-
+
-
+
+ ++ +
 +
+ + Your best friend +
+ +
+
+ -
+
+ ++ +
 +
+ + Few words... +
+ +
+
+
-Gets all indexing values with
music_object.indexing_values.
-If any returned value exists in Collection._attribute_to_object_map,
-the music_object exists
- """)
-
- subgraph merge["Merging"]
-
- _merge("""merges the passed in object in the already
- existing whith existing.merge(new)""")
-
- _map("""In case a new source or something simmilar
- has been addet, it maps the existing object again.
- """)
-
- _merge --> _map
-
- end
-
- subgraph add["Adding"]
-
- __map("""map the values from music_object.indexing_values
- to Collection._attribute_to_object_map by writing
- those values in the map as keys, and the class I wanna add as values.
- """)
-
- _add("""add the new music object to _data""")
-
- __map --> _add
-
- end
-
- exist-->|"if it doesn't exist"|add --> return
- exist-->|"if already exists"|merge --> return
-```
-
-This is Implemented in [music_kraken.objects.Collection.append()](src/music_kraken/objects/collection.py).
-
-The indexing values are defined in the superclass [DatabaseObject](src/music_kraken/objects/parents.py) and get implemented for each Object seperately. I will just give as example its implementation for the `Song` class:
-
-```python
-@property
-def indexing_values(self) -> List[Tuple[str, object]]:
- return [
- ('id', self.id),
- ('title', self.unified_title),
- ('barcode', self.barcode),
- *[('url', source.url) for source in self.source_collection]
- ]
-```
-
-## Classes and Objects
-
-### music_kraken.objects
-
-#### Collection
-
-#### Song
-
-So as you can see, the probably most important Class is the `music_kraken.Song` class. It is used to save the song in *(duh)*.
-
-It has handful attributes, where half of em are self-explanatory, like `title` or `genre`. The ones like `isrc` are only relevant to you, if you know what it is, so I won't elaborate on it.
-
-Interesting is the `date`. It uses a custom class. More on that [here](#music_krakenid3timestamp).
-
-#### ID3Timestamp
-
-For multiple Reasons I don't use the default `datetime.datetime` class.
-
-The most important reason is, that you need to pass in at least year, month and day. For every other values there are default values, that are indistinguishable from values that are directly passed in. But I need optional values. The ID3 standart allows default values. Additionally `datetime.datetime` is immutable, thus I can't inherint all the methods. Sorry.
-
-Anyway you can create those custom objects easily.
-
-```python
-from music_kraken import ID3Timestamp
-
-# returns an instance of ID3Timestamp with the current time
-ID3Timestamp.now()
-
-# yea
-ID3Timestamp(year=1986, month=3, day=1)
-```
-
-you can pass in the Arguments:
- - year
- - month
- - day
- - hour
- - minute
- - second
-
-:)
-
-# Old implementation
-
-> IF U USE THIS NOW YOU ARE DUMB *no offense thoug*. IT ISN'T FINISHED AND THE STUFF YOU CODE NOW WILL BE BROKEN TOMORROW
-> SOON YOU CAN THOUGH
-
-If you want to use this project, or parts from it in your own projects from it,
-make sure to be familiar with [Python Modules](https://docs.python.org/3/tutorial/modules.html).
-Further and better documentation including code examples are yet to come, so here is the rough
-module structure for now. (Should be up-to-date, but no guarantees)
-
-If you simply want to run the builtin minimal cli just do this:
-```python
-from music_kraken import cli
-
-cli()
-```
-
-### Search for Metadata
-
-The whole program takes the data it processes further from the cache, a sqlite database.
-So before you can do anything, you will need to fill it with the songs you want to download (*or create song objects manually, but more on that later*).
-
-For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type`. The `id` corresponds to either
- - an artist
- - a release group
- - a release
- - a recording/track).
-
-To get this info, you first have to initialize a search object (`music_kraken.MetadataSearch`).
-
-```python
-search_object = music_kraken.MetadataSearch()
-```
-
-Then you need an initial "text search" to get some options you can choose from. For
-this you can either specify artists releases and whatever directly with one of the following functions:
-
-```python
-# you can directly specify artist, release group, release or recording/track
-multiple_options = search_object.search_from_text(artist=input("input the name of the artist: "))
-# you can specify a query see the simple integrated cli on how to use the query
-multiple_options = search_object.search_from_query(query=input("input the query: "))
-```
-
-Both methods return an instance of `MultipleOptions`, which can be directly converted to a string.
-
-```python
-print(multiple_options)
-```
-
-After the first "*text search*" you can either again search the same way as before,
-or you can further explore one of the options from the previous search.
-To explore and select one options from `MultipleOptions`, simply call `MetadataSearch.choose(self, index: int)`.
-The index represents the number in the previously returned instance of MultipleOptions.
-The selected Option will be selected and can be downloaded in the next step.
-
-*Thus, this has to be done **after either search_from_text or search_from_query***
-
-```python
-# choosing the best matching band
-multiple_options = search_object.choose(0)
-# choosing the first ever release group of this band
-multiple_options = search_object.choose(1)
-# printing out the current options
-print(multiple_options)
-```
-
-This process can be repeated indefinitely (until you run out of memory).
-A search history is kept in the Search instance. You could go back to
-the previous search (without any loading time) like this:
-
-```python
-multiple_options = search_object.get_previous_options()
-```
-
-### Downloading Metadata / Filling up the Cache
-
-You can download following metadata:
- - an artist (the whole discography)
- - a release group
- - a release
- - a track/recording
-
-If you got an instance of `MetadataSearch`, like I elaborated [previously](#search-for-metadata), downloading every piece of metadata from the currently selected Option is really quite easy.
-
-```python
-from music_kraken import fetch_metadata_from_search
-
-# this is it :)
-music_kraken.fetch_metadata_from_search(search_object)
-```
-
-If you already know what you want to download you can skip the search instance and simply do the following.
-
-```python
-from music_kraken import fetch_metadata
-
-# might change and break after I add multiple metadata sources which I will
-
-fetch_metadata(id_=musicbrainz_id, type=metadata_type)
-```
-The option type is a string (*I'm sorry for not making it an enum I know its a bad pratice*), which can
-have following values:
- - 'artist'
- - 'release_group'
- - 'release'
- - 'recording'
-
-**PAY ATTENTION TO TYPOS, IT'S CASE SENSITIVE**
-
-The musicbrainz id is just the id of the object from musicbrainz.
-
-After following those steps, it might take a couple seconds/minutes to execute, but then the Cache will be filled.
-
-
-### Cache / Temporary Database
-
-All the data, the functions that download stuff use, can be gotten from the temporary database / cache.
-The cache can be simply used like this:
-
-```python
-music_kraken.test_db
-```
-
-When fetching any song data from the cache, you will get it as Song
-object (music_kraken.Song). There are multiple methods
-to get different sets of Songs. The names explain the methods pretty
-well:
-
-```python
-from music_kraken import cache
-
-# gets a single track specified by the id
-cache.get_track_metadata(id: str)
-
-# gets a list of tracks.
-cache.get_tracks_to_download()
-cache.get_tracks_without_src()
-cache.get_tracks_without_isrc()
-cache.get_tracks_without_filepath()
-```
-
-The id always is a musicbrainz id and distinct for every track.
-
-### Setting the Target
-
-By default the music downloader doesn't know where to save the music file, if downloaded. To set those variables (the directory to save the file in and the filepath), it is enough to run one single command:
-
-```python
-from music_kraken import set_target
-
-# adds file path, file directory and the genre to the database
-set_target(genre="some test genre")
-```
-
-The concept of genres is too loose, to definitely say, this band exclusively plays this genre, or this song is this genre. This doesn't work manually, this will never work automatically. Thus, I've decided to just use the genre as category, to sort the artists and songs by. Most Music players support that.
-
-As a result of this decision you will have to pass the genre in this function.
-
-### Get Audio
-
-This is most likely the most useful and unique feature of this Project. If the cache is filled, you can get audio sources for the songs you only have the metadata, and download them. This works for most songs. I'd guess for about 97% (?)
-
-First of you will need a List of song objects `music_kraken.Song`. As [mentioned above](#cache--temporary-database), you could get a list like that from the cache.
-
-```python
-# Here is an Example
-from music_kraken import (
- cache,
- fetch_sources,
- fetch_audios
-)
-
-# scanning pages, searching for a download and storing results
-fetch_sources(cache.get_tracks_without_src())
-
-# downloading all previously fetched sources to previously defined targets
-fetch_audios(cache.get_tracks_to_download())
-
-```
-
-*Note:*
-To download audio two cases have to be met:
- 1. [The target](#setting-the-target) has to be set beforehand
- 2. The sources have to be fetched beforehand
-
----
-
-## Metadata
-
-First the metadata has to be downloaded. The best api to do so is undeniably [Musicbrainz][mb]. This is a result of them being a website with a large Database spanning over all Genres.
-
-### Musicbrainz
-
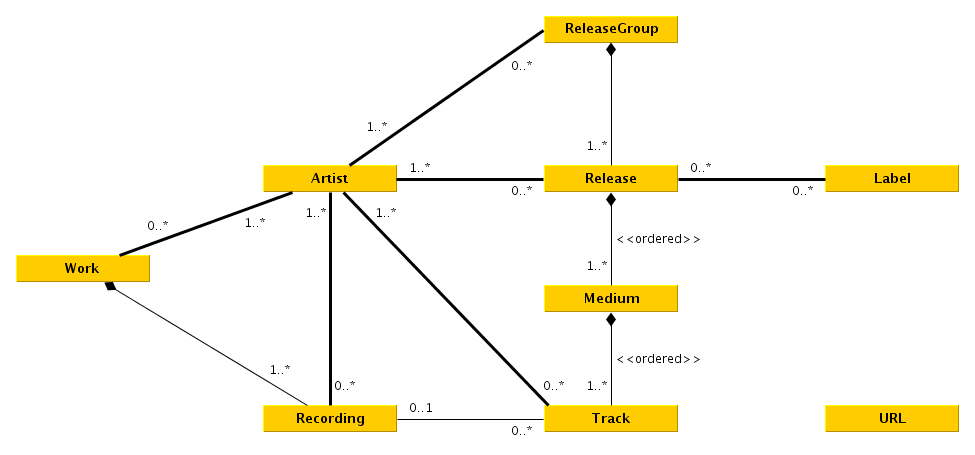
-
-
-To fetch from [Musicbrainz][mb] we first have to know what to fetch. A good start is to get an input query, which can be just put into the MB-Api. It then returns a list of possible artists, releases and recordings.
-
-If the following chosen element is an artist, its discography + a couple tracks are printed, if a release is chosen, the artists + tracklist + release is outputted, If a track is chosen its artists and releases are shown.
-
-For now, it doesn't if the discography or tracklist is chosen.
-
-### Metadata to fetch
-
-I orient on which metadata to download on the keys in `mutagen.EasyID3`. The following I fetch and tag the MP3 with:
-- title
-- artist
-- albumartist
-- tracknumber
-- albumsort can sort albums cronological
-- titlesort is just set to the tracknumber to sort by track order to sort correctly
-- isrc
-- musicbrainz_artistid
-- musicbrainz_albumid
-- musicbrainz_albumartistid
-- musicbrainz_albumstatus
-- language
-- musicbrainz_albumtype
-- releasecountry
-- barcode
-
-#### albumsort/titlesort
-
-Those Tags are for the musicplayer to not sort for Example the albums of a band alphabetically, but in another way. I set it just to chronological order
-
-#### isrc
-
-This is the **international standart release code**. With this a track can be identified 99% of the time, if it is known and the website has a search api for that. Obviously this will get important later.
-
-## Download
-
-Now that the metadata is downloaded and cached, download sources need to be sound, because one can't listen to metadata. Granted it would be amazing if that would be possible.
-
-### Musify
-
-The quickest source to get download links from is to my knowledge [musify](https://musify.club/). It's a Russian music downloading page, where many many songs are available to stream and to download. Due to me not wanting to stress the server to much, I abuse a handy feature nearly every page where you can search suff has. The autocomplete api for the search input. Those always are quite limited in the number of results it returns, but it is optimized to be quick. Thus with the http header `Connection` set to `keep-alive` the bottleneck definitely is not at the speed of those requests.
-
-For musify the endpoint is following: [https://musify.club/search/suggestions?term={title}](https://musify.club/search/suggestions?term=LornaShore) If the http headers are set correctly, then searching for example for "Lorna Shore" yields following result:
-
-```json
-[
- {
- "id":"Lorna Shore",
- "label":"Lorna Shore",
- "value":"Lorna Shore",
- "category":"Исполнители",
- "image":"https://39s.musify.club/img/68/9561484/25159224.jpg",
- "url":"/artist/lorna-shore-59611"
- },
- {"id":"Immortal","label":"Lorna Shore - Immortal (2020)","value":"Immortal","category":"Релизы","image":"https://39s-a.musify.club/img/70/20335517/52174338.jpg","url":"/release/lorna-shore-immortal-2020-1241300"},
- {"id":"Immortal","label":"Lorna Shore - Immortal","value":"Immortal","category":"Треки","image":"","url":"/track/lorna-shore-immortal-12475071"}
-]
-```
-
-This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
-
-- call the api with the query being the track name
-- parse the json response to an object
-- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
-- If they match get the download links and cache them.
-
-### Youtube
-
-Herte the **isrc** plays a huge role. You probably know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
-
-Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
-
-For searching, as well as for downloading I use the programm `youtube-dl`, which also has a programming interface for python.
-
-There are two bottlenecks with this approach though:
-1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
-2. Ofthen musicbrainz just doesn't give the isrc for some songs.
-
-
-## Lyrics
-
-To get the Lyrics, I scrape them, and put those in the USLT ID3 Tags of for example mp3 files. Unfortunately some players, like the one I use, Rhythmbox don't support USLT Lyrics. So I created an Plugin for Rhythmbox. You can find it here: [https://github.com/HeIIow2/rythmbox-id3-lyrics-support](https://github.com/HeIIow2/rythmbox-id3-lyrics-support).
-
-### Genius
-
-For the lyrics source the page [https://genius.com/](https://genius.com/) is easily sufficient. It has most songs. Some songs are not present though, but that is fine, because the lyrics are optional anyways.
