from is to my knowledge [musify](https://musify.club/). Its a russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search stuff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottleneck definitely is not at the speed of those requests.
|
|
||||||
|
|
||||||
For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
|
|
||||||
|
|
||||||
```json
|
|
||||||
[
|
|
||||||
{
|
|
||||||
"id":"Lorna Shore",
|
|
||||||
"label":"Lorna Shore",
|
|
||||||
"value":"Lorna Shore",
|
|
||||||
"category":"Исполнители",
|
|
||||||
"image":"https://39s.musify.club/img/68/9561484/25159224.jpg",
|
|
||||||
"url":"/artist/lorna-shore-59611"
|
|
||||||
},
|
|
||||||
{"id":"Immortal","label":"Lorna Shore - Immortal (2020)","value":"Immortal","category":"Релизы","image":"https://39s-a.musify.club/img/70/20335517/52174338.jpg","url":"/release/lorna-shore-immortal-2020-1241300"},
|
|
||||||
{"id":"Immortal","label":"Lorna Shore - Immortal","value":"Immortal","category":"Треки","image":"","url":"/track/lorna-shore-immortal-12475071"}
|
|
||||||
]
|
|
||||||
```
|
|
||||||
|
|
||||||
This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
|
|
||||||
|
|
||||||
- call the api with the query being the track name
|
|
||||||
- parse the json response to an object
|
|
||||||
- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
|
|
||||||
- If they match get the download links and cache them.
|
|
||||||
|
|
||||||
### Youtube
|
|
||||||
|
|
||||||
Here the **isrc** plays a huge role. You probably know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
|
|
||||||
|
|
||||||
Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
|
|
||||||
|
|
||||||
For searching, as well as for downloading I use the program `youtube-dl`, which also has a programming interface for python.
|
|
||||||
|
|
||||||
There are two bottlenecks with this approach though:
|
|
||||||
1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
|
|
||||||
2. Often musicbrainz just doesn't give the isrc for some songs.
|
|
||||||
|
|
||||||
**TODO**
|
|
||||||
- look at how the isrc id derived an try to generate it for the tracks without directly getting it from mb.
|
|
||||||
|
|
||||||
|
|
||||||
**Progress**
|
|
||||||
- There is a great site with a huge isrc database [https://isrc.soundexchange.com/](https://isrc.soundexchange.com/).
|
|
||||||
|
|
||||||
|
|
||||||
## Lyrics
|
|
||||||
|
|
||||||
To get the Lyrics, I scrape them, and put those in the USLT ID3 Tags of for example mp3 files. Unfortunately some players, like the one I use, Rhythmbox don't support USLT Lyrics. So I created an Plugin for Rhythmbox. You can find it here: [https://github.com/HeIIow2/rythmbox-id3-lyrics-support](https://github.com/HeIIow2/rythmbox-id3-lyrics-support).
|
|
||||||
|
|
||||||
### Genius
|
|
||||||
|
|
||||||
For the lyrics source the page [https://genius.com/](https://genius.com/) is easily sufficient. It has most songs. Some songs are not present though, but that is fine, because the lyrics are optional anyways.
|
|
||||||
|
|
||||||
## Project overview
|
|
||||||
|
|
||||||
The file structure is as follows (might be slightly outdated):
|
|
||||||
|
|
||||||
```
|
|
||||||
music-downloader
|
|
||||||
├── assets
|
|
||||||
│ └── database_structure.sql
|
|
||||||
├── LICENSE
|
|
||||||
├── notes.md
|
|
||||||
├── README.md
|
|
||||||
├── requirements.txt
|
|
||||||
└── src
|
|
||||||
├── audio
|
|
||||||
│ └── song.py
|
|
||||||
├── download_links.py
|
|
||||||
├── download.py
|
|
||||||
├── lyrics
|
|
||||||
│ ├── genius.py
|
|
||||||
│ └── lyrics.py
|
|
||||||
├── __main__.py
|
|
||||||
├── metadata
|
|
||||||
│ ├── database.py
|
|
||||||
│ ├── download.py
|
|
||||||
│ ├── object_handling.py
|
|
||||||
│ └── search.py
|
|
||||||
├── scraping
|
|
||||||
│ ├── file_system.py
|
|
||||||
│ ├── musify.py
|
|
||||||
│ ├── phonetic_compares.py
|
|
||||||
│ └── youtube_music.py
|
|
||||||
├── url_to_path.py
|
|
||||||
└── utils
|
|
||||||
├── object_handling.py
|
|
||||||
├── phonetic_compares.py
|
|
||||||
└── shared.py
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
You can obviously find the source code in the folder src. The two "most important" files are `__main__.py` and `utils/shared.py`.
|
|
||||||
|
|
||||||
In the first one is the code gluing everything together and providing the cli.
|
|
||||||
|
|
||||||
### utils
|
|
||||||
|
|
||||||
The constants like the global database object can be found in `shared.py`.
|
|
||||||
@@ -1,32 +0,0 @@
|
|||||||
README.md
|
|
||||||
pyproject.toml
|
|
||||||
setup.py
|
|
||||||
music_kraken/__init__.py
|
|
||||||
music_kraken/__main__.py
|
|
||||||
music_kraken/download.py
|
|
||||||
music_kraken/download_links.py
|
|
||||||
music_kraken/url_to_path.py
|
|
||||||
music_kraken/audio/__init__.py
|
|
||||||
music_kraken/audio/song.py
|
|
||||||
music_kraken/lyrics/__init__.py
|
|
||||||
music_kraken/lyrics/genius.py
|
|
||||||
music_kraken/lyrics/lyrics.py
|
|
||||||
music_kraken/metadata/__init__.py
|
|
||||||
music_kraken/metadata/database.py
|
|
||||||
music_kraken/metadata/download.py
|
|
||||||
music_kraken/metadata/object_handeling.py
|
|
||||||
music_kraken/metadata/search.py
|
|
||||||
music_kraken/music_kraken.egg-info/PKG-INFO
|
|
||||||
music_kraken/music_kraken.egg-info/SOURCES.txt
|
|
||||||
music_kraken/music_kraken.egg-info/dependency_links.txt
|
|
||||||
music_kraken/music_kraken.egg-info/requires.txt
|
|
||||||
music_kraken/music_kraken.egg-info/top_level.txt
|
|
||||||
music_kraken/scraping/__init__.py
|
|
||||||
music_kraken/scraping/file_system.py
|
|
||||||
music_kraken/scraping/musify.py
|
|
||||||
music_kraken/scraping/phonetic_compares.py
|
|
||||||
music_kraken/scraping/youtube_music.py
|
|
||||||
music_kraken/utils/__init__.py
|
|
||||||
music_kraken/utils/object_handeling.py
|
|
||||||
music_kraken/utils/phonetic_compares.py
|
|
||||||
music_kraken/utils/shared.py
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
|
|
||||||
@@ -1,8 +0,0 @@
|
|||||||
requests~=2.28.1
|
|
||||||
mutagen~=1.46.0
|
|
||||||
musicbrainzngs~=0.7.1
|
|
||||||
jellyfish~=0.9.0
|
|
||||||
pydub~=0.25.1
|
|
||||||
youtube_dl
|
|
||||||
beautifulsoup4~=4.11.1
|
|
||||||
pycountry~=22.3.5
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
music_kraken
|
|
||||||
Reference in New Issue
Block a user