-
-
-[i10]: https://github.com/HeIIow2/music-downloader/issues/10
-[i2]: https://github.com/HeIIow2/music-downloader/issues/2
-[mb]: https://musicbrainz.org/
-
-
diff --git a/src/music_kraken.egg-info/SOURCES.txt b/src/music_kraken.egg-info/SOURCES.txt
deleted file mode 100644
index e0f3960..0000000
--- a/src/music_kraken.egg-info/SOURCES.txt
+++ /dev/null
@@ -1,46 +0,0 @@
-LICENSE
-README.md
-pyproject.toml
-requirements.txt
-setup.py
-version
-assets/database_structure.sql
-assets/temp_database_structure.sql
-src/music_kraken/__init__.py
-src/music_kraken/__main__.py
-src/music_kraken.egg-info/PKG-INFO
-src/music_kraken.egg-info/SOURCES.txt
-src/music_kraken.egg-info/dependency_links.txt
-src/music_kraken.egg-info/entry_points.txt
-src/music_kraken.egg-info/requires.txt
-src/music_kraken.egg-info/top_level.txt
-src/music_kraken/database/__init__.py
-src/music_kraken/database/data_models.py
-src/music_kraken/database/database.py
-src/music_kraken/database/object_cache.py
-src/music_kraken/database/old_database.py
-src/music_kraken/database/read.py
-src/music_kraken/database/temp_database.py
-src/music_kraken/database/write.py
-src/music_kraken/lyrics/__init__.py
-src/music_kraken/metadata/__init__.py
-src/music_kraken/not_used_anymore/__init__.py
-src/music_kraken/not_used_anymore/fetch_audio.py
-src/music_kraken/not_used_anymore/fetch_source.py
-src/music_kraken/not_used_anymore/sources/__init__.py
-src/music_kraken/not_used_anymore/sources/genius.py
-src/music_kraken/not_used_anymore/sources/local_files.py
-src/music_kraken/not_used_anymore/sources/musify.py
-src/music_kraken/not_used_anymore/sources/source.py
-src/music_kraken/not_used_anymore/sources/youtube.py
-src/music_kraken/static_files/temp_database_structure.sql
-src/music_kraken/tagging/__init__.py
-src/music_kraken/tagging/id3.py
-src/music_kraken/target/__init__.py
-src/music_kraken/target/set_target.py
-src/music_kraken/utils/__init__.py
-src/music_kraken/utils/functions.py
-src/music_kraken/utils/object_handeling.py
-src/music_kraken/utils/phonetic_compares.py
-src/music_kraken/utils/shared.py
-src/music_kraken/utils/string_processing.py
\ No newline at end of file
diff --git a/src/music_kraken.egg-info/dependency_links.txt b/src/music_kraken.egg-info/dependency_links.txt
deleted file mode 100644
index 8b13789..0000000
--- a/src/music_kraken.egg-info/dependency_links.txt
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/src/music_kraken.egg-info/entry_points.txt b/src/music_kraken.egg-info/entry_points.txt
deleted file mode 100644
index 6d8a32d..0000000
--- a/src/music_kraken.egg-info/entry_points.txt
+++ /dev/null
@@ -1,3 +0,0 @@
-[console_scripts]
-music-kraken = music_kraken:cli
-
diff --git a/src/music_kraken.egg-info/requires.txt b/src/music_kraken.egg-info/requires.txt
deleted file mode 100644
index ffbd9a1..0000000
--- a/src/music_kraken.egg-info/requires.txt
+++ /dev/null
@@ -1,12 +0,0 @@
-requests~=2.28.1
-mutagen~=1.46.0
-musicbrainzngs~=0.7.1
-jellyfish~=0.9.0
-pydub~=0.25.1
-youtube_dl
-beautifulsoup4~=4.11.1
-pycountry~=22.3.5
-python-dateutil~=2.8.2
-pandoc~=2.3
-SQLAlchemy
-setuptools~=60.2.0
diff --git a/src/music_kraken.egg-info/top_level.txt b/src/music_kraken.egg-info/top_level.txt
deleted file mode 100644
index 3f22a76..0000000
--- a/src/music_kraken.egg-info/top_level.txt
+++ /dev/null
@@ -1 +0,0 @@
-music_kraken
diff --git a/src/music_kraken/__init__.py b/src/music_kraken/__init__.py
deleted file mode 100644
index acf551f..0000000
--- a/src/music_kraken/__init__.py
+++ /dev/null
@@ -1,35 +0,0 @@
-import logging
-
-import gc
-import musicbrainzngs
-
-from .utils.shared import DEBUG
-from .utils.config import logging_settings, main_settings, read_config
-read_config()
-from . import cli
-
-
-# configure logger default
-logging.basicConfig(
- level=logging_settings['log_level'] if not DEBUG else logging.DEBUG,
- format=logging_settings['logging_format'],
- handlers=[
- logging.FileHandler(main_settings['log_file']),
- logging.StreamHandler()
- ]
-)
-
-if main_settings['modify_gc']:
- """
- At the start I modify the garbage collector to run a bit fewer times.
- This should increase speed:
- https://mkennedy.codes/posts/python-gc-settings-change-this-and-make-your-app-go-20pc-faster/
- """
- # Clean up what might be garbage so far.
- gc.collect(2)
-
- allocs, gen1, gen2 = gc.get_threshold()
- allocs = 50_000 # Start the GC sequence every 50K not 700 allocations.
- gen1 = gen1 * 2
- gen2 = gen2 * 2
- gc.set_threshold(allocs, gen1, gen2)
diff --git a/src/music_kraken/database/data_models.py b/src/music_kraken/database/data_models.py
deleted file mode 100644
index 7deff35..0000000
--- a/src/music_kraken/database/data_models.py
+++ /dev/null
@@ -1,197 +0,0 @@
-from typing import List, Union, Type, Optional
-from peewee import (
- SqliteDatabase,
- PostgresqlDatabase,
- MySQLDatabase,
- Model,
- CharField,
- IntegerField,
- BooleanField,
- ForeignKeyField,
- TextField
-)
-
-"""
-**IMPORTANT**:
-
-never delete, modify the datatype or add constrains to ANY existing collumns,
-between the versions, that gets pushed out to the users.
-Else my function can't update legacy databases, to new databases,
-while keeping the data of the old ones.
-
-EVEN if that means to for example keep decimal values stored in strings.
-(not in my codebase though.)
-"""
-
-
-class BaseModel(Model):
- notes: str = CharField(null=True)
-
- class Meta:
- database = None
-
- @classmethod
- def Use(cls, database: Union[SqliteDatabase, PostgresqlDatabase, MySQLDatabase]) -> Model:
- cls._meta.database = database
- return cls
-
- def use(self, database: Union[SqliteDatabase, PostgresqlDatabase, MySQLDatabase]) -> Model:
- self._meta.database = database
- return self
-
-class ObjectModel(BaseModel):
- id: str = CharField(primary_key=True)
-
-class MainModel(BaseModel):
- additional_arguments: str = CharField(null=True)
- notes: str = CharField(null=True)
-
-
-class Song(MainModel):
- """A class representing a song in the music database."""
-
- title: str = CharField(null=True)
- isrc: str = CharField(null=True)
- length: int = IntegerField(null=True)
- tracksort: int = IntegerField(null=True)
- genre: str = CharField(null=True)
-
-
-class Album(MainModel):
- """A class representing an album in the music database."""
-
- title: str = CharField(null=True)
- album_status: str = CharField(null=True)
- album_type: str = CharField(null=True)
- language: str = CharField(null=True)
- date_string: str = CharField(null=True)
- date_format: str = CharField(null=True)
- barcode: str = CharField(null=True)
- albumsort: int = IntegerField(null=True)
-
-
-class Artist(MainModel):
- """A class representing an artist in the music database."""
-
- name: str = CharField(null=True)
- country: str = CharField(null=True)
- formed_in_date: str = CharField(null=True)
- formed_in_format: str = CharField(null=True)
- general_genre: str = CharField(null=True)
-
-
-class Label(MainModel):
- name: str = CharField(null=True)
-
-
-class Target(ObjectModel):
- """A class representing a target of a song in the music database."""
-
- file: str = CharField()
- path: str = CharField()
- song = ForeignKeyField(Song, backref='targets')
-
-
-class Lyrics(ObjectModel):
- """A class representing lyrics of a song in the music database."""
-
- text: str = TextField()
- language: str = CharField()
- song = ForeignKeyField(Song, backref='lyrics')
-
-
-class Source(BaseModel):
- """A class representing a source of a song in the music database."""
- ContentTypes = Union[Song, Album, Artist, Lyrics]
-
- page: str = CharField()
- url: str = CharField()
-
- content_type: str = CharField()
- content_id: int = CharField()
- # content: ForeignKeyField = ForeignKeyField('self', backref='content_items', null=True)
-
- @property
- def content_object(self) -> Union[Song, Album, Artist]:
- """Get the content associated with the source as an object."""
- if self.content_type == 'Song':
- return Song.get(Song.id == self.content_id)
- if self.content_type == 'Album':
- return Album.get(Album.id == self.content_id)
- if self.content_type == 'Artist':
- return Artist.get(Artist.id == self.content_id)
- if self.content_type == 'Label':
- return Label.get(Label.id == self.content_id)
- if self.content_type == 'Lyrics':
- return Lyrics.get(Lyrics.id == self.content_id)
-
-
- @content_object.setter
- def content_object(self, value: Union[Song, Album, Artist]) -> None:
- """Set the content associated with the source as an object."""
- self.content_type = value.__class__.__name__
- self.content_id = value.id
-
-
-class SongArtist(BaseModel):
- """A class representing the relationship between a song and an artist."""
-
- song: ForeignKeyField = ForeignKeyField(Song, backref='song_artists')
- artist: ForeignKeyField = ForeignKeyField(Artist, backref='song_artists')
- is_feature: bool = BooleanField(default=False)
-
-
-class ArtistAlbum(BaseModel):
- """A class representing the relationship between an album and an artist."""
-
- album: ForeignKeyField = ForeignKeyField(Album, backref='album_artists')
- artist: ForeignKeyField = ForeignKeyField(Artist, backref='album_artists')
-
-
-class AlbumSong(BaseModel):
- """A class representing the relationship between an album and an song."""
- album: ForeignKeyField = ForeignKeyField(Album, backref='album_artists')
- song: ForeignKeyField = ForeignKeyField(Song, backref='album_artists')
-
-
-class LabelAlbum(BaseModel):
- label: ForeignKeyField = ForeignKeyField(Label, backref='label_album')
- album: ForeignKeyField = ForeignKeyField(Album, backref='label_album')
-
-
-class LabelArtist(BaseModel):
- label: ForeignKeyField = ForeignKeyField(Label, backref='label_artist')
- artist: ForeignKeyField = ForeignKeyField(Artist, backref='label_artists')
-
-
-ALL_MODELS = [
- Song,
- Album,
- Artist,
- Source,
- Lyrics,
- ArtistAlbum,
- Target,
- SongArtist
-]
-
-if __name__ == "__main__":
- database_1 = SqliteDatabase(":memory:")
- database_1.create_tables([Song.Use(database_1)])
- database_2 = SqliteDatabase(":memory:")
- database_2.create_tables([Song.Use(database_2)])
-
- # creating songs, adding it to db_2 if i is even, else to db_1
- for i in range(100):
- song = Song(name=str(i) + "hs")
-
- db_to_use = database_2 if i % 2 == 0 else database_1
- song.use(db_to_use).save()
-
- print("database 1")
- for song in Song.Use(database_1).select():
- print(song.name)
-
- print("database 2")
- for song in Song.Use(database_1).select():
- print(song.name)
diff --git a/src/music_kraken/database/database.py b/src/music_kraken/database/database.py
deleted file mode 100644
index 0120a89..0000000
--- a/src/music_kraken/database/database.py
+++ /dev/null
@@ -1,188 +0,0 @@
-# Standard library
-from typing import Optional, Union, List
-from enum import Enum
-from playhouse.migrate import *
-
-# third party modules
-from peewee import (
- SqliteDatabase,
- MySQLDatabase,
- PostgresqlDatabase,
-)
-
-# own modules
-from . import (
- data_models,
- write
-)
-from .. import objects
-
-
-class DatabaseType(Enum):
- SQLITE = "sqlite"
- POSTGRESQL = "postgresql"
- MYSQL = "mysql"
-
-class Database:
- database: Union[SqliteDatabase, PostgresqlDatabase, MySQLDatabase]
-
- def __init__(
- self,
- db_type: DatabaseType,
- db_name: str,
- db_user: Optional[str] = None,
- db_password: Optional[str] = None,
- db_host: Optional[str] = None,
- db_port: Optional[int] = None
- ):
- self.db_type = db_type
- self.db_name = db_name
- self.db_user = db_user
- self.db_password = db_password
- self.db_host = db_host
- self.db_port = db_port
-
- self.initialize_database()
-
- def create_database(self) -> Union[SqliteDatabase, PostgresqlDatabase, MySQLDatabase]:
- """Create a database instance based on the configured database type and parameters.
-
- Returns:
- The created database instance, or None if an invalid database type was specified.
- """
-
- # SQLITE
- if self.db_type == DatabaseType.SQLITE:
- return SqliteDatabase(self.db_name)
-
- # POSTGRES
- if self.db_type == DatabaseType.POSTGRESQL:
- return PostgresqlDatabase(
- self.db_name,
- user=self.db_user,
- password=self.db_password,
- host=self.db_host,
- port=self.db_port,
- )
-
- # MYSQL
- if self.db_type == DatabaseType.MYSQL:
- return MySQLDatabase(
- self.db_name,
- user=self.db_user,
- password=self.db_password,
- host=self.db_host,
- port=self.db_port,
- )
-
- raise ValueError("Invalid database type specified.")
-
-
- @property
- def migrator(self) -> SchemaMigrator:
- if self.db_type == DatabaseType.SQLITE:
- return SqliteMigrator(self.database)
-
- if self.db_type == DatabaseType.MYSQL:
- return MySQLMigrator(self.database)
-
- if self.db_type == DatabaseType.POSTGRESQL:
- return PostgresqlMigrator(self.database)
-
- def initialize_database(self):
- """
- Connect to the database
- initialize the previously defined databases
- create tables if they don't exist.
- """
- self.database = self.create_database()
- self.database.connect()
-
- migrator = self.migrator
-
- for model in data_models.ALL_MODELS:
- model = model.Use(self.database)
-
- if self.database.table_exists(model):
- migration_operations = [
- migrator.add_column(
- "some field", field[0], field[1]
- )
- for field in model._meta.fields.items()
- ]
-
- migrate(*migration_operations)
- else:
- self.database.create_tables([model], safe=True)
-
- #self.database.create_tables([model.Use(self.database) for model in data_models.ALL_MODELS], safe=True)
-
- """
- upgrade old databases.
- If a collumn has been added in a new version this adds it to old Tables,
- without deleting the data in legacy databases
- """
-
- for model in data_models.ALL_MODELS:
- model = model.Use(self.database)
-
-
-
- print(model._meta.fields)
-
- def push(self, database_object: objects.DatabaseObject):
- """
- Adds a new music object to the database using the corresponding method from the `write` session.
- When possible, rather use the `push_many` function.
- This gets even more important, when using a remote database server.
-
- Args:
- database_object (objects.MusicObject): The music object to add to the database.
-
- Returns:
- The newly added music object.
- """
-
- with write.WritingSession(self.database) as writing_session:
- if isinstance(database_object, objects.Song):
- return writing_session.add_song(database_object)
-
- if isinstance(database_object, objects.Album):
- return writing_session.add_album(database_object)
-
- if isinstance(database_object, objects.Artist):
- return writing_session.add_artist(database_object)
-
- def push_many(self, database_objects: List[objects.DatabaseObject]) -> None:
- """
- Adds a list of MusicObject instances to the database.
- This function sends only needs one querry for each type of table added.
- Beware that if you have for example an object like this:
- - Album
- - Song
- - Song
- you already have 3 different Tables.
-
- Unlike the function `push`, this function doesn't return the added database objects.
-
- Args:
- database_objects: List of MusicObject instances to be added to the database.
- """
-
- with write.WritingSession(self.database) as writing_session:
- for obj in database_objects:
- if isinstance(obj, objects.Song):
- writing_session.add_song(obj)
- continue
-
- if isinstance(obj, objects.Album):
- writing_session.add_album(obj)
- continue
-
- if isinstance(obj, objects.Artist):
- writing_session.add_artist(obj)
- continue
-
-
- def __del__(self):
- self.database.close()
diff --git a/src/music_kraken/objects/collection.py b/src/music_kraken/objects/collection.py
deleted file mode 100644
index 2b9ce72..0000000
--- a/src/music_kraken/objects/collection.py
+++ /dev/null
@@ -1,166 +0,0 @@
-from typing import List, Iterable, Dict, TypeVar, Generic, Iterator
-from collections import defaultdict
-from dataclasses import dataclass
-
-from .parents import DatabaseObject
-
-
-T = TypeVar('T', bound=DatabaseObject)
-
-
-@dataclass
-class AppendResult:
- was_in_collection: bool
- current_element: DatabaseObject
- was_the_same: bool
-
-
-class Collection(Generic[T]):
- """
- This a class for the iterables
- like tracklist or discography
- """
- _data: List[T]
-
- _by_url: dict
- _by_attribute: dict
-
- def __init__(self, data: List[T] = None, element_type=None, *args, **kwargs) -> None:
- # Attribute needs to point to
- self.element_type = element_type
-
- self._data: List[T] = list()
-
- """
- example of attribute_to_object_map
- the song objects are references pointing to objects
- in _data
-
- ```python
- {
- 'id': {323: song_1, 563: song_2, 666: song_3},
- 'url': {'www.song_2.com': song_2}
- }
- ```
- """
- self._attribute_to_object_map: Dict[str, Dict[object, T]] = defaultdict(dict)
- self._used_ids: set = set()
-
- if data is not None:
- self.extend(data, merge_on_conflict=True)
-
- def sort(self, reverse: bool = False, **kwargs):
- self._data.sort(reverse=reverse, **kwargs)
-
- def map_element(self, element: T):
- for name, value in element.indexing_values:
- if value is None:
- continue
-
- self._attribute_to_object_map[name][value] = element
-
- self._used_ids.add(element.id)
-
- def unmap_element(self, element: T):
- for name, value in element.indexing_values:
- if value is None:
- continue
-
- if value in self._attribute_to_object_map[name]:
- if element is self._attribute_to_object_map[name][value]:
- try:
- self._attribute_to_object_map[name].pop(value)
- except KeyError:
- pass
-
- def append(self, element: T, merge_on_conflict: bool = True,
- merge_into_existing: bool = True) -> AppendResult:
- """
- :param element:
- :param merge_on_conflict:
- :param merge_into_existing:
- :return did_not_exist:
- """
-
- # if the element type has been defined in the initializer it checks if the type matches
- if self.element_type is not None and not isinstance(element, self.element_type):
- raise TypeError(f"{type(element)} is not the set type {self.element_type}")
-
- # return if the same instance of the object is in the list
- for existing in self._data:
- if element is existing:
- return AppendResult(True, element, True)
-
- for name, value in element.indexing_values:
- if value in self._attribute_to_object_map[name]:
- existing_object = self._attribute_to_object_map[name][value]
-
- if not merge_on_conflict:
- return AppendResult(True, existing_object, False)
-
- # if the object does already exist
- # thus merging and don't add it afterward
- if merge_into_existing:
- existing_object.merge(element)
- # in case any relevant data has been added (e.g. it remaps the old object)
- self.map_element(existing_object)
- return AppendResult(True, existing_object, False)
-
- element.merge(existing_object)
-
- exists_at = self._data.index(existing_object)
- self._data[exists_at] = element
-
- self.unmap_element(existing_object)
- self.map_element(element)
- return AppendResult(True, existing_object, False)
-
- self._data.append(element)
- self.map_element(element)
-
- return AppendResult(False, element, False)
-
- def extend(self, element_list: Iterable[T], merge_on_conflict: bool = True,
- merge_into_existing: bool = True):
- for element in element_list:
- self.append(element, merge_on_conflict=merge_on_conflict, merge_into_existing=merge_into_existing)
-
- def __iter__(self) -> Iterator[T]:
- for element in self.shallow_list:
- yield element
-
- def __str__(self) -> str:
- return "\n".join([f"{str(j).zfill(2)}: {i.__repr__()}" for j, i in enumerate(self._data)])
-
- def __len__(self) -> int:
- return len(self._data)
-
- def __getitem__(self, key) -> T:
- if type(key) != int:
- return ValueError("key needs to be an integer")
-
- return self._data[key]
-
- def __setitem__(self, key, value: T):
- if type(key) != int:
- return ValueError("key needs to be an integer")
-
- old_item = self._data[key]
- self.unmap_element(old_item)
- self.map_element(value)
-
- self._data[key] = value
-
- @property
- def shallow_list(self) -> List[T]:
- """
- returns a shallow copy of the data list
- """
- return self._data.copy()
-
- @property
- def empty(self) -> bool:
- return len(self._data) == 0
-
- def clear(self):
- self.__init__(element_type=self.element_type)
diff --git a/src/music_kraken/objects/formatted_text.py b/src/music_kraken/objects/formatted_text.py
deleted file mode 100644
index 20927a3..0000000
--- a/src/music_kraken/objects/formatted_text.py
+++ /dev/null
@@ -1,78 +0,0 @@
-import pandoc
-
-"""
-TODO
-implement in setup.py a skript to install pandocs
-https://pandoc.org/installing.html
-
-!!!!!!!!!!!!!!!!!!IMPORTANT!!!!!!!!!!!!!!!!!!
-"""
-
-
-class FormattedText:
- """
- the self.html value should be saved to the database
- """
-
- doc = None
-
- def __init__(
- self,
- plaintext: str = None,
- markdown: str = None,
- html: str = None
- ) -> None:
- self.set_plaintext(plaintext)
- self.set_markdown(markdown)
- self.set_html(html)
-
- def set_plaintext(self, plaintext: str):
- if plaintext is None:
- return
- self.doc = pandoc.read(plaintext)
-
- def set_markdown(self, markdown: str):
- if markdown is None:
- return
- self.doc = pandoc.read(markdown, format="markdown")
-
- def set_html(self, html: str):
- if html is None:
- return
- self.doc = pandoc.read(html, format="html")
-
- def get_markdown(self) -> str:
- if self.doc is None:
- return ""
- return pandoc.write(self.doc, format="markdown").strip()
-
- def get_html(self) -> str:
- if self.doc is None:
- return ""
- return pandoc.write(self.doc, format="html").strip()
-
- def get_plaintext(self) -> str:
- if self.doc is None:
- return ""
- return pandoc.write(self.doc, format="plain").strip()
-
- @property
- def is_empty(self) -> bool:
- return self.doc is None
-
- def __eq__(self, other) -> False:
- if type(other) != type(self):
- return False
- if self.is_empty and other.is_empty:
- return True
-
- return self.doc == other.doc
-
- def __str__(self) -> str:
- return self.plaintext
-
-
-
- plaintext = property(fget=get_plaintext, fset=set_plaintext)
- markdown = property(fget=get_markdown, fset=set_markdown)
- html = property(fget=get_html, fset=set_html)
diff --git a/src/music_kraken/objects/lyrics.py b/src/music_kraken/objects/lyrics.py
deleted file mode 100644
index 465b96d..0000000
--- a/src/music_kraken/objects/lyrics.py
+++ /dev/null
@@ -1,31 +0,0 @@
-from typing import List
-from collections import defaultdict
-import pycountry
-
-from .parents import DatabaseObject
-from .source import Source, SourceCollection
-from .formatted_text import FormattedText
-
-
-class Lyrics(DatabaseObject):
- COLLECTION_ATTRIBUTES = ("source_collection",)
- SIMPLE_ATTRIBUTES = {
- "text": FormattedText(),
- "language": None
- }
-
- def __init__(
- self,
- text: FormattedText,
- language: pycountry.Languages = pycountry.languages.get(alpha_2="en"),
- _id: str = None,
- dynamic: bool = False,
- source_list: List[Source] = None,
- **kwargs
- ) -> None:
- DatabaseObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
-
- self.text: FormattedText = text or FormattedText()
- self.language: pycountry.Languages = language
-
- self.source_collection: SourceCollection = SourceCollection(source_list)
diff --git a/src/music_kraken/objects/parents.py b/src/music_kraken/objects/parents.py
deleted file mode 100644
index a553700..0000000
--- a/src/music_kraken/objects/parents.py
+++ /dev/null
@@ -1,160 +0,0 @@
-import random
-from collections import defaultdict
-from typing import Optional, Dict, Tuple, List, Type
-
-from .metadata import Metadata
-from .option import Options
-from ..utils.shared import HIGHEST_ID
-from ..utils.config import main_settings, logging_settings
-
-
-LOGGER = logging_settings["object_logger"]
-
-
-class DatabaseObject:
- COLLECTION_ATTRIBUTES: tuple = tuple()
- SIMPLE_ATTRIBUTES: dict = dict()
-
- # contains all collection attributes, which describe something "smaller"
- # e.g. album has songs, but not artist.
- DOWNWARDS_COLLECTION_ATTRIBUTES: tuple = tuple()
- UPWARDS_COLLECTION_ATTRIBUTES: tuple = tuple()
-
- def __init__(self, _id: int = None, dynamic: bool = False, **kwargs) -> None:
- self.automatic_id: bool = False
-
- if _id is None and not dynamic:
- """
- generates a random integer id
- 64 bit integer, but this is defined in shared.py in ID_BITS
- the range is defined in the Tuple ID_RANGE
- """
- _id = random.randint(0, HIGHEST_ID)
- self.automatic_id = True
- LOGGER.debug(f"Id for {type(self).__name__} isn't set. Setting to {_id}")
-
- # The id can only be None, if the object is dynamic (self.dynamic = True)
- self.id: Optional[int] = _id
-
- self.dynamic = dynamic
-
- self.build_version = -1
-
- def __hash__(self):
- if self.dynamic:
- raise TypeError("Dynamic DatabaseObjects are unhashable.")
- return self.id
-
- def __eq__(self, other) -> bool:
- if not isinstance(other, type(self)):
- return False
-
- # add the checks for dynamic, to not throw an exception
- if not self.dynamic and not other.dynamic and self.id == other.id:
- return True
-
- temp_attribute_map: Dict[str, set] = defaultdict(set)
-
- # building map with sets
- for name, value in self.indexing_values:
- temp_attribute_map[name].add(value)
-
- # check against the attributes of the other object
- for name, other_value in other.indexing_values:
- if other_value in temp_attribute_map[name]:
- return True
-
- return False
-
- @property
- def indexing_values(self) -> List[Tuple[str, object]]:
- """
- returns a map of the name and values of the attributes.
- This helps in comparing classes for equal data (eg. being the same song but different attributes)
-
- Returns:
- List[Tuple[str, object]]: the first element in the tuple is the name of the attribute, the second the value.
- """
-
- return list()
-
- def merge(self, other, override: bool = False):
- if other is None:
- return
-
- if self is other:
- return
-
- if not isinstance(other, type(self)):
- LOGGER.warning(f"can't merge \"{type(other)}\" into \"{type(self)}\"")
- return
-
- for collection in type(self).COLLECTION_ATTRIBUTES:
- getattr(self, collection).extend(getattr(other, collection))
-
- for simple_attribute, default_value in type(self).SIMPLE_ATTRIBUTES.items():
- if getattr(other, simple_attribute) == default_value:
- continue
-
- if override or getattr(self, simple_attribute) == default_value:
- setattr(self, simple_attribute, getattr(other, simple_attribute))
-
- def strip_details(self):
- for collection in type(self).DOWNWARDS_COLLECTION_ATTRIBUTES:
- getattr(self, collection).clear()
-
- @property
- def metadata(self) -> Metadata:
- return Metadata()
-
- @property
- def options(self) -> List["DatabaseObject"]:
- return [self]
-
- @property
- def option_string(self) -> str:
- return self.__repr__()
-
- def _build_recursive_structures(self, build_version: int, merge: False):
- pass
-
- def compile(self, merge_into: bool = False):
- """
- compiles the recursive structures,
- and does depending on the object some other stuff.
-
- no need to override if only the recursive structure should be build.
- override self.build_recursive_structures() instead
- """
-
- self._build_recursive_structures(build_version=random.randint(0, 99999), merge=merge_into)
-
- def _add_other_db_objects(self, object_type: Type["DatabaseObject"], object_list: List["DatabaseObject"]):
- pass
-
- def add_list_of_other_objects(self, object_list: List["DatabaseObject"]):
- d: Dict[Type[DatabaseObject], List[DatabaseObject]] = defaultdict(list)
-
- for db_object in object_list:
- d[type(db_object)].append(db_object)
-
- for key, value in d.items():
- self._add_other_db_objects(key, value)
-
-
-class MainObject(DatabaseObject):
- """
- This is the parent class for all "main" data objects:
- - Song
- - Album
- - Artist
- - Label
-
- It has all the functionality of the "DatabaseObject" (it inherits from said class)
- but also some added functions as well.
- """
-
- def __init__(self, _id: int = None, dynamic: bool = False, **kwargs):
- DatabaseObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
-
- self.additional_arguments: dict = kwargs
diff --git a/src/music_kraken/objects/song.py b/src/music_kraken/objects/song.py
deleted file mode 100644
index 3f46d4b..0000000
--- a/src/music_kraken/objects/song.py
+++ /dev/null
@@ -1,780 +0,0 @@
-import random
-from collections import defaultdict
-from typing import List, Optional, Dict, Tuple, Type
-
-import pycountry
-
-from ..utils.enums.album import AlbumType, AlbumStatus
-from .collection import Collection
-from .formatted_text import FormattedText
-from .lyrics import Lyrics
-from .metadata import (
- Mapping as id3Mapping,
- ID3Timestamp,
- Metadata
-)
-from .option import Options
-from .parents import MainObject, DatabaseObject
-from .source import Source, SourceCollection
-from .target import Target
-from ..utils.string_processing import unify
-
-from ..utils.config import main_settings
-
-"""
-All Objects dependent
-"""
-
-CountryTyping = type(list(pycountry.countries)[0])
-OPTION_STRING_DELIMITER = " | "
-
-
-class Song(MainObject):
- """
- Class representing a song object, with attributes id, mb_id, title, album_name, isrc, length,
- tracksort, genre, source_list, target, lyrics_list, album, main_artist_list, and feature_artist_list.
- """
-
- COLLECTION_ATTRIBUTES = (
- "lyrics_collection", "album_collection", "main_artist_collection", "feature_artist_collection",
- "source_collection")
- SIMPLE_ATTRIBUTES = {
- "title": None,
- "unified_title": None,
- "isrc": None,
- "length": None,
- "tracksort": 0,
- "genre": None,
- "notes": FormattedText()
- }
-
- UPWARDS_COLLECTION_ATTRIBUTES = ("album_collection", "main_artist_collection", "feature_artist_collection")
-
- def __init__(
- self,
- _id: int = None,
- dynamic: bool = False,
- title: str = None,
- unified_title: str = None,
- isrc: str = None,
- length: int = None,
- tracksort: int = None,
- genre: str = None,
- source_list: List[Source] = None,
- target_list: List[Target] = None,
- lyrics_list: List[Lyrics] = None,
- album_list: List['Album'] = None,
- main_artist_list: List['Artist'] = None,
- feature_artist_list: List['Artist'] = None,
- notes: FormattedText = None,
- **kwargs
- ) -> None:
- MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
- # attributes
- self.title: str = title
- self.unified_title: str = unified_title
- if unified_title is None and title is not None:
- self.unified_title = unify(title)
-
- self.isrc: str = isrc
- self.length: int = length
- self.tracksort: int = tracksort or 0
- self.genre: str = genre
- self.notes: FormattedText = notes or FormattedText()
-
- self.source_collection: SourceCollection = SourceCollection(source_list)
- self.target_collection: Collection[Target] = Collection(data=target_list, element_type=Target)
- self.lyrics_collection: Collection[Lyrics] = Collection(data=lyrics_list, element_type=Lyrics)
- self.album_collection: Collection[Album] = Collection(data=album_list, element_type=Album)
- self.main_artist_collection: Collection[Artist] = Collection(data=main_artist_list, element_type=Artist)
- self.feature_artist_collection: Collection[Artist] = Collection(data=feature_artist_list, element_type=Artist)
-
- def _build_recursive_structures(self, build_version: int, merge: bool):
- if build_version == self.build_version:
- return
- self.build_version = build_version
-
- album: Album
- for album in self.album_collection:
- album.song_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- album._build_recursive_structures(build_version=build_version, merge=merge)
-
- artist: Artist
- for artist in self.feature_artist_collection:
- artist.feature_song_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- artist._build_recursive_structures(build_version=build_version, merge=merge)
-
- for artist in self.main_artist_collection:
- for album in self.album_collection:
- artist.main_album_collection.append(album, merge_on_conflict=merge, merge_into_existing=False)
- artist._build_recursive_structures(build_version=build_version, merge=merge)
-
- def _add_other_db_objects(self, object_type: Type["DatabaseObject"], object_list: List["DatabaseObject"]):
- if object_type is Song:
- return
-
- if object_type is Lyrics:
- self.lyrics_collection.extend(object_list)
- return
-
- if object_type is Artist:
- self.main_artist_collection.extend(object_list)
- return
-
- if object_type is Album:
- self.album_collection.extend(object_list)
- return
-
-
- @property
- def indexing_values(self) -> List[Tuple[str, object]]:
- return [
- ('id', self.id),
- ('title', self.unified_title),
- ('isrc', self.isrc),
- *[('url', source.url) for source in self.source_collection]
- ]
-
- @property
- def metadata(self) -> Metadata:
- metadata = Metadata({
- id3Mapping.TITLE: [self.title],
- id3Mapping.ISRC: [self.isrc],
- id3Mapping.LENGTH: [self.length],
- id3Mapping.GENRE: [self.genre],
- id3Mapping.TRACKNUMBER: [self.tracksort_str]
- })
-
- # metadata.merge_many([s.get_song_metadata() for s in self.source_collection]) album sources have no relevant metadata for id3
- metadata.merge_many([a.metadata for a in self.album_collection])
- metadata.merge_many([a.metadata for a in self.main_artist_collection])
- metadata.merge_many([a.metadata for a in self.feature_artist_collection])
- metadata.merge_many([lyrics.metadata for lyrics in self.lyrics_collection])
-
- return metadata
-
- def get_artist_credits(self) -> str:
- main_artists = ", ".join([artist.name for artist in self.main_artist_collection])
- feature_artists = ", ".join([artist.name for artist in self.feature_artist_collection])
-
- if len(feature_artists) == 0:
- return main_artists
- return f"{main_artists} feat. {feature_artists}"
-
- def __str__(self) -> str:
- artist_credit_str = ""
- artist_credits = self.get_artist_credits()
- if artist_credits != "":
- artist_credit_str = f" by {artist_credits}"
-
- return f"\"{self.title}\"{artist_credit_str}"
-
- def __repr__(self) -> str:
- return f"Song(\"{self.title}\")"
-
- @property
- def option_string(self) -> str:
- return f"{self.__repr__()} " \
- f"from Album({OPTION_STRING_DELIMITER.join(album.title for album in self.album_collection)}) " \
- f"by Artist({OPTION_STRING_DELIMITER.join(artist.name for artist in self.main_artist_collection)}) " \
- f"feat. Artist({OPTION_STRING_DELIMITER.join(artist.name for artist in self.feature_artist_collection)})"
-
- @property
- def options(self) -> List[DatabaseObject]:
- """
- Return a list of related objects including the song object, album object, main artist objects, and
- feature artist objects.
-
- :return: a list of objects that are related to the Song object
- """
- options = self.main_artist_collection.shallow_list
- options.extend(self.feature_artist_collection)
- options.extend(self.album_collection)
- options.append(self)
- return options
-
- @property
- def tracksort_str(self) -> str:
- """
- if the album tracklist is empty, it sets it length to 1, this song has to be on the Album
- :returns id3_tracksort: {song_position}/{album.length_of_tracklist}
- """
- if len(self.album_collection) == 0:
- return f"{self.tracksort}"
-
- return f"{self.tracksort}/{len(self.album_collection[0].song_collection) or 1}"
-
-
-"""
-All objects dependent on Album
-"""
-
-
-class Album(MainObject):
- COLLECTION_ATTRIBUTES = ("label_collection", "artist_collection", "song_collection")
- SIMPLE_ATTRIBUTES = {
- "title": None,
- "unified_title": None,
- "album_status": None,
- "album_type": AlbumType.OTHER,
- "language": None,
- "date": ID3Timestamp(),
- "barcode": None,
- "albumsort": None,
- "notes": FormattedText()
- }
-
- DOWNWARDS_COLLECTION_ATTRIBUTES = ("song_collection", )
- UPWARDS_COLLECTION_ATTRIBUTES = ("artist_collection", "label_collection")
-
- def __init__(
- self,
- _id: int = None,
- title: str = None,
- unified_title: str = None,
- language: pycountry.Languages = None,
- date: ID3Timestamp = None,
- barcode: str = None,
- albumsort: int = None,
- dynamic: bool = False,
- source_list: List[Source] = None,
- artist_list: List['Artist'] = None,
- song_list: List[Song] = None,
- album_status: AlbumStatus = None,
- album_type: AlbumType = None,
- label_list: List['Label'] = None,
- notes: FormattedText = None,
- **kwargs
- ) -> None:
- MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
-
- self.title: str = title
- self.unified_title: str = unified_title
- if unified_title is None and title is not None:
- self.unified_title = unify(title)
-
- self.album_status: AlbumStatus = album_status
- self.album_type: AlbumType = album_type or AlbumType.OTHER
- self.language: pycountry.Languages = language
- self.date: ID3Timestamp = date or ID3Timestamp()
-
- """
- TODO
- find out the id3 tag for barcode and implement it
- maybe look at how mutagen does it with easy_id3
- """
- self.barcode: str = barcode
- """
- TODO
- implement a function in the Artist class,
- to set albumsort with help of the release year
- """
- self.albumsort: Optional[int] = albumsort
- self.notes = notes or FormattedText()
-
- self.source_collection: SourceCollection = SourceCollection(source_list)
- self.song_collection: Collection[Song] = Collection(data=song_list, element_type=Song)
- self.artist_collection: Collection[Artist] = Collection(data=artist_list, element_type=Artist)
- self.label_collection: Collection[Label] = Collection(data=label_list, element_type=Label)
-
- def _build_recursive_structures(self, build_version: int, merge: bool):
- if build_version == self.build_version:
- return
- self.build_version = build_version
-
- song: Song
- for song in self.song_collection:
- song.album_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- song._build_recursive_structures(build_version=build_version, merge=merge)
-
- artist: Artist
- for artist in self.artist_collection:
- artist.main_album_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- artist._build_recursive_structures(build_version=build_version, merge=merge)
-
- label: Label
- for label in self.label_collection:
- label.album_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- label._build_recursive_structures(build_version=build_version, merge=merge)
-
- def _add_other_db_objects(self, object_type: Type["DatabaseObject"], object_list: List["DatabaseObject"]):
- if object_type is Song:
- self.song_collection.extend(object_list)
- return
-
- if object_type is Artist:
- self.artist_collection.extend(object_list)
- return
-
- if object_type is Album:
- return
-
- if object_type is Label:
- self.label_collection.extend(object_list)
- return
-
- @property
- def indexing_values(self) -> List[Tuple[str, object]]:
- return [
- ('id', self.id),
- ('title', self.unified_title),
- ('barcode', self.barcode),
- *[('url', source.url) for source in self.source_collection]
- ]
-
- @property
- def metadata(self) -> Metadata:
- return Metadata({
- id3Mapping.ALBUM: [self.title],
- id3Mapping.COPYRIGHT: [self.copyright],
- id3Mapping.LANGUAGE: [self.iso_639_2_lang],
- id3Mapping.ALBUM_ARTIST: [a.name for a in self.artist_collection],
- id3Mapping.DATE: [self.date.strftime("%d%m")] if self.date.has_year and self.date.has_month else [],
- id3Mapping.TIME: [self.date.strftime(("%H%M"))] if self.date.has_hour and self.date.has_minute else [],
- id3Mapping.YEAR: [str(self.date.year).zfill(4)] if self.date.has_year else [],
- id3Mapping.RELEASE_DATE: [self.date.timestamp],
- id3Mapping.ORIGINAL_RELEASE_DATE: [self.date.timestamp],
- id3Mapping.ALBUMSORTORDER: [str(self.albumsort)] if self.albumsort is not None else []
- })
-
- def __repr__(self):
- return f"Album(\"{self.title}\")"
-
- @property
- def option_string(self) -> str:
- return f"{self.__repr__()} " \
- f"by Artist({OPTION_STRING_DELIMITER.join([artist.name for artist in self.artist_collection])}) " \
- f"under Label({OPTION_STRING_DELIMITER.join([label.name for label in self.label_collection])})"
-
- @property
- def options(self) -> List[DatabaseObject]:
- options = self.artist_collection.shallow_list
- options.append(self)
- options.extend(self.song_collection)
-
- return options
-
- def update_tracksort(self):
- """
- This updates the tracksort attributes, of the songs in
- `self.song_collection`, and sorts the songs, if possible.
-
- It is advised to only call this function, once all the tracks are
- added to the songs.
-
- :return:
- """
-
- if self.song_collection.empty:
- return
-
- tracksort_map: Dict[int, Song] = {
- song.tracksort: song for song in self.song_collection if song.tracksort is not None
- }
-
- # place the songs, with set tracksort attribute according to it
- for tracksort, song in tracksort_map.items():
- index = tracksort - 1
-
- """
- I ONLY modify the `Collection._data` attribute directly,
- to bypass the mapping of the attributes, because I will add the item in the next step
- """
-
- """
- but for some reason, neither
- `self.song_collection._data.index(song)`
- `self.song_collection._data.remove(song)`
- get the right object.
-
- I have NO FUCKING CLUE why xD
- But I just implemented it myself.
- """
- for old_index, temp_song in enumerate(self.song_collection._data):
- if song is temp_song:
- break
-
- # the list can't be empty
- del self.song_collection._data[old_index]
- self.song_collection._data.insert(index, song)
-
- # fill in the empty tracksort attributes
- for i, song in enumerate(self.song_collection):
- if song.tracksort is not None:
- continue
- song.tracksort = i + 1
-
- def compile(self, merge_into: bool = False):
- """
- compiles the recursive structures,
- and does depending on the object some other stuff.
-
- no need to override if only the recursive structure should be built.
- override self.build_recursive_structures() instead
- """
-
- self.update_tracksort()
- self._build_recursive_structures(build_version=random.randint(0, 99999), merge=merge_into)
-
- @property
- def copyright(self) -> str:
- if self.date is None:
- return ""
- if self.date.has_year or len(self.label_collection) == 0:
- return ""
-
- return f"{self.date.year} {self.label_collection[0].name}"
-
- @property
- def iso_639_2_lang(self) -> Optional[str]:
- if self.language is None:
- return None
-
- return self.language.alpha_3
-
- @property
- def is_split(self) -> bool:
- """
- A split Album is an Album from more than one Artists
- usually half the songs are made by one Artist, the other half by the other one.
- In this case split means either that or one artist featured by all songs.
- :return:
- """
- return len(self.artist_collection) > 1
-
- @property
- def album_type_string(self) -> str:
- return self.album_type.value
-
-
-"""
-All objects dependent on Artist
-"""
-
-
-class Artist(MainObject):
- COLLECTION_ATTRIBUTES = (
- "feature_song_collection",
- "main_album_collection",
- "label_collection",
- "source_collection"
- )
- SIMPLE_ATTRIBUTES = {
- "name": None,
- "unified_name": None,
- "country": None,
- "formed_in": ID3Timestamp(),
- "notes": FormattedText(),
- "lyrical_themes": [],
- "general_genre": ""
- }
-
- DOWNWARDS_COLLECTION_ATTRIBUTES = ("feature_song_collection", "main_album_collection")
- UPWARDS_COLLECTION_ATTRIBUTES = ("label_collection", )
-
- def __init__(
- self,
- _id: int = None,
- dynamic: bool = False,
- name: str = None,
- unified_name: str = None,
- source_list: List[Source] = None,
- feature_song_list: List[Song] = None,
- main_album_list: List[Album] = None,
- notes: FormattedText = None,
- lyrical_themes: List[str] = None,
- general_genre: str = "",
- country: CountryTyping = None,
- formed_in: ID3Timestamp = None,
- label_list: List['Label'] = None,
- **kwargs
- ):
- MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
-
- self.name: str = name
- self.unified_name: str = unified_name
- if unified_name is None and name is not None:
- self.unified_name = unify(name)
-
- """
- TODO implement album type and notes
- """
- self.country: CountryTyping = country
- self.formed_in: ID3Timestamp = formed_in
- """
- notes, general genre, lyrics themes are attributes
- which are meant to only use in outputs to describe the object
- i mean do as you want but there is no strict rule about em so good luck
- """
- self.notes: FormattedText = notes or FormattedText()
-
- self.lyrical_themes: List[str] = lyrical_themes or []
- self.general_genre = general_genre
-
- self.source_collection: SourceCollection = SourceCollection(source_list)
- self.feature_song_collection: Collection[Song] = Collection(data=feature_song_list, element_type=Song)
- self.main_album_collection: Collection[Album] = Collection(data=main_album_list, element_type=Album)
- self.label_collection: Collection[Label] = Collection(data=label_list, element_type=Label)
-
- def _add_other_db_objects(self, object_type: Type["DatabaseObject"], object_list: List["DatabaseObject"]):
- if object_type is Song:
- # this doesn't really make sense
- # self.feature_song_collection.extend(object_list)
- return
-
- if object_type is Artist:
- return
-
- if object_type is Album:
- self.main_album_collection.extend(object_list)
- return
-
- if object_type is Label:
- self.label_collection.extend(object_list)
- return
-
- def compile(self, merge_into: bool = False):
- """
- compiles the recursive structures,
- and does depending on the object some other stuff.
-
- no need to override if only the recursive structure should be built.
- override self.build_recursive_structures() instead
- """
-
- self.update_albumsort()
- self._build_recursive_structures(build_version=random.randint(0, 99999), merge=merge_into)
-
- def update_albumsort(self):
- """
- This updates the albumsort attributes, of the albums in
- `self.main_album_collection`, and sorts the albums, if possible.
-
- It is advised to only call this function, once all the albums are
- added to the artist.
-
- :return:
- """
- if len(self.main_album_collection) <= 0:
- return
-
- type_section: Dict[AlbumType] = defaultdict(lambda: 2, {
- AlbumType.OTHER: 0, # if I don't know it, I add it to the first section
- AlbumType.STUDIO_ALBUM: 0,
- AlbumType.EP: 0,
- AlbumType.SINGLE: 1
- }) if main_settings["sort_album_by_type"] else defaultdict(lambda: 0)
-
- sections = defaultdict(list)
-
- # order albums in the previously defined section
- album: Album
- for album in self.main_album_collection:
- sections[type_section[album.album_type]].append(album)
-
- def sort_section(_section: List[Album], last_albumsort: int) -> int:
- # album is just a value used in loops
- nonlocal album
-
- if main_settings["sort_by_date"]:
- _section.sort(key=lambda _album: _album.date, reverse=True)
-
- new_last_albumsort = last_albumsort
-
- for album_index, album in enumerate(_section):
- if album.albumsort is None:
- album.albumsort = new_last_albumsort = album_index + 1 + last_albumsort
-
- _section.sort(key=lambda _album: _album.albumsort)
-
- return new_last_albumsort
-
- # sort the sections individually
- _last_albumsort = 1
- for section_index in sorted(sections):
- _last_albumsort = sort_section(sections[section_index], _last_albumsort)
-
- # merge all sections again
- album_list = []
- for section_index in sorted(sections):
- album_list.extend(sections[section_index])
-
- # replace the old collection with the new one
- self.main_album_collection: Collection = Collection(data=album_list, element_type=Album)
-
-
- def _build_recursive_structures(self, build_version: int, merge: False):
- if build_version == self.build_version:
- return
- self.build_version = build_version
-
- song: Song
- for song in self.feature_song_collection:
- song.feature_artist_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- song._build_recursive_structures(build_version=build_version, merge=merge)
-
- album: Album
- for album in self.main_album_collection:
- album.artist_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- album._build_recursive_structures(build_version=build_version, merge=merge)
-
- label: Label
- for label in self.label_collection:
- label.current_artist_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- label._build_recursive_structures(build_version=build_version, merge=merge)
-
- @property
- def indexing_values(self) -> List[Tuple[str, object]]:
- return [
- ('id', self.id),
- ('name', self.unified_name),
- *[('url', source.url) for source in self.source_collection]
- ]
-
- @property
- def metadata(self) -> Metadata:
- metadata = Metadata({
- id3Mapping.ARTIST: [self.name]
- })
- metadata.merge_many([s.get_artist_metadata() for s in self.source_collection])
-
- return metadata
-
- def __str__(self):
- string = self.name or ""
- plaintext_notes = self.notes.get_plaintext()
- if plaintext_notes is not None:
- string += "\n" + plaintext_notes
- return string
-
- def __repr__(self):
- return f"Artist(\"{self.name}\")"
-
- @property
- def option_string(self) -> str:
- return f"{self.__repr__()} " \
- f"under Label({OPTION_STRING_DELIMITER.join([label.name for label in self.label_collection])})"
-
- @property
- def options(self) -> List[DatabaseObject]:
- options = [self]
- options.extend(self.main_album_collection)
- options.extend(self.feature_song_collection)
- return options
-
- @property
- def country_string(self):
- return self.country.alpha_3
-
- @property
- def feature_album(self) -> Album:
- return Album(
- title="features",
- album_status=AlbumStatus.UNRELEASED,
- album_type=AlbumType.COMPILATION_ALBUM,
- is_split=True,
- albumsort=666,
- dynamic=True,
- song_list=self.feature_song_collection.shallow_list
- )
-
- def get_all_songs(self) -> List[Song]:
- """
- returns a list of all Songs.
- probably not that useful, because it is unsorted
- """
- collection = self.feature_song_collection.copy()
- for album in self.discography:
- collection.extend(album.song_collection)
-
- return collection
-
- @property
- def discography(self) -> List[Album]:
- flat_copy_discography = self.main_album_collection.copy()
- flat_copy_discography.append(self.feature_album)
-
- return flat_copy_discography
-
-
-"""
-Label
-"""
-
-
-class Label(MainObject):
- COLLECTION_ATTRIBUTES = ("album_collection", "current_artist_collection")
- SIMPLE_ATTRIBUTES = {
- "name": None,
- "unified_name": None,
- "notes": FormattedText()
- }
-
- DOWNWARDS_COLLECTION_ATTRIBUTES = COLLECTION_ATTRIBUTES
-
- def __init__(
- self,
- _id: int = None,
- dynamic: bool = False,
- name: str = None,
- unified_name: str = None,
- notes: FormattedText = None,
- album_list: List[Album] = None,
- current_artist_list: List[Artist] = None,
- source_list: List[Source] = None,
- **kwargs
- ):
- MainObject.__init__(self, _id=_id, dynamic=dynamic, **kwargs)
-
- self.name: str = name
- self.unified_name: str = unified_name
- if unified_name is None and name is not None:
- self.unified_name = unify(name)
- self.notes = notes or FormattedText()
-
- self.source_collection: SourceCollection = SourceCollection(source_list)
- self.album_collection: Collection[Album] = Collection(data=album_list, element_type=Album)
- self.current_artist_collection: Collection[Artist] = Collection(data=current_artist_list, element_type=Artist)
-
- def _add_other_db_objects(self, object_type: Type["DatabaseObject"], object_list: List["DatabaseObject"]):
- if object_type is Song:
- return
-
- if object_type is Artist:
- self.current_artist_collection.extend(object_list)
- return
-
- if object_type is Album:
- self.album_collection.extend(object_list)
- return
-
- def _build_recursive_structures(self, build_version: int, merge: False):
- if build_version == self.build_version:
- return
- self.build_version = build_version
-
- album: Album
- for album in self.album_collection:
- album.label_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- album._build_recursive_structures(build_version=build_version, merge=merge)
-
- artist: Artist
- for artist in self.current_artist_collection:
- artist.label_collection.append(self, merge_on_conflict=merge, merge_into_existing=False)
- artist._build_recursive_structures(build_version=build_version, merge=merge)
-
- @property
- def indexing_values(self) -> List[Tuple[str, object]]:
- return [
- ('id', self.id),
- ('name', self.unified_name),
- *[('url', source.url) for source in self.source_collection]
- ]
-
- @property
- def options(self) -> List[DatabaseObject]:
- options = [self]
- options.extend(self.current_artist_collection.shallow_list)
- options.extend(self.album_collection.shallow_list)
-
- return options
diff --git a/src/music_kraken/utils/__init__.py b/src/music_kraken/utils/__init__.py
deleted file mode 100644
index 89186a6..0000000
--- a/src/music_kraken/utils/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .config import config, read_config, write_config
diff --git a/src/music_kraken/utils/config/attributes/__init__,py b/src/music_kraken/utils/config/attributes/__init__,py
deleted file mode 100644
index e69de29..0000000
diff --git a/src/music_kraken/utils/config/sections/audio.py b/src/music_kraken/utils/config/sections/audio.py
deleted file mode 100644
index def1348..0000000
--- a/src/music_kraken/utils/config/sections/audio.py
+++ /dev/null
@@ -1,154 +0,0 @@
-import logging
-
-from ..base_classes import (
- SingleAttribute,
- FloatAttribute,
- StringAttribute,
- Section,
- Description,
- EmptyLine,
- BoolAttribute,
- ListAttribute
-)
-from ...enums.album import AlbumType
-from ...exception.config import SettingValueError
-
-# Only the formats with id3 metadata can be used
-# https://www.audioranger.com/audio-formats.php
-# https://web.archive.org/web/20230322234434/https://www.audioranger.com/audio-formats.php
-ID3_2_FILE_FORMATS = frozenset((
- "mp3", "mp2", "mp1", # MPEG-1 ID3.2
- "wav", "wave", "rmi", # RIFF (including WAV) ID3.2
- "aiff", "aif", "aifc", # AIFF ID3.2
- "aac", "aacp", # Raw AAC ID3.2
- "tta", # True Audio ID3.2
-))
-_sorted_id3_2_formats = sorted(ID3_2_FILE_FORMATS)
-
-ID3_1_FILE_FORMATS = frozenset((
- "ape", # Monkey's Audio ID3.1
- "mpc", "mpp", "mp+", # MusePack ID3.1
- "wv", # WavPack ID3.1
- "ofr", "ofs" # OptimFrog ID3.1
-))
-_sorted_id3_1_formats = sorted(ID3_1_FILE_FORMATS)
-
-
-class AudioFormatAttribute(SingleAttribute):
- def validate(self, value: str):
- v = self.value.strip().lower()
- if v not in ID3_1_FILE_FORMATS and v not in ID3_2_FILE_FORMATS:
- raise SettingValueError(
- setting_name=self.name,
- setting_value=value,
- rule="has to be a valid audio format, supporting id3 metadata"
- )
-
- @property
- def object_from_value(self) -> str:
- v = self.value.strip().lower()
- if v in ID3_2_FILE_FORMATS:
- return v
- if v in ID3_1_FILE_FORMATS:
- logging.debug(f"setting audio format to a format that only supports ID3.1: {v}")
- return v
-
- raise ValueError(f"Invalid Audio Format: {v}")
-
-
-class AlbumTypeListAttribute(ListAttribute):
- def validate(self, value: str):
- try:
- AlbumType(value.strip())
- except ValueError:
- raise SettingValueError(
- setting_name=self.name,
- setting_value=value,
- rule="has to be an existing album type"
- )
-
- def single_object_from_element(self, value: str) -> AlbumType:
- return AlbumType(value)
-
-
-class AudioSection(Section):
- def __init__(self):
- self.BITRATE = FloatAttribute(
- name="bitrate",
- description="Streams the audio with given bitrate [kB/s]. "
- "Can't stream with a higher Bitrate, than the audio source provides.",
- value="125"
- )
-
- self.AUDIO_FORMAT = AudioFormatAttribute(name="audio_format", value="mp3", description=f"""
-Music Kraken will stream the audio into this format.
-You can use Audio formats which support ID3.2 and ID3.1,
-but you will have cleaner Metadata using ID3.2.
-ID3.2: {', '.join(_sorted_id3_2_formats)}
-ID3.1: {', '.join(_sorted_id3_1_formats)}
- """.strip())
-
- self.SORT_BY_DATE = BoolAttribute(
- name="sort_by_date",
- description="If this is set to true, it will set the albumsort attribute such that,\n"
- "the albums are sorted by date.",
- value="true"
- )
-
- self.SORT_BY_ALBUM_TYPE = BoolAttribute(
- name="sort_album_by_type",
- description="If this is set to true, it will set the albumsort attribute such that,\n"
- "the albums are put into categories before being sorted.\n"
- "This means for example, the Studio Albums and EP's are always in front of Singles, "
- "and Compilations are in the back.",
- value="true"
- )
-
- self.DOWNLOAD_PATH = StringAttribute(
- name="download_path",
- value="{genre}/{artist}/{album}",
- description="The folder music kraken should put the songs into."
- )
-
- self.DOWNLOAD_FILE = StringAttribute(
- name="download_file",
- value="{song}.{audio_format}",
- description="The filename of the audio file."
- )
-
-
- self.ALBUM_TYPE_BLACKLIST = AlbumTypeListAttribute(
- name="album_type_blacklist",
- description="Music Kraken ignores all albums of those types.\n"
- "Following album types exist in the programm:\n"
- f"{', '.join(album.value for album in AlbumType)}",
- value=[
- AlbumType.COMPILATION_ALBUM.value,
- AlbumType.LIVE_ALBUM.value,
- AlbumType.MIXTAPE.value
- ]
- )
-
- self.attribute_list = [
- self.BITRATE,
- self.AUDIO_FORMAT,
- EmptyLine(),
- self.SORT_BY_DATE,
- self.SORT_BY_ALBUM_TYPE,
- Description("""
-There are multiple fields, you can use for the path and file name:
-- genre
-- label
-- artist
-- album
-- song
-- album_type
- """.strip()),
- self.DOWNLOAD_PATH,
- self.DOWNLOAD_FILE,
- self.ALBUM_TYPE_BLACKLIST,
- ]
- super().__init__()
-
-
-AUDIO_SECTION = AudioSection()
diff --git a/src/music_kraken/utils/config/sections/connection.py b/src/music_kraken/utils/config/sections/connection.py
deleted file mode 100644
index b29ac05..0000000
--- a/src/music_kraken/utils/config/sections/connection.py
+++ /dev/null
@@ -1,157 +0,0 @@
-from urllib.parse import urlparse, ParseResult
-import re
-
-from ..base_classes import Section, FloatAttribute, IntAttribute, BoolAttribute, ListAttribute, StringAttribute
-from ...regex import URL_PATTERN
-from ...exception.config import SettingValueError
-
-
-class ProxAttribute(ListAttribute):
- def single_object_from_element(self, value) -> dict:
- return {
- 'http': value,
- 'https': value,
- 'ftp': value
- }
-
-
-class UrlStringAttribute(StringAttribute):
- def validate(self, value: str):
- v = value.strip()
- url = re.match(URL_PATTERN, v)
- if url is None:
- raise SettingValueError(
- setting_name=self.name,
- setting_value=v,
- rule="has to be a valid url"
- )
-
- @property
- def object_from_value(self) -> ParseResult:
- return urlparse(self.value)
-
-
-class UrlListAttribute(ListAttribute):
- def validate(self, value: str):
- v = value.strip()
- url = re.match(URL_PATTERN, v)
- if url is None:
- raise SettingValueError(
- setting_name=self.name,
- setting_value=v,
- rule="has to be a valid url"
- )
-
- def single_object_from_element(self, value: str):
- return urlparse(value)
-
-
-
-class ConnectionSection(Section):
- def __init__(self):
- self.PROXIES = ProxAttribute(
- name="proxies",
- description="Set your proxies.\n"
- "Must be valid for http, as well as https.",
- value=[]
- )
-
- self.USE_TOR = BoolAttribute(
- name="tor",
- description="Route ALL traffic through Tor.\n"
- "If you use Tor, make sure the Tor browser is installed, and running."
- "I can't guarantee maximum security though!",
- value="false"
- )
- self.TOR_PORT = IntAttribute(
- name="tor_port",
- description="The port, tor is listening. If tor is already working, don't change it.",
- value="9150"
- )
- self.CHUNK_SIZE = IntAttribute(
- name="chunk_size",
- description="Size of the chunks that are streamed.",
- value="1024"
- )
- self.SHOW_DOWNLOAD_ERRORS_THRESHOLD = FloatAttribute(
- name="show_download_errors_threshold",
- description="If the percentage of failed downloads goes over this threshold,\n"
- "all the error messages are shown.",
- value="0.3"
- )
-
- # INVIDIOUS INSTANCES LIST
- self.INVIDIOUS_INSTANCE = UrlStringAttribute(
- name="invidious_instance",
- description="This is an attribute, where you can define the invidious instances,\n"
- "the youtube downloader should use.\n"
- "Here is a list of active ones: https://docs.invidious.io/instances/\n"
- "Instances that use cloudflare or have source code changes could cause issues.\n"
- "Hidden instances (.onion) will only work, when setting 'tor=true'.",
- value="https://yt.artemislena.eu/"
- )
-
- self.PIPED_INSTANCE = UrlStringAttribute(
- name="piped_instance",
- description="This is an attribute, where you can define the pioed instances,\n"
- "the youtube downloader should use.\n"
- "Here is a list of active ones: https://github.com/TeamPiped/Piped/wiki/Instances\n"
- "Instances that use cloudflare or have source code changes could cause issues.\n"
- "Hidden instances (.onion) will only work, when setting 'tor=true'.",
- value="https://pipedapi.kavin.rocks"
- )
-
- self.SLEEP_AFTER_YOUTUBE_403 = FloatAttribute(
- name="sleep_after_youtube_403",
- description="The time to wait, after youtube returned 403 (in seconds)",
- value="20"
- )
-
- self.YOUTUBE_MUSIC_API_KEY = StringAttribute(
- name="youtube_music_api_key",
- description="This is the API key used by YouTube-Music internally.\nDw. if it is empty, Rachel will fetch it automatically for you <333\n(she will also update outdated api keys/those that don't work)",
- value="AIzaSyC9XL3ZjWddXya6X74dJoCTL-WEYFDNX30"
- )
-
- self.YOUTUBE_MUSIC_CLEAN_DATA = BoolAttribute(
- name="youtube_music_clean_data",
- description="If set to true, it exclusively fetches artists/albums/songs, not things like user channels etc.",
- value="true"
- )
-
- self.ALL_YOUTUBE_URLS = UrlListAttribute(
- name="youtube_url",
- description="This is used to detect, if an url is from youtube, or any alternativ frontend.\n"
- "If any instance seems to be missing, run music kraken with the -f flag.",
- value=[
- "https://www.youtube.com/",
- "https://www.youtu.be/",
- "https://redirect.invidious.io/",
- "https://piped.kavin.rocks/"
- ]
- )
-
- self.SPONSOR_BLOCK = BoolAttribute(
- name="use_sponsor_block",
- value="true",
- description="Use sponsor block to remove adds or simmilar from the youtube videos."
- )
-
- self.attribute_list = [
- self.USE_TOR,
- self.TOR_PORT,
- self.CHUNK_SIZE,
- self.SHOW_DOWNLOAD_ERRORS_THRESHOLD,
- self.INVIDIOUS_INSTANCE,
- self.PIPED_INSTANCE,
- self.SLEEP_AFTER_YOUTUBE_403,
- self.YOUTUBE_MUSIC_API_KEY,
- self.YOUTUBE_MUSIC_CLEAN_DATA,
- self.ALL_YOUTUBE_URLS,
- self.SPONSOR_BLOCK
- ]
-
- super().__init__()
-
-
-CONNECTION_SECTION = ConnectionSection()
diff --git a/src/music_kraken/utils/config/sections/logging.py b/src/music_kraken/utils/config/sections/logging.py
deleted file mode 100644
index 17c0969..0000000
--- a/src/music_kraken/utils/config/sections/logging.py
+++ /dev/null
@@ -1,130 +0,0 @@
-import logging
-from typing import Callable
-
-from ..base_classes import SingleAttribute, StringAttribute, Section, Description, EmptyLine
-
-LOG_LEVELS = {
- "CRITICAL": 50,
- "ERROR": 40,
- "WARNING": 30,
- "INFO": 20,
- "DEBUG": 10,
- "NOTSET": 0
-}
-
-
-class LoggerAttribute(SingleAttribute):
- @property
- def object_from_value(self) -> logging.Logger:
- return logging.getLogger(self.value)
-
-
-class LogLevelAttribute(SingleAttribute):
- @property
- def object_from_value(self) -> int:
- """
- gets the numeric value of a log level
- :return:
- """
- if self.value.isnumeric():
- return int(self.value)
-
- v = self.value.strip().upper()
-
- if v not in LOG_LEVELS:
- raise ValueError(
- f"{self.name} can only been either one of the following levels, or an integer:\n"
- f"{';'.join(key for key in LOG_LEVELS)}"
- )
-
- return LOG_LEVELS[v]
-
-
-class LoggingSection(Section):
- def __init__(self):
- self.FORMAT = StringAttribute(
- name="logging_format",
- description="Reference for the logging formats: "
- "https://docs.python.org/3/library/logging.html#logrecord-attributes",
- value=logging.BASIC_FORMAT
- )
- self.LOG_LEVEL = LogLevelAttribute(
- name="log_level",
- description=f"can only been either one of the following levels, or an integer:\n"
- f"{';'.join(key for key in LOG_LEVELS)}",
- value=str(logging.INFO)
- )
-
- self.DOWNLOAD_LOGGER = LoggerAttribute(
- name="download_logger",
- description="The logger for downloading.",
- value="download"
- )
- self.TAGGING_LOGGER = LoggerAttribute(
- name="tagging_logger",
- description="The logger for tagging id3 containers.",
- value="tagging"
- )
- self.CODEX_LOGGER = LoggerAttribute(
- name="codex_logger",
- description="The logger for streaming the audio into an uniform codex.",
- value="codex"
- )
- self.OBJECT_LOGGER = LoggerAttribute(
- name="object_logger",
- description="The logger for creating Data-Objects.",
- value="object"
- )
- self.DATABASE_LOGGER = LoggerAttribute(
- name="database_logger",
- description="The logger for Database operations.",
- value="database"
- )
- self.MUSIFY_LOGGER = LoggerAttribute(
- name="musify_logger",
- description="The logger for the musify scraper.",
- value="musify"
- )
- self.YOUTUBE_LOGGER = LoggerAttribute(
- name="youtube_logger",
- description="The logger for the youtube scraper.",
- value="youtube"
- )
- self.YOUTUBE_MUSIC_LOGGER = LoggerAttribute(
- name="youtube_music_logger",
- description="The logger for the youtube music scraper.\n(The scraper is seperate to the youtube scraper)",
- value="youtube_music"
- )
- self.ENCYCLOPAEDIA_METALLUM_LOGGER = LoggerAttribute(
- name="metal_archives_logger",
- description="The logger for the metal archives scraper.",
- value="metal_archives"
- )
- self.GENIUS_LOGGER = LoggerAttribute(
- name="genius_logger",
- description="The logger for the genius scraper",
- value="genius"
- )
-
- self.attribute_list = [
- Description("Logging settings for the actual logging:"),
- self.FORMAT,
- self.LOG_LEVEL,
- EmptyLine(),
- Description("Just the names for different logger, for different parts of the programm:"),
- self.DOWNLOAD_LOGGER,
- self.TAGGING_LOGGER,
- self.CODEX_LOGGER,
- self.OBJECT_LOGGER,
- self.DATABASE_LOGGER,
- self.MUSIFY_LOGGER,
- self.YOUTUBE_LOGGER,
- self.YOUTUBE_MUSIC_LOGGER,
- self.ENCYCLOPAEDIA_METALLUM_LOGGER,
- self.GENIUS_LOGGER
- ]
-
- super().__init__()
-
-
-LOGGING_SECTION = LoggingSection()
diff --git a/src/music_kraken/utils/config/sections/misc.py b/src/music_kraken/utils/config/sections/misc.py
deleted file mode 100644
index ad8641a..0000000
--- a/src/music_kraken/utils/config/sections/misc.py
+++ /dev/null
@@ -1,72 +0,0 @@
-from ..base_classes import Section, IntAttribute, ListAttribute, BoolAttribute
-
-
-class MiscSection(Section):
- def __init__(self):
- self.HASNT_YET_STARTED = BoolAttribute(
- name="hasnt_yet_started",
- description="If you did already run, and configured everything, this is false.",
- value="true"
- )
-
- self.ENABLE_RESULT_HISTORY = BoolAttribute(
- name="result_history",
- description="If enabled, you can go back to the previous results.\n"
- "The consequence is a higher meory consumption, because every result is saved.",
- value="false"
- )
-
- self.HISTORY_LENGTH = IntAttribute(
- name="history_length",
- description="You can choose how far back you can go in the result history.\n"
- "The further you choose to be able to go back, the higher the memory usage.\n"
- "'-1' removes the Limit entirely.",
- value="8"
- )
-
- self.HAPPY_MESSAGES = ListAttribute(
- name="happy_messages",
- description="Just some nice and wholesome messages.\n"
- "If your mindset has traits of a [file corruption], you might not agree.\n"
- "But anyways... Freedom of thought, so go ahead and change the messages.",
- value=[
- "Support the artist.",
- "Star Me: https://github.com/HeIIow2/music-downloader",
- "🏳️⚧️🏳️⚧️ Trans rights are human rights. 🏳️⚧️🏳️⚧️",
- "🏳️⚧️🏳️⚧️ Trans women are women, trans men are men, and enbies are enbies. 🏳️⚧️🏳️⚧️",
- "🏴☠️🏴☠️ Unite under one flag, fck borders. 🏴☠️🏴☠️",
- "Join my Matrix Space: https://matrix.to/#/#music-kraken:matrix.org",
- "Gotta love the BPJM ;-;",
- "🏳️⚧️🏳️⚧️ Protect trans youth. 🏳️⚧️🏳️⚧️",
- ]
- )
-
- self.MODIFY_GC = BoolAttribute(
- name="modify_gc",
- description="If set to true, it will modify the gc for the sake of performance.\n"
- "This should not drive up ram usage, but if it is, then turn it of.\n"
- "Here a blog post about that matter:\n"
- "https://mkennedy.codes/posts/python-gc-settings-change-this-and-make-your-app-go-20pc-faster/\n"
- "https://web.archive.org/web/20221124122222/https://mkennedy.codes/posts/python-gc-settings-change-this-and-make-your-app-go-20pc-faster/",
- value="true"
- )
-
- self.ID_BITS = IntAttribute(
- name="id_bits",
- description="I really dunno why I even made this a setting.. Modifying this is a REALLY dumb idea.",
- value="64"
- )
-
- self.attribute_list = [
- self.HASNT_YET_STARTED,
- self.ENABLE_RESULT_HISTORY,
- self.HISTORY_LENGTH,
- self.HAPPY_MESSAGES,
- self.MODIFY_GC,
- self.ID_BITS
- ]
-
- super().__init__()
-
-
-MISC_SECTION = MiscSection()
diff --git a/src/music_kraken/utils/config/sections/paths.py b/src/music_kraken/utils/config/sections/paths.py
deleted file mode 100644
index cd35a4b..0000000
--- a/src/music_kraken/utils/config/sections/paths.py
+++ /dev/null
@@ -1,59 +0,0 @@
-from pathlib import Path
-
-from ...path_manager import LOCATIONS
-from ..base_classes import Section, StringAttribute, ListAttribute
-
-
-class PathAttribute(StringAttribute):
- @property
- def object_from_value(self) -> Path:
- return Path(self.value.strip())
-
-
-class PathsSection(Section):
- def __init__(self):
- self.MUSIC_DIRECTORY = PathAttribute(
- name="music_directory",
- description="The directory, all the music will be downloaded to.",
- value=str(LOCATIONS.MUSIC_DIRECTORY)
- )
-
- self.TEMP_DIRECTORY = PathAttribute(
- name="temp_directory",
- description="All temporary stuff is gonna be dumped in this directory.",
- value=str(LOCATIONS.TEMP_DIRECTORY)
- )
-
- self.LOG_PATH = PathAttribute(
- name="log_file",
- description="The path to the logging file",
- value=str(LOCATIONS.get_log_file("download_logs.log"))
- )
-
- self.NOT_A_GENRE_REGEX = ListAttribute(
- name="not_a_genre_regex",
- description="These regular expressions tell music-kraken, which sub-folders of the music-directory\n"
- "it should ignore, and not count to genres",
- value=[
- r'^\.' # is hidden/starts with a "."
- ]
- )
-
- self.FFMPEG_BINARY = PathAttribute(
- name="ffmpeg_binary",
- description="Set the path to the ffmpeg binary.",
- value=str(LOCATIONS.FFMPEG_BIN)
- )
-
- self.attribute_list = [
- self.MUSIC_DIRECTORY,
- self.TEMP_DIRECTORY,
- self.LOG_PATH,
- self.NOT_A_GENRE_REGEX,
- self.FFMPEG_BINARY
- ]
-
- super().__init__()
-
-
-PATHS_SECTION = PathsSection()
diff --git a/src/music_kraken/utils/debug_utils.py b/src/music_kraken/utils/debug_utils.py
deleted file mode 100644
index a13ecb7..0000000
--- a/src/music_kraken/utils/debug_utils.py
+++ /dev/null
@@ -1,18 +0,0 @@
-from pathlib import Path
-import json
-
-from .path_manager import LOCATIONS
-
-
-def dump_to_file(file_name: str, payload: str, is_json: bool = False, exit_after_dump: bool = True):
- path = Path(LOCATIONS.TEMP_DIRECTORY, file_name)
- print(f"Dumping payload to: \"{path}\"")
-
- if is_json:
- payload = json.dumps(json.loads(payload), indent=4)
-
- with path.open("w", encoding="utf-8") as f:
- f.write(payload)
-
- if exit_after_dump:
- exit()
diff --git a/src/music_kraken/utils/enums/__init__.py b/src/music_kraken/utils/enums/__init__.py
deleted file mode 100644
index e69de29..0000000
diff --git a/src/music_kraken/utils/functions.py b/src/music_kraken/utils/functions.py
deleted file mode 100644
index f773213..0000000
--- a/src/music_kraken/utils/functions.py
+++ /dev/null
@@ -1,11 +0,0 @@
-import os
-from datetime import datetime
-
-
-def clear_console():
- os.system('cls' if os.name in ('nt', 'dos') else 'clear')
-
-
-def get_current_millis() -> int:
- dt = datetime.now()
- return int(dt.microsecond / 1_000)
diff --git a/src/music_kraken/utils/object_handeling.py b/src/music_kraken/utils/object_handeling.py
deleted file mode 100644
index 7922603..0000000
--- a/src/music_kraken/utils/object_handeling.py
+++ /dev/null
@@ -1,24 +0,0 @@
-from datetime import date
-
-
-def get_elem_from_obj(current_object, keys: list, after_process=lambda x: x, return_if_none=None):
- current_object = current_object
- for key in keys:
- if key in current_object or (type(key) == int and key < len(current_object)):
- current_object = current_object[key]
- else:
- return return_if_none
- return after_process(current_object)
-
-
-def parse_music_brainz_date(mb_date: str) -> date:
- year = 1
- month = 1
- day = 1
-
- first_release_date = mb_date
- if first_release_date.count("-") == 2:
- year, month, day = [int(i) for i in first_release_date.split("-")]
- elif first_release_date.count("-") == 0 and first_release_date.isdigit():
- year = int(first_release_date)
- return date(year, month, day)
diff --git a/src/music_kraken/utils/path_manager/locations.py b/src/music_kraken/utils/path_manager/locations.py
deleted file mode 100644
index 66953d1..0000000
--- a/src/music_kraken/utils/path_manager/locations.py
+++ /dev/null
@@ -1,31 +0,0 @@
-from pathlib import Path
-import os
-
-import tempfile
-from pyffmpeg import FFmpeg
-
-from .music_directory import get_music_directory
-from .config_directory import get_config_directory
-
-
-class Locations:
- def __init__(self, application_name: os.PathLike = "music-kraken"):
- self.FILE_ENCODING: str = "utf-8"
-
- self.TEMP_DIRECTORY = Path(tempfile.gettempdir(), application_name)
- self.TEMP_DIRECTORY.mkdir(exist_ok=True, parents=True)
-
- self.MUSIC_DIRECTORY = get_music_directory()
-
- self.CONFIG_DIRECTORY = get_config_directory(str(application_name))
- self.CONFIG_DIRECTORY.mkdir(exist_ok=True, parents=True)
- self.CONFIG_FILE = Path(self.CONFIG_DIRECTORY, f"{application_name}.conf")
- self.LEGACY_CONFIG_FILE = Path(self.CONFIG_DIRECTORY, f"{application_name}.conf")
-
- self.FFMPEG_BIN = Path(FFmpeg(enable_log=False).get_ffmpeg_bin())
-
- def get_config_file(self, config_name: str) -> Path:
- return Path(self.CONFIG_DIRECTORY, f"{config_name}.toml")
-
- def get_log_file(self, file_name: os.PathLike) -> Path:
- return Path(self.TEMP_DIRECTORY, file_name)
diff --git a/src/music_kraken/utils/phonetic_compares.py b/src/music_kraken/utils/phonetic_compares.py
deleted file mode 100644
index 65f5deb..0000000
--- a/src/music_kraken/utils/phonetic_compares.py
+++ /dev/null
@@ -1,57 +0,0 @@
-import jellyfish
-import string
-
-TITLE_THRESHOLD_LEVENSHTEIN = 1
-UNIFY_TO = " "
-
-ALLOWED_LENGTH_DISTANCE = 20
-
-
-def unify_punctuation(to_unify: str) -> str:
- for char in string.punctuation:
- to_unify = to_unify.replace(char, UNIFY_TO)
- return to_unify
-
-
-def remove_feature_part_from_track(title: str) -> str:
- if ")" != title[-1]:
- return title
- if "(" not in title:
- return title
-
- return title[:title.index("(")]
-
-
-def modify_title(to_modify: str) -> str:
- to_modify = to_modify.strip()
- to_modify = to_modify.lower()
- to_modify = remove_feature_part_from_track(to_modify)
- to_modify = unify_punctuation(to_modify)
- return to_modify
-
-
-def match_titles(title_1: str, title_2: str):
- title_1, title_2 = modify_title(title_1), modify_title(title_2)
- distance = jellyfish.levenshtein_distance(title_1, title_2)
- return distance > TITLE_THRESHOLD_LEVENSHTEIN, distance
-
-
-def match_artists(artist_1, artist_2: str):
- if type(artist_1) == list:
- distances = []
-
- for artist_1_ in artist_1:
- match, distance = match_titles(artist_1_, artist_2)
- if not match:
- return match, distance
-
- distances.append(distance)
- return True, min(distances)
- return match_titles(artist_1, artist_2)
-
-def match_length(length_1: int | None, length_2: int | None) -> bool:
- # returning true if either one is Null, because if one value is not known,
- # then it shouldn't be an attribute which could reject an audio source
- if length_1 is None or length_2 is None:
- return True
- return abs(length_1 - length_2) <= ALLOWED_LENGTH_DISTANCE
diff --git a/src/music_kraken/utils/regex.py b/src/music_kraken/utils/regex.py
deleted file mode 100644
index d8f58f5..0000000
--- a/src/music_kraken/utils/regex.py
+++ /dev/null
@@ -1,3 +0,0 @@
-URL_PATTERN = r"https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+"
-INT_PATTERN = r"^\d*$"
-FLOAT_PATTERN = r"^[\d|\,|\.]*$"
diff --git a/src/music_kraken/utils/shared.py b/src/music_kraken/utils/shared.py
deleted file mode 100644
index 09e2737..0000000
--- a/src/music_kraken/utils/shared.py
+++ /dev/null
@@ -1,34 +0,0 @@
-import random
-
-from .config import main_settings
-
-DEBUG = False
-DEBUG_YOUTUBE_INITIALIZING = DEBUG and False
-DEBUG_PAGES = DEBUG and False
-
-if DEBUG:
- print("DEBUG ACTIVE")
-
-def get_random_message() -> str:
- return random.choice(main_settings['happy_messages'])
-
-
-ENCODING = "utf-8"
-
-HIGHEST_ID = 2**main_settings['id_bits']
-
-
-HELP_MESSAGE = """
-to search:
-> s: {query or url}
-> s: https://musify.club/release/some-random-release-183028492
-> s: #a {artist} #r {release} #t {track}
-
-to download:
-> d: {option ids or direct url}
-> d: 0, 3, 4
-> d: 1
-> d: https://musify.club/release/some-random-release-183028492
-
-have fun :3
-""".strip()
diff --git a/src/music_kraken/utils/support_classes/__init__.py b/src/music_kraken/utils/support_classes/__init__.py
deleted file mode 100644
index 4a04f30..0000000
--- a/src/music_kraken/utils/support_classes/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .download_result import DownloadResult
-from .query import Query
-from .thread_classes import EndThread, FinishedSearch
diff --git a/src/music_kraken/utils/support_classes/thread_classes.py b/src/music_kraken/utils/support_classes/thread_classes.py
deleted file mode 100644
index 1a17e57..0000000
--- a/src/music_kraken/utils/support_classes/thread_classes.py
+++ /dev/null
@@ -1,12 +0,0 @@
-class EndThread:
- _has_ended: bool = False
-
- def __bool__(self):
- return self._has_ended
-
- def exit(self):
- self._has_ended
-
-class FinishedSearch:
- pass
-
\ No newline at end of file
diff --git a/src/music_kraken_cli.py b/src/music_kraken_cli.py
deleted file mode 100644
index 9c939cf..0000000
--- a/src/music_kraken_cli.py
+++ /dev/null
@@ -1,5 +0,0 @@
-import music_kraken
-
-
-if __name__ == "__main__":
- music_kraken.cli()
diff --git a/src/music_kraken_gtk.py b/src/music_kraken_gtk.py
deleted file mode 100644
index 8626e7e..0000000
--- a/src/music_kraken_gtk.py
+++ /dev/null
@@ -1,4 +0,0 @@
-from music_kraken import gtk_gui
-
-if __name__ == "__main__":
- gtk_gui()
diff --git a/src/musify_search.py b/src/musify_search.py
deleted file mode 100644
index 09fdf5f..0000000
--- a/src/musify_search.py
+++ /dev/null
@@ -1,51 +0,0 @@
-from music_kraken import objects
-from music_kraken.pages import Musify
-
-
-def search():
- results = Musify._raw_search("#a Ghost Bath")
- print(results)
-
-
-def fetch_artist():
- artist = objects.Artist(
- source_list=[objects.Source(objects.SourcePages.MUSIFY, "https://musify.club/artist/psychonaut-4-83193")]
- )
-
- artist = objects.Artist(
- source_list=[objects.Source(objects.SourcePages.MUSIFY, "https://musify.club/artist/ghost-bath-280348/")]
- )
-
- artist = objects.Artist(
- source_list=[objects.Source(objects.SourcePages.MUSIFY, "https://musify.club/artist/lana-del-rey-124788/releases")]
- )
-
- artist: objects.Artist = Musify.fetch_details(artist)
- print(artist.options)
- print(artist.main_album_collection[0].source_collection)
-
-
-def fetch_album():
- album = objects.Album(
- source_list=[objects.Source(objects.SourcePages.MUSIFY,
- "https://musify.club/release/linkin-park-hybrid-theory-2000-188")]
- )
-
- album = objects.Album(
- source_list=[
- objects.Source(objects.SourcePages.MUSIFY, "https://musify.club/release/ghost-bath-self-loather-2021-1554266")
- ]
- )
-
- album: objects.Album = Musify.fetch_details(album)
- print(album.options)
-
- song: objects.Song
- for artist in album.artist_collection:
- print(artist.id, artist.name)
- for song in album.song_collection:
- for artist in song.main_artist_collection:
- print(artist.id, artist.name)
-
-if __name__ == "__main__":
- fetch_artist()
diff --git a/src/tests/__init__.py b/src/tests/__init__.py
deleted file mode 100644
index e69de29..0000000
diff --git a/src/tests/conftest.py b/src/tests/conftest.py
deleted file mode 100644
index 3bf1e84..0000000
--- a/src/tests/conftest.py
+++ /dev/null
@@ -1,5 +0,0 @@
-import os
-import sys
-
-# Add the parent directory of the current file (i.e., the "tests" directory) to sys.path
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
diff --git a/src/tests/test_building_objects.py b/src/tests/test_building_objects.py
deleted file mode 100644
index 8cae30c..0000000
--- a/src/tests/test_building_objects.py
+++ /dev/null
@@ -1,94 +0,0 @@
-from mutagen import id3
-import pycountry
-import unittest
-import sys
-import os
-from pathlib import Path
-
-# Add the parent directory of the src package to the Python module search path
-sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
-from music_kraken import objects
-
-
-class TestSong(unittest.TestCase):
-
- def setUp(self):
- self.album_list = [
- objects.Album(
- title="One Final Action",
- date=objects.ID3Timestamp(year=1986, month=3, day=1),
- language=pycountry.languages.get(alpha_2="en"),
- label_list=[
- objects.Label(name="an album label")
- ],
- source_list=[
- objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
- "https://www.metal-archives.com/albums/I%27m_in_a_Coffin/One_Final_Action/207614")
- ]
- ),
- ]
-
- self.artist_list = []
-
- self.main_artist_list=[
- objects.Artist(
- name="I'm in a coffin",
- source_list=[
- objects.Source(
- objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
- "https://www.metal-archives.com/bands/I%27m_in_a_Coffin/127727"
- )
- ]
- ),
- objects.Artist(name="some_split_artist")
- ]
- feature_artist_list=[
- objects.Artist(
- name="Ruffiction",
- label_list=[
- objects.Label(name="Ruffiction Productions")
- ]
- )
- ]
-
- self.artist_list.extend(self.main_artist_list)
- self.artist_list.extend(feature_artist_list)
-
- self.song = objects.Song(
- genre="HS Core",
- title="Vein Deep in the Solution",
- length=666,
- isrc="US-S1Z-99-00001",
- tracksort=2,
- target_list=[
- objects.Target(file="song.mp3", path="example")
- ],
- lyrics_list=[
- objects.Lyrics(
- text="these are some depressive lyrics", language="en"),
- objects.Lyrics(
- text="Dies sind depressive Lyrics", language="de")
- ],
- source_list=[
- objects.Source(objects.SourcePages.YOUTUBE,
- "https://youtu.be/dfnsdajlhkjhsd"),
- objects.Source(objects.SourcePages.MUSIFY,
- "https://ln.topdf.de/Music-Kraken/")
- ],
- album_list=self.album_list,
- main_artist_list=self.main_artist_list,
- feature_artist_list=feature_artist_list,
- )
-
- self.song.compile()
-
- def test_album(self):
- for artist in self.song.main_artist_collection:
- for artist_album in artist.main_album_collection:
- self.assertIn(artist_album, self.song.album_collection)
-
- def test_artist(self):
- for album in self.song.album_collection:
- for album_artist in album.artist_collection:
- self.assertIn(album_artist, self.song.main_artist_collection)
-
diff --git a/src/tests/test_download.py b/src/tests/test_download.py
deleted file mode 100644
index 412b773..0000000
--- a/src/tests/test_download.py
+++ /dev/null
@@ -1,43 +0,0 @@
-import sys
-import os
-import unittest
-
-# Add the parent directory of the src package to the Python module search path
-sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
-from music_kraken import pages
-from music_kraken.pages import download_center
-from music_kraken.pages.download_center import page_attributes
-
-class TestPageSelection(unittest.TestCase):
- def test_no_shady_pages(self):
- search = download_center.Download(
- exclude_shady=True
- )
-
- for page in search.pages:
- self.assertNotIn(page, page_attributes.SHADY_PAGES)
-
- def test_excluding(self):
- search = download_center.Download(
- exclude_pages={pages.EncyclopaediaMetallum}
- )
-
- for page in search.pages:
- self.assertNotEqual(page, pages.EncyclopaediaMetallum)
-
-
- def test_audio_one(self):
- search = download_center.Download(
- exclude_shady=True
- )
-
- for audio_page in search.audio_pages:
- self.assertIn(audio_page, page_attributes.AUDIO_PAGES)
-
- def test_audio_two(self):
- search = download_center.Download()
-
- for audio_page in search.audio_pages:
- self.assertIn(audio_page, page_attributes.AUDIO_PAGES)
-
-
\ No newline at end of file
diff --git a/src/tests/test_objects.py b/src/tests/test_objects.py
deleted file mode 100644
index 87b4041..0000000
--- a/src/tests/test_objects.py
+++ /dev/null
@@ -1,239 +0,0 @@
-from mutagen import id3
-import pycountry
-import unittest
-import sys
-import os
-from pathlib import Path
-
-# Add the parent directory of the src package to the Python module search path
-sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
-from music_kraken import objects
-
-"""
-Testing the Formatted text is barely possible cuz one false character and it fails.
-Not worth the trouble
-"""
-
-
-class TestSong(unittest.TestCase):
-
- def setUp(self):
- self.song = objects.Song(
- genre="HS Core",
- title="Vein Deep in the Solution",
- length=666,
- isrc="US-S1Z-99-00001",
- tracksort=2,
- target_list=[
- objects.Target(file="song.mp3", path="example")
- ],
- lyrics_list=[
- objects.Lyrics(
- text="these are some depressive lyrics", language="en"),
- objects.Lyrics(
- text="Dies sind depressive Lyrics", language="de")
- ],
- source_list=[
- objects.Source(objects.SourcePages.YOUTUBE,
- "https://youtu.be/dfnsdajlhkjhsd"),
- objects.Source(objects.SourcePages.MUSIFY,
- "https://ln.topdf.de/Music-Kraken/")
- ],
- album_list=[
- objects.Album(
- title="One Final Action",
- date=objects.ID3Timestamp(year=1986, month=3, day=1),
- language=pycountry.languages.get(alpha_2="en"),
- label_list=[
- objects.Label(name="an album label")
- ],
- source_list=[
- objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
- "https://www.metal-archives.com/albums/I%27m_in_a_Coffin/One_Final_Action/207614")
- ]
- ),
- ],
- main_artist_list=[
- objects.Artist(
- name="I'm in a coffin",
- source_list=[
- objects.Source(
- objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
- "https://www.metal-archives.com/bands/I%27m_in_a_Coffin/127727"
- )
- ]
- ),
- objects.Artist(name="some_split_artist")
- ],
- feature_artist_list=[
- objects.Artist(
- name="Ruffiction",
- label_list=[
- objects.Label(name="Ruffiction Productions")
- ]
- )
- ],
- )
-
- def test_song_genre(self):
- self.assertEqual(self.song.genre, "HS Core")
-
- def test_song_title(self):
- self.assertEqual(self.song.title, "Vein Deep in the Solution")
-
- def test_song_length(self):
- self.assertEqual(self.song.length, 666)
-
- def test_song_isrc(self):
- self.assertEqual(self.song.isrc, "US-S1Z-99-00001")
-
- def test_song_tracksort(self):
- self.assertEqual(self.song.tracksort, 2)
-
- def test_song_target(self):
- self.assertEqual(self.song.target_collection[0].file_path, Path("example", "song.mp3"))
-
- def test_song_lyrics(self):
- self.assertEqual(len(self.song.lyrics_collection), 2)
- # the other stuff will be tested in the Lyrics test
-
- def test_song_source(self):
- self.assertEqual(len(self.song.source_collection), 2)
- # again the other stuff will be tested in dedicaded stuff
-
-
-class TestAlbum(unittest.TestCase):
-
- def setUp(self):
- self.album = objects.Album(
- title="One Final Action",
- date=objects.ID3Timestamp(year=1986, month=3, day=1),
- language=pycountry.languages.get(alpha_2="en"),
- label_list=[
- objects.Label(name="an album label")
- ],
- source_list=[
- objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
- "https://www.metal-archives.com/albums/I%27m_in_a_Coffin/One_Final_Action/207614")
- ]
- )
-
- def test_album_title(self):
- self.assertEqual(self.album.title, "One Final Action")
-
- def test_album_date(self):
- self.assertEqual(self.album.date.year, 1986)
- self.assertEqual(self.album.date.month, 3)
- self.assertEqual(self.album.date.day, 1)
-
- def test_album_language(self):
- self.assertEqual(self.album.language.alpha_2, "en")
-
- def test_album_label(self):
- self.assertEqual(self.album.label_collection[0].name, "an album label")
-
- def test_album_source(self):
- sp = self.album.source_collection.get_sources_from_page(objects.SourcePages.ENCYCLOPAEDIA_METALLUM)[0]
-
- self.assertEqual(
- sp.page_enum, objects.SourcePages.ENCYCLOPAEDIA_METALLUM)
- self.assertEqual(
- sp.url, "https://www.metal-archives.com/albums/I%27m_in_a_Coffin/One_Final_Action/207614")
-
-
-class TestCollection(unittest.TestCase):
- def setUp(self):
- self.song_list: objects.song = [
- objects.Song(title="hasskrank"),
- objects.Song(title="HaSSkrank"),
- objects.Song(title="Suicideseason", isrc="uniqueID"),
- objects.Song(title="same isrc different title", isrc="uniqueID")
- ]
- self.unified_titels = set(song.unified_title for song in self.song_list)
-
- self.collection = objects.Collection(
- element_type=objects.Song,
- data=self.song_list
- )
-
- def test_length(self):
- # hasskrank gets merged into HaSSkrank
- self.assertEqual(len(self.collection), 2)
-
- def test_data(self):
- """
- tests if the every unified name existed
- """
- song: objects.Song
- for song in self.collection:
- self.assertIn(song.unified_title, self.unified_titels)
-
- def test_appending(self):
- collection = objects.Collection(
- element_type=objects.Song
- )
-
- res = collection.append(self.song_list[0])
- self.assertEqual(res.was_in_collection, False)
- self.assertEqual(res.current_element, self.song_list[0])
-
- res = collection.append(self.song_list[1])
- self.assertEqual(res.was_in_collection, True)
- self.assertEqual(res.current_element, self.song_list[0])
-
- res = collection.append(self.song_list[2])
- self.assertEqual(res.was_in_collection, False)
- self.assertEqual(res.current_element, self.song_list[2])
-
- res = collection.append(self.song_list[3], merge_into_existing=False)
- self.assertEqual(res.was_in_collection, True)
- self.assertEqual(res.current_element, self.song_list[3])
-
-
-
-
-
-
-
-
-
-class TestLyrics(unittest.TestCase):
- """
- TODO
- I NEED TO REWRITE LYRICS TAKING FORMATTED TEXT INSTEAD OF JUST STRINGS
- """
-
- def setUp(self):
- self.lyrics = objects.Lyrics(
- text="these are some depressive lyrics",
- language=pycountry.languages.get(alpha_2="en"),
- source_list=[
- objects.Source(objects.SourcePages.ENCYCLOPAEDIA_METALLUM,
- "https://www.metal-archives.com/lyrics/I%27m_in_a_Coffin/One_Final_Action/207614"),
- objects.Source(objects.SourcePages.MUSIFY,
- "https://www.musify.com/lyrics/I%27m_in_a_Coffin/One_Final_Action/207614")
- ]
- )
-
- def test_lyrics_text(self):
- self.assertEqual(self.lyrics.text, "these are some depressive lyrics")
-
- def test_lyrics_language(self):
- self.assertEqual(self.lyrics.language.alpha_2, "en")
-
- def test_lyrics_source(self):
- self.assertEqual(len(self.lyrics.source_collection), 2)
-
-
-class TestMetadata(unittest.TestCase):
-
-
- def setUp(self):
- self.title = "some title"
-
- self.song = objects.Song(
- title=self.title
- )
-
- def test_song_metadata(self):
- self.assertEqual(self.song.metadata[objects.ID3Mapping.TITLE], id3.Frames[objects.ID3Mapping.TITLE.value](encoding=3, text=self.title))
\ No newline at end of file
diff --git a/test.db b/test.db
deleted file mode 100644
index b941c19..0000000
Binary files a/test.db and /dev/null differ
diff --git a/version b/version
deleted file mode 100644
index 23aa839..0000000
--- a/version
+++ /dev/null
@@ -1 +0,0 @@
-1.2.2
diff --git a/website/assets/logo_cropped.jpg b/website/assets/logo_cropped.jpg
deleted file mode 100644
index a4f0a94..0000000
Binary files a/website/assets/logo_cropped.jpg and /dev/null differ
diff --git a/website/index.html b/website/index.html
deleted file mode 100644
index eac1a40..0000000
--- a/website/index.html
+++ /dev/null
@@ -1,373 +0,0 @@
-
-
-
-
-
- Music-Kraken
- -Installation
- --# Install it with -pip install music-kraken - -# and simply run it like this: -music-kraken -- -
Quick-Guide
- -- Genre: First, the cli asks you to input a genre you want to download to. The options it gives you (if it gives you any) are all the folders you have in the music directory. You can also just input a new one. -
-- What to download: After that it prompts you for a search. Here are a couple examples how you can search: -
- --> #a <any artist> -searches for the artist <any artist> - -> #a <any artist> #r <any releas> -searches for the release <album> <any release> by the artist <any artist> - -> #r <any release> Me #t <any track> -searches for the track <any track> from the release <any relaese> -- -
- After searching with this syntax, it prompts you with multiple results. You can either choose one of those by inputing its id `int`, or you can search for a new query. -
-- After you chose either an artist, a release group, a release, or a track by its id, download it by inputting the string `ok`. My downloader will download it automatically for you. -
--from music_kraken import cli - -cli() -- -## Search for Metadata - -The whole program takes the data it processes further from the cache, a sqlite database. -So before you can do anything, you will need to fill it with the songs you want to download (*or create song objects manually, but more on that later*). - -For now the base of everything is [musicbrainz][mb], so you need to get the musicbrainz `id` and `type`. The `id` corresponds to either - - an artist - - a release group - - a release - - a recording/track). - -To get this info, you first have to initialize a search object (`music_kraken.MetadataSearch`). - -
-search_object = music_kraken.MetadataSearch() -- -Then you need an initial "text search" to get some options you can choose from. For -this you can either specify artists releases and whatever directly with one of the following functions: - -
-# you can directly specify artist, release group, release or recording/track
-multiple_options = search_object.search_from_text(artist=input("input the name of the artist: "))
-# you can specify a query see the simple integrated cli on how to use the query
-multiple_options = search_object.search_from_query(query=input("input the query: "))
-
-
-Both methods return an instance of `MultipleOptions`, which can be directly converted to a string.
-
--print(multiple_options) -- -After the first "*text search*" you can either again search the same way as before, -or you can further explore one of the options from the previous search. -To explore and select one options from `MultipleOptions`, simply call `MetadataSearch.choose(self, index: int)`. -The index represents the number in the previously returned instance of MultipleOptions. -The selected Option will be selected and can be downloaded in the next step. - -*Thus, this has to be done **after either search_from_text or search_from_query*** - -
-# choosing the best matching band -multiple_options = search_object.choose(0) -# choosing the first ever release group of this band -multiple_options = search_object.choose(1) -# printing out the current options -print(multiple_options) -- -This process can be repeated indefinitely (until you run out of memory). -A search history is kept in the Search instance. You could go back to -the previous search (without any loading time) like this: - -
-multiple_options = search_object.get_previous_options() -- -## Downloading Metadata / Filling up the Cache - -You can download following metadata: - - an artist (the whole discography) - - a release group - - a release - - a track/recording - -If you got an instance of `MetadataSearch`, like I elaborated [previously](#search-for-metadata), downloading every piece of metadata from the currently selected Option is really quite easy. - -
-from music_kraken import fetch_metadata_from_search - -# this is it :) -music_kraken.fetch_metadata_from_search(search_object) -- -If you already know what you want to download you can skip the search instance and simply do the following. - -
-from music_kraken import fetch_metadata - -# might change and break after I add multiple metadata sources which I will - -fetch_metadata(id_=musicbrainz_id, type=metadata_type) -- -The option type is a string (*I'm sorry for not making it an enum I know its a bad pratice*), which can -have following values: - - 'artist' - - 'release_group' - - 'release' - - 'recording' - -**PAY ATTENTION TO TYPOS, IT'S CASE SENSITIVE** - -The musicbrainz id is just the id of the object from musicbrainz. - -After following those steps, it might take a couple seconds/minutes to execute, but then the Cache will be filled. - - -## Cache / Temporary Database - -All the data, the functions that download stuff use, can be gotten from the temporary database / cache. -The cache can be simply used like this: - -
-music_kraken.cache -- -When fetching any song data from the cache, you will get it as Song -object (music_kraken.Song). There are multiple methods -to get different sets of Songs. The names explain the methods pretty -well: - -
-from music_kraken import cache - -# gets a single track specified by the id -cache.get_track_metadata(id: str) - -# gets a list of tracks. -cache.get_tracks_to_download() -cache.get_tracks_without_src() -cache.get_tracks_without_isrc() -cache.get_tracks_without_filepath() -- -The id always is a musicbrainz id and distinct for every track. - -## Setting the Target - -By default the music downloader doesn't know where to save the music file, if downloaded. To set those variables (the directory to save the file in and the filepath), it is enough to run one single command: - -
-from music_kraken import set_target - -# adds file path, file directory and the genre to the database -set_target(genre="some test genre") -- -The concept of genres is too loose, to definitely say, this band exclusively plays this genre, or this song is this genre. This doesn't work manually, this will never work automatically. Thus, I've decided to just use the genre as category, to sort the artists and songs by. Most Music players support that. - -As a result of this decision you will have to pass the genre in this function. - -## Get Audio - -This is most likely the most useful and unique feature of this Project. If the cache is filled, you can get audio sources for the songs you only have the metadata, and download them. This works for most songs. I'd guess for about 97% (?) - -First of you will need a List of song objects `music_kraken.Song`. As [mentioned above](#cache--temporary-database), you could get a list like that from the cache. - -
-# Here is an Example -from music_kraken import ( - cache, - fetch_sources, - fetch_audios -) - -# scanning pages, searching for a download and storing results -fetch_sources(cache.get_tracks_without_src()) - -# downloading all previously fetched sources to previously defined targets -fetch_audios(cache.get_tracks_to_download()) - -- -*Note:* -To download audio two cases have to be met: - 1. [The target](#setting-the-target) has to be set beforehand - 2. The sources have to be fetched beforehand - ---- -
-[
- {
- "id":"Lorna Shore",
- "label":"Lorna Shore",
- "value":"Lorna Shore",
- "category":"Исполнители",
- "image":"https://39s.musify.club/img/68/9561484/25159224.jpg",
- "url":"/artist/lorna-shore-59611"
- },
- {"id":"Immortal","label":"Lorna Shore - Immortal (2020)","value":"Immortal","category":"Релизы","image":"https://39s-a.musify.club/img/70/20335517/52174338.jpg","url":"/release/lorna-shore-immortal-2020-1241300"},
- {"id":"Immortal","label":"Lorna Shore - Immortal","value":"Immortal","category":"Треки","image":"","url":"/track/lorna-shore-immortal-12475071"}
-]
-
-
-This is a shortened example for the response the api gives. The results are very Limited, but it is also very efficient to parse. The steps I take are:
-
-- call the api with the query being the track name
-- parse the json response to an object
-- look at how different the title and artist are on every element from the category `Треки`, translated roughly to track or release.
-- If they match get the download links and cache them.
-
-## Youtube
-
-Herte the **isrc** plays a huge role. You probably know it, when you search on youtube for a song, and the music videos has a long intro or the first result is a live version. I don't want those in my music collection, only if the tracks are like this in the official release. Well how can you get around that?
-
-Turns out if you search for the **isrc** on youtube the results contain the music, like it is on the official release and some japanese meme videos. The tracks I wan't just have the title of the released track, so one can just compare those two.
-
-For searching, as well as for downloading I use the programm `youtube-dl`, which also has a programming interface for python.
-
-There are two bottlenecks with this approach though:
-1. `youtube-dl` is just slow. Actually it has to be, to not get blocked by youtube.
-2. Ofthen musicbrainz just doesn't give the isrc for some songs.
- Installation
- --# Install it with -pip install music-kraken - -# and simply run it like this: -music-kraken -- -
Quick-Guide
- -- Genre: First, the cli asks you to input a genre you want to download to. The options it gives you (if it gives you any) are all the folders you have in the music directory. You can also just input a new one. -
-- What to download: After that it prompts you for a search. Here are a couple examples how you can search: -
- --> #a <any artist> -searches for the artist <any artist> - -> #a <any artist> #r <any releas> -searches for the release <album> <any release> by the artist <any artist> - -> #r <any release> Me #t <any track> -searches for the track <any track> from the release <any relaese> -- -
- After searching with this syntax, it prompts you with multiple results. You can either choose one of those by inputing its id `int`, or you can search for a new query. -
-- After you chose either an artist, a release group, a release, or a track by its id, download it by inputting the string `ok`. My downloader will download it automatically for you. -
\ No newline at end of